 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to be a Statistician: Learned Estimator for Number of Distinct Values
Feb 06, 2022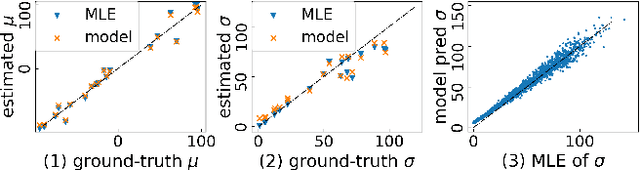

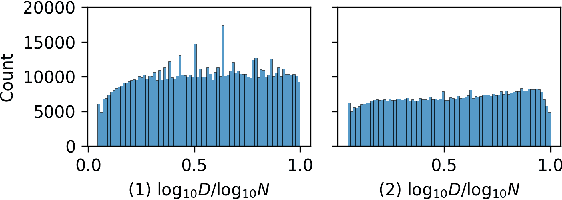
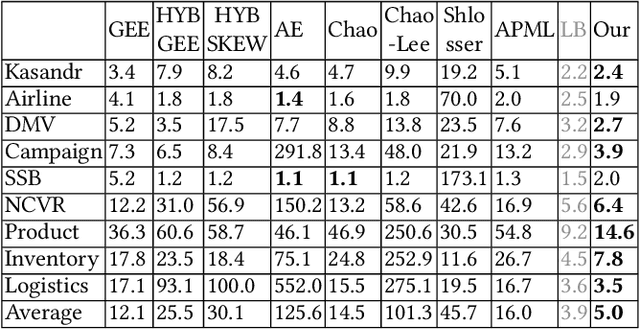
Estimating the number of distinct values (NDV) in a column is useful for many tasks in database systems, such as columnstore compression and data profiling. In this work, we focus on how to derive accurate NDV estimations from random (online/offline) samples. Such efficient estimation is critical for tasks where it is prohibitive to scan the data even once. Existing sample-based estimators typically rely on heuristics or assumptions and do not have robust performance across different datasets as the assumptions on data can easily break. On the other hand, deriving an estimator from a principled formulation such as maximum likelihood estimation is very challenging due to the complex structure of the formulation. We propose to formulate the NDV estimation task in a supervised learning framework, and aim to learn a model as the estimator. To this end, we need to answer several questions: i) how to make the learned model workload agnostic; ii) how to obtain training data; iii) how to perform model training. We derive conditions of the learning framework under which the learned model is workload agnostic, in the sense that the model/estimator can be trained with synthetically generated training data, and then deployed into any data warehouse simply as, e.g., user-defined functions (UDFs), to offer efficient (within microseconds on CPU) and accurate NDV estimations for unseen tables and workloads. We compare the learned estimator with the state-of-the-art sample-based estimators on nine real-world datasets to demonstrate its superior estimation accuracy. We publish our code for training data generation, model training, and the learned estimator online for reproducibility.
* Published at International Conference on Very Large Data Bases (VLDB) 2022