 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Label Aggregation for Weak Supervision
Paper and Code
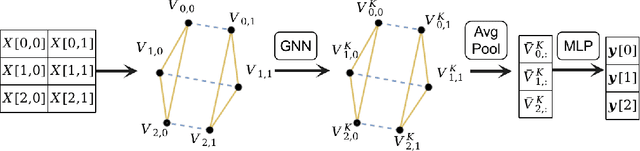
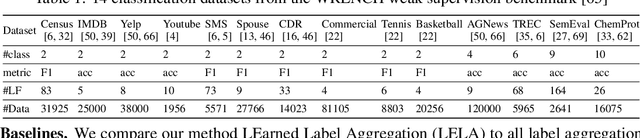
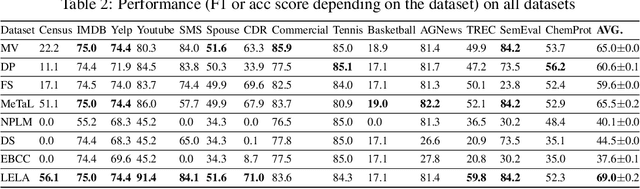
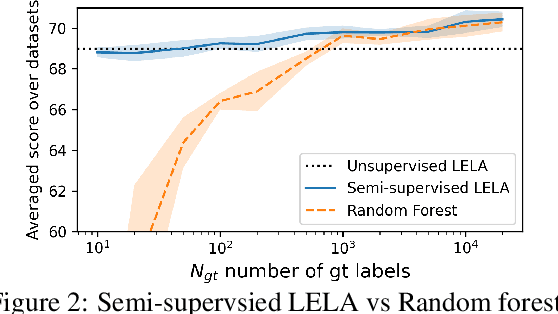
The lack of labeled training data is the bottleneck of machine learning in many applications. To resolve the bottleneck, one promising direction is the data programming approach that aggregates different sources of weak supervision signals to generate labeled data easily. Data programming encodes each weak supervision source with a labeling function (LF), a user-provided program that predicts noisy labels. The quality of the generated labels depends on a label aggregation model that aggregates all noisy labels from all LFs to infer the ground-truth labels. Existing label aggregation methods typically rely on various assumptions and are not robust across datasets, as we will show empirically. We for the first time provide an analytical label aggregation method that makes minimum assumption and is optimal in minimizing a certain form of the averaged prediction error. Since the complexity of the analytical form is exponential, we train a model that learns to be the analytical method. Once trained, the model can be used for any unseen datasets and the model predicts the ground-truth labels for each dataset in a single forward pass in linear time. We show the model can be trained using synthetically generated data and design an effective architecture for the model. On 14 real-world datasets, our model significantly outperforms the best existing methods in both accuracy (by 3.5 points on average) and efficiency (by six times on average).