 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Elo Rating Systems via Markov Chains
Jun 09, 2024



We present a theoretical analysis of the Elo rating system, a popular method for ranking skills of players in an online setting. In particular, we study Elo under the Bradley--Terry--Luce model and, using techniques from Markov chain theory, show that Elo learns the model parameters at a rate competitive with the state of the art. We apply our results to the problem of efficient tournament design and discuss a connection with the fastest-mixing Markov chain problem.
Hermitian matrices for clustering directed graphs: insights and applications
Aug 06, 2019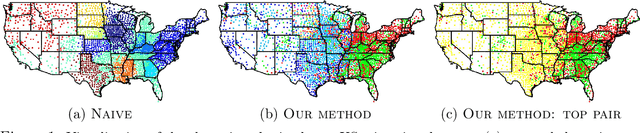
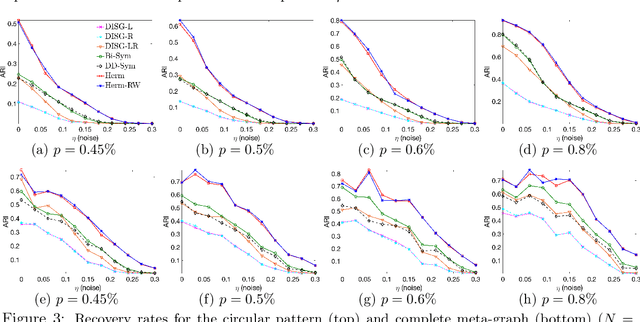
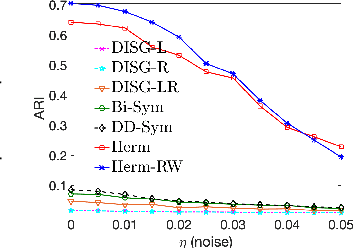
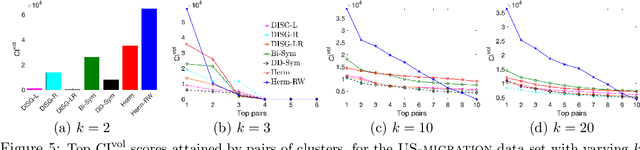
Graph clustering is a basic technique in machine learning, and has widespread applications in different domains. While spectral techniques have been successfully applied for clustering undirected graphs, the performance of spectral clustering algorithms for directed graphs (digraphs) is not in general satisfactory: these algorithms usually require symmetrising the matrix representing a digraph, and typical objective functions for undirected graph clustering do not capture cluster-structures in which the information given by the direction of the edges is crucial. To overcome these downsides, we propose a spectral clustering algorithm based on a complex-valued matrix representation of digraphs. We analyse its theoretical performance on a Stochastic Block Model for digraphs in which the cluster-structure is given not only by variations in edge densities, but also by the direction of the edges. The significance of our work is highlighted on a data set pertaining to internal migration in the United States: while previous spectral clustering algorithms for digraphs can only reveal that people are more likely to move between counties that are geographically close, our approach is able to cluster together counties with a similar socio-economical profile even when they are geographically distant, and illustrates how people tend to move from rural to more urbanised areas.
Distributed Graph Clustering by Load Balancing
Jun 05, 2017Graph clustering is a fundamental computational problem with a number of applications in algorithm design, machine learning, data mining, and analysis of social networks. Over the past decades, researchers have proposed a number of algorithmic design methods for graph clustering. However, most of these methods are based on complicated spectral techniques or convex optimisation, and cannot be applied directly for clustering many networks that occur in practice, whose information is often collected on different sites. Designing a simple and distributed clustering algorithm is of great interest, and has wide applications for processing big datasets. In this paper we present a simple and distributed algorithm for graph clustering: for a wide class of graphs that are characterised by a strong cluster-structure, our algorithm finishes in a poly-logarithmic number of rounds, and recovers a partition of the graph close to an optimal partition. The main component of our algorithm is an application of the random matching model of load balancing, which is a fundamental protocol in distributed computing and has been extensively studied in the past 20 years. Hence, our result highlights an intrinsic and interesting connection between graph clustering and load balancing. At a technical level, we present a purely algebraic result characterising the early behaviours of load balancing processes for graphs exhibiting a cluster-structure. We believe that this result can be further applied to analyse other gossip processes, such as rumour spreading and averaging processes.
Partitioning Well-Clustered Graphs: Spectral Clustering Works!
Jan 31, 2017
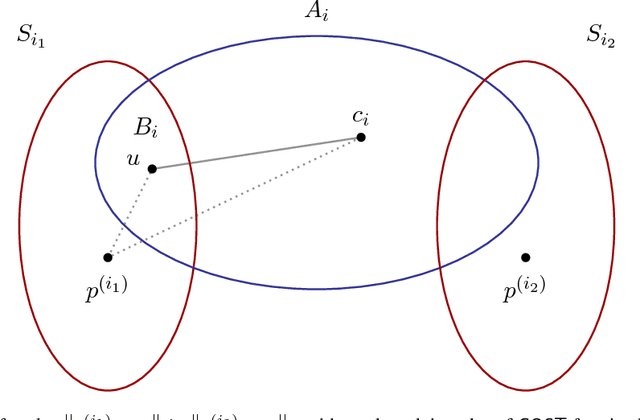
In this paper we study variants of the widely used spectral clustering that partitions a graph into k clusters by (1) embedding the vertices of a graph into a low-dimensional space using the bottom eigenvectors of the Laplacian matrix, and (2) grouping the embedded points into k clusters via k-means algorithms. We show that, for a wide class of graphs, spectral clustering gives a good approximation of the optimal clustering. While this approach was proposed in the early 1990s and has comprehensive applications, prior to our work similar results were known only for graphs generated from stochastic models. We also give a nearly-linear time algorithm for partitioning well-clustered graphs based on computing a matrix exponential and approximate nearest neighbor data structures.