 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenefits and Pitfalls of Reinforcement Learning for Language Model Planning: A Theoretical Perspective
Sep 26, 2025Recent reinforcement learning (RL) methods have substantially enhanced the planning capabilities of Large Language Models (LLMs), yet the theoretical basis for their effectiveness remains elusive. In this work, we investigate RL's benefits and limitations through a tractable graph-based abstraction, focusing on policy gradient (PG) and Q-learning methods. Our theoretical analyses reveal that supervised fine-tuning (SFT) may introduce co-occurrence-based spurious solutions, whereas RL achieves correct planning primarily through exploration, underscoring exploration's role in enabling better generalization. However, we also show that PG suffers from diversity collapse, where output diversity decreases during training and persists even after perfect accuracy is attained. By contrast, Q-learning provides two key advantages: off-policy learning and diversity preservation at convergence. We further demonstrate that careful reward design is necessary to prevent reward hacking in Q-learning. Finally, applying our framework to the real-world planning benchmark Blocksworld, we confirm that these behaviors manifest in practice.
ALPINE: Unveiling the Planning Capability of Autoregressive Learning in Language Models
May 15, 2024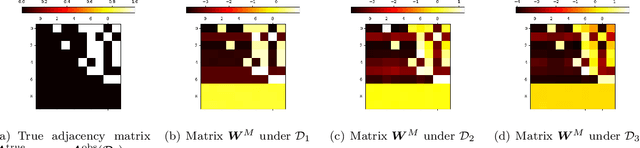
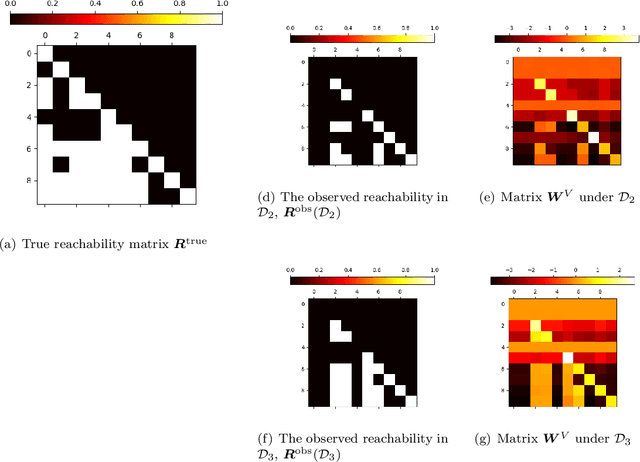
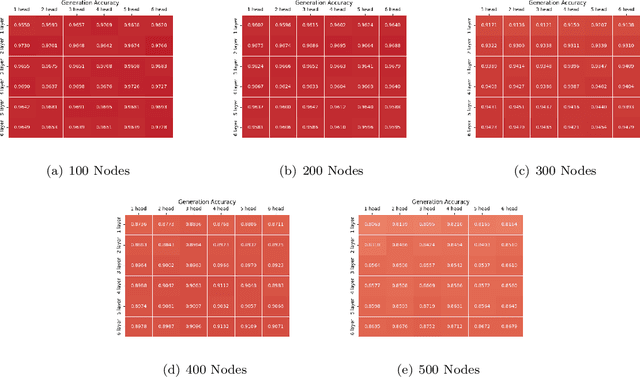
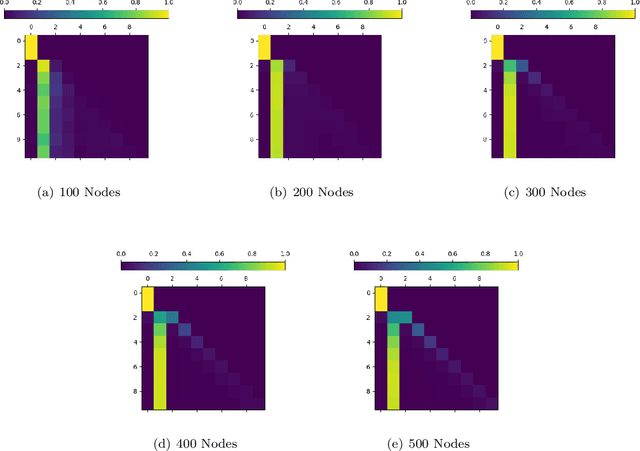
In this paper, we present the findings of our Project ALPINE which stands for ``Autoregressive Learning for Planning In NEtworks." Project ALPINE initiates a theoretical investigation into the development of planning capabilities in Transformer-based language models through their autoregressive learning mechanisms, aiming to identify any potential limitations in their planning abilities. We abstract planning as a network path-finding task where the objective is to generate a valid path from a specified source node to a designated target node. In terms of expressiveness, we show that the Transformer is capable of executing path-finding by embedding the adjacency and reachability matrices within its weights. Our theoretical analysis of the gradient-based learning dynamic of the Transformer reveals that the Transformer is capable of learning both the adjacency matrix and a limited form of the reachability matrix. These theoretical insights are then validated through experiments, which demonstrate that the Transformer indeed learns the adjacency matrix and an incomplete reachability matrix, which aligns with the predictions made in our theoretical analysis. Additionally, when applying our methodology to a real-world planning benchmark, called Blocksworld, our observations remain consistent. Our theoretical and empirical analyses further unveil a potential limitation of Transformer in path-finding: it cannot identify reachability relationships through transitivity, and thus would fail when path concatenation is needed to generate a path. In summary, our findings shed new light on how the internal mechanisms of autoregressive learning enable planning in networks. This study may contribute to our understanding of the general planning capabilities in other related domains.
Learnability is a Compact Property
Feb 15, 2024
Recent work on learning has yielded a striking result: the learnability of various problems can be undecidable, or independent of the standard ZFC axioms of set theory. Furthermore, the learnability of such problems can fail to be a property of finite character: informally, it cannot be detected by examining finite projections of the problem. On the other hand, learning theory abounds with notions of dimension that characterize learning and consider only finite restrictions of the problem, i.e., are properties of finite character. How can these results be reconciled? More precisely, which classes of learning problems are vulnerable to logical undecidability, and which are within the grasp of finite characterizations? We demonstrate that the difficulty of supervised learning with metric losses admits a tight finite characterization. In particular, we prove that the sample complexity of learning a hypothesis class can be detected by examining its finite projections. For realizable and agnostic learning with respect to a wide class of proper loss functions, we demonstrate an exact compactness result: a class is learnable with a given sample complexity precisely when the same is true of all its finite projections. For realizable learning with improper loss functions, we show that exact compactness of sample complexity can fail, and provide matching upper and lower bounds of a factor of 2 on the extent to which such sample complexities can differ. We conjecture that larger gaps are possible for the agnostic case. At the heart of our technical work is a compactness result concerning assignments of variables that maintain a class of functions below a target value, which generalizes Hall's classic matching theorem and may be of independent interest.
Regularization and Optimal Multiclass Learning
Sep 24, 2023

The quintessential learning algorithm of empirical risk minimization (ERM) is known to fail in various settings for which uniform convergence does not characterize learning. It is therefore unsurprising that the practice of machine learning is rife with considerably richer algorithmic techniques for successfully controlling model capacity. Nevertheless, no such technique or principle has broken away from the pack to characterize optimal learning in these more general settings. The purpose of this work is to characterize the role of regularization in perhaps the simplest setting for which ERM fails: multiclass learning with arbitrary label sets. Using one-inclusion graphs (OIGs), we exhibit optimal learning algorithms that dovetail with tried-and-true algorithmic principles: Occam's Razor as embodied by structural risk minimization (SRM), the principle of maximum entropy, and Bayesian reasoning. Most notably, we introduce an optimal learner which relaxes structural risk minimization on two dimensions: it allows the regularization function to be "local" to datapoints, and uses an unsupervised learning stage to learn this regularizer at the outset. We justify these relaxations by showing that they are necessary: removing either dimension fails to yield a near-optimal learner. We also extract from OIGs a combinatorial sequence we term the Hall complexity, which is the first to characterize a problem's transductive error rate exactly. Lastly, we introduce a generalization of OIGs and the transductive learning setting to the agnostic case, where we show that optimal orientations of Hamming graphs -- judged using nodes' outdegrees minus a system of node-dependent credits -- characterize optimal learners exactly. We demonstrate that an agnostic version of the Hall complexity again characterizes error rates exactly, and exhibit an optimal learner using maximum entropy programs.
Quantum Combinatorial Games: Structures and Computational Complexity
Nov 07, 2020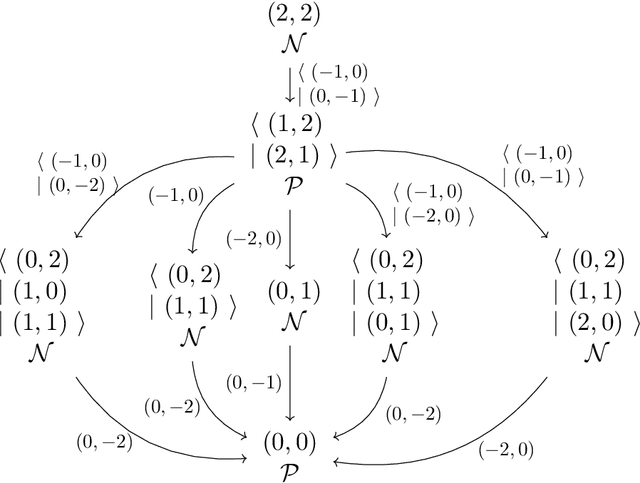
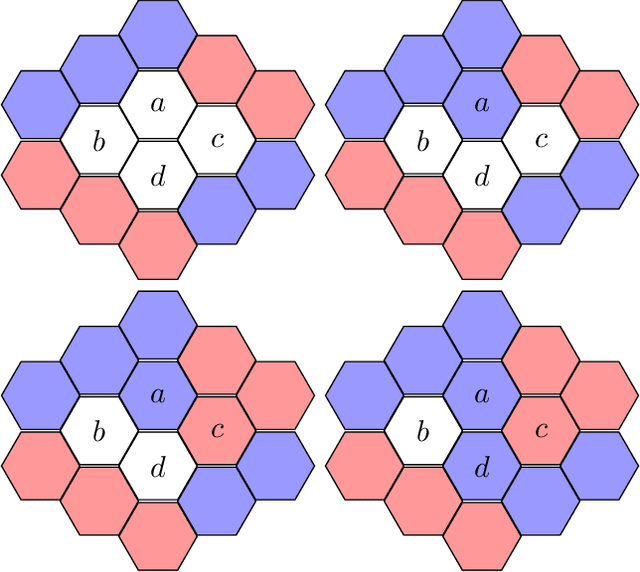
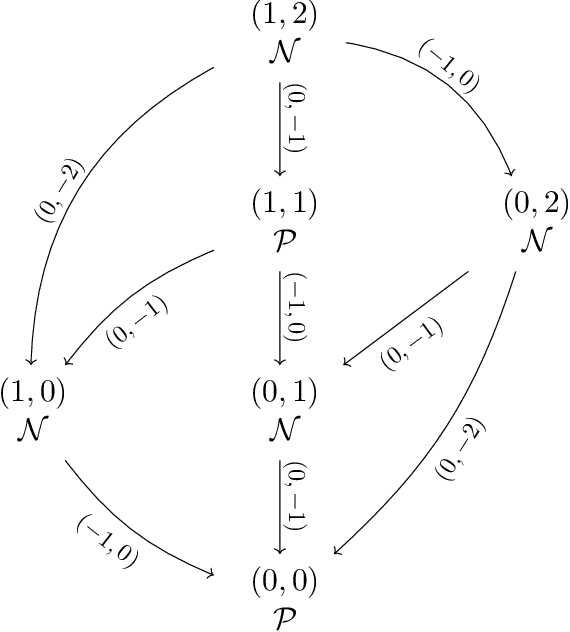
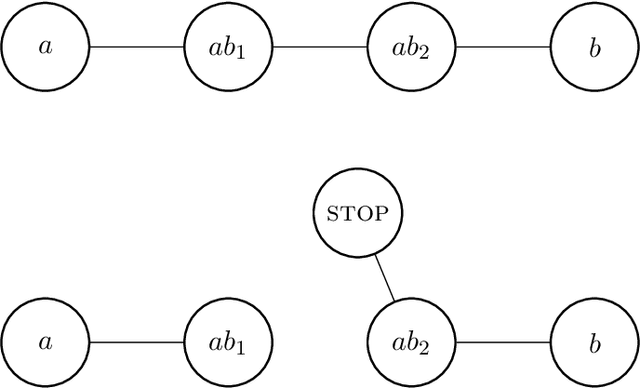
Recently, a standardized framework was proposed for introducing quantum-inspired moves in mathematical games with perfect information and no chance. The beauty of quantum games-succinct in representation, rich in structures, explosive in complexity, dazzling for visualization, and sophisticated for strategic reasoning-has drawn us to play concrete games full of subtleties and to characterize abstract properties pertinent to complexity consequence. Going beyond individual games, we explore the tractability of quantum combinatorial games as whole, and address fundamental questions including: Quantum Leap in Complexity: Are there polynomial-time solvable games whose quantum extensions are intractable? Quantum Collapses in Complexity: Are there PSPACE-complete games whose quantum extensions fall to the lower levels of the polynomial-time hierarchy? Quantumness Matters: How do outcome classes and strategies change under quantum moves? Under what conditions doesn't quantumness matter? PSPACE Barrier for Quantum Leap: Can quantum moves launch PSPACE games into outer polynomial space We show that quantum moves not only enrich the game structure, but also impact their computational complexity. In settling some of these basic questions, we characterize both the powers and limitations of quantum moves as well as the superposition of game configurations that they create. Our constructive proofs-both on the leap of complexity in concrete Quantum Nim and Quantum Undirected Geography and on the continuous collapses, in the quantum setting, of complexity in abstract PSPACE-complete games to each level of the polynomial-time hierarchy-illustrate the striking computational landscape over quantum games and highlight surprising turns with unexpected quantum impact. Our studies also enable us to identify several elegant open questions fundamental to quantum combinatorial game theory (QCGT).
Network Essence: PageRank Completion and Centrality-Conforming Markov Chains
Aug 25, 2017
Ji\v{r}\'i Matou\v{s}ek (1963-2015) had many breakthrough contributions in mathematics and algorithm design. His milestone results are not only profound but also elegant. By going beyond the original objects --- such as Euclidean spaces or linear programs --- Jirka found the essence of the challenging mathematical/algorithmic problems as well as beautiful solutions that were natural to him, but were surprising discoveries to the field. In this short exploration article, I will first share with readers my initial encounter with Jirka and discuss one of his fundamental geometric results from the early 1990s. In the age of social and information networks, I will then turn the discussion from geometric structures to network structures, attempting to take a humble step towards the holy grail of network science, that is to understand the network essence that underlies the observed sparse-and-multifaceted network data. I will discuss a simple result which summarizes some basic algebraic properties of personalized PageRank matrices. Unlike the traditional transitive closure of binary relations, the personalized PageRank matrices take "accumulated Markovian closure" of network data. Some of these algebraic properties are known in various contexts. But I hope featuring them together in a broader context will help to illustrate the desirable properties of this Markovian completion of networks, and motivate systematic developments of a network theory for understanding vast and ubiquitous multifaceted network data.
Spectral Sparsification of Random-Walk Matrix Polynomials
Feb 12, 2015We consider a fundamental algorithmic question in spectral graph theory: Compute a spectral sparsifier of random-walk matrix-polynomial $$L_\alpha(G)=D-\sum_{r=1}^d\alpha_rD(D^{-1}A)^r$$ where $A$ is the adjacency matrix of a weighted, undirected graph, $D$ is the diagonal matrix of weighted degrees, and $\alpha=(\alpha_1...\alpha_d)$ are nonnegative coefficients with $\sum_{r=1}^d\alpha_r=1$. Recall that $D^{-1}A$ is the transition matrix of random walks on the graph. The sparsification of $L_\alpha(G)$ appears to be algorithmically challenging as the matrix power $(D^{-1}A)^r$ is defined by all paths of length $r$, whose precise calculation would be prohibitively expensive. In this paper, we develop the first nearly linear time algorithm for this sparsification problem: For any $G$ with $n$ vertices and $m$ edges, $d$ coefficients $\alpha$, and $\epsilon > 0$, our algorithm runs in time $O(d^2m\log^2n/\epsilon^{2})$ to construct a Laplacian matrix $\tilde{L}=D-\tilde{A}$ with $O(n\log n/\epsilon^{2})$ non-zeros such that $\tilde{L}\approx_{\epsilon}L_\alpha(G)$. Matrix polynomials arise in mathematical analysis of matrix functions as well as numerical solutions of matrix equations. Our work is particularly motivated by the algorithmic problems for speeding up the classic Newton's method in applications such as computing the inverse square-root of the precision matrix of a Gaussian random field, as well as computing the $q$th-root transition (for $q\geq1$) in a time-reversible Markov model. The key algorithmic step for both applications is the construction of a spectral sparsifier of a constant degree random-walk matrix-polynomials introduced by Newton's method. Our algorithm can also be used to build efficient data structures for effective resistances for multi-step time-reversible Markov models, and we anticipate that it could be useful for other tasks in network analysis.
Scalable Parallel Factorizations of SDD Matrices and Efficient Sampling for Gaussian Graphical Models
Oct 20, 2014Motivated by a sampling problem basic to computational statistical inference, we develop a nearly optimal algorithm for a fundamental problem in spectral graph theory and numerical analysis. Given an $n\times n$ SDDM matrix ${\bf \mathbf{M}}$, and a constant $-1 \leq p \leq 1$, our algorithm gives efficient access to a sparse $n\times n$ linear operator $\tilde{\mathbf{C}}$ such that $${\mathbf{M}}^{p} \approx \tilde{\mathbf{C}} \tilde{\mathbf{C}}^\top.$$ The solution is based on factoring ${\bf \mathbf{M}}$ into a product of simple and sparse matrices using squaring and spectral sparsification. For ${\mathbf{M}}$ with $m$ non-zero entries, our algorithm takes work nearly-linear in $m$, and polylogarithmic depth on a parallel machine with $m$ processors. This gives the first sampling algorithm that only requires nearly linear work and $n$ i.i.d. random univariate Gaussian samples to generate i.i.d. random samples for $n$-dimensional Gaussian random fields with SDDM precision matrices. For sampling this natural subclass of Gaussian random fields, it is optimal in the randomness and nearly optimal in the work and parallel complexity. In addition, our sampling algorithm can be directly extended to Gaussian random fields with SDD precision matrices.
Efficient Clustering with Limited Distance Information
Aug 09, 2014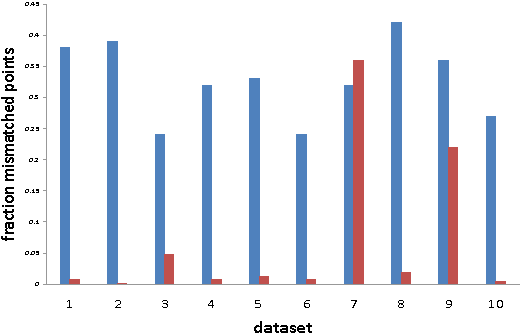
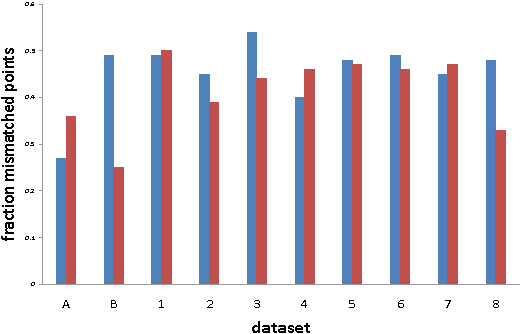
Given a point set S and an unknown metric d on S, we study the problem of efficiently partitioning S into k clusters while querying few distances between the points. In our model we assume that we have access to one versus all queries that given a point s 2 S return the distances between s and all other points. We show that given a natural assumption about the structure of the instance, we can efficiently find an accurate clustering using only O(k) distance queries. We use our algorithm to cluster proteins by sequence similarity. This setting nicely fits our model because we can use a fast sequence database search program to query a sequence against an entire dataset. We conduct an empirical study that shows that even though we query a small fraction of the distances between the points, we produce clusterings that are close to a desired clustering given by manual classification.
Decision trees are PAC-learnable from most product distributions: a smoothed analysis
Dec 04, 2008We consider the problem of PAC-learning decision trees, i.e., learning a decision tree over the n-dimensional hypercube from independent random labeled examples. Despite significant effort, no polynomial-time algorithm is known for learning polynomial-sized decision trees (even trees of any super-constant size), even when examples are assumed to be drawn from the uniform distribution on {0,1}^n. We give an algorithm that learns arbitrary polynomial-sized decision trees for {\em most product distributions}. In particular, consider a random product distribution where the bias of each bit is chosen independently and uniformly from, say, [.49,.51]. Then with high probability over the parameters of the product distribution and the random examples drawn from it, the algorithm will learn any tree. More generally, in the spirit of smoothed analysis, we consider an arbitrary product distribution whose parameters are specified only up to a [-c,c] accuracy (perturbation), for an arbitrarily small positive constant c.