 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Clustering with Limited Distance Information
Aug 09, 2014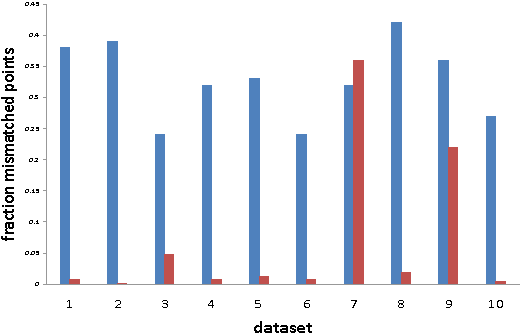
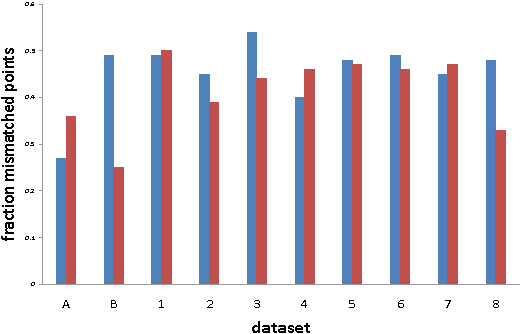
Given a point set S and an unknown metric d on S, we study the problem of efficiently partitioning S into k clusters while querying few distances between the points. In our model we assume that we have access to one versus all queries that given a point s 2 S return the distances between s and all other points. We show that given a natural assumption about the structure of the instance, we can efficiently find an accurate clustering using only O(k) distance queries. We use our algorithm to cluster proteins by sequence similarity. This setting nicely fits our model because we can use a fast sequence database search program to query a sequence against an entire dataset. We conduct an empirical study that shows that even though we query a small fraction of the distances between the points, we produce clusterings that are close to a desired clustering given by manual classification.