 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sustainable AI Economy Needs Data Deals That Work for Generators
Jan 15, 2026We argue that the machine learning value chain is structurally unsustainable due to an economic data processing inequality: each state in the data cycle from inputs to model weights to synthetic outputs refines technical signal but strips economic equity from data generators. We show, by analyzing seventy-three public data deals, that the majority of value accrues to aggregators, with documented creator royalties rounding to zero and widespread opacity of deal terms. This is not just an economic welfare concern: as data and its derivatives become economic assets, the feedback loop that sustains current learning algorithms is at risk. We identify three structural faults - missing provenance, asymmetric bargaining power, and non-dynamic pricing - as the operational machinery of this inequality. In our analysis, we trace these problems along the machine learning value chain and propose an Equitable Data-Value Exchange (EDVEX) Framework to enable a minimal market that benefits all participants. Finally, we outline research directions where our community can make concrete contributions to data deals and contextualize our position with related and orthogonal viewpoints.
Can Small Training Runs Reliably Guide Data Curation? Rethinking Proxy-Model Practice
Dec 30, 2025Data teams at frontier AI companies routinely train small proxy models to make critical decisions about pretraining data recipes for full-scale training runs. However, the community has a limited understanding of whether and when conclusions drawn from small-scale experiments reliably transfer to full-scale model training. In this work, we uncover a subtle yet critical issue in the standard experimental protocol for data recipe assessment: the use of identical small-scale model training configurations across all data recipes in the name of "fair" comparison. We show that the experiment conclusions about data quality can flip with even minor adjustments to training hyperparameters, as the optimal training configuration is inherently data-dependent. Moreover, this fixed-configuration protocol diverges from full-scale model development pipelines, where hyperparameter optimization is a standard step. Consequently, we posit that the objective of data recipe assessment should be to identify the recipe that yields the best performance under data-specific tuning. To mitigate the high cost of hyperparameter tuning, we introduce a simple patch to the evaluation protocol: using reduced learning rates for proxy model training. We show that this approach yields relative performance that strongly correlates with that of fully tuned large-scale LLM pretraining runs. Theoretically, we prove that for random-feature models, this approach preserves the ordering of datasets according to their optimal achievable loss. Empirically, we validate this approach across 23 data recipes covering four critical dimensions of data curation, demonstrating dramatic improvements in the reliability of small-scale experiments.
Effectively Controlling Reasoning Models through Thinking Intervention
Mar 31, 2025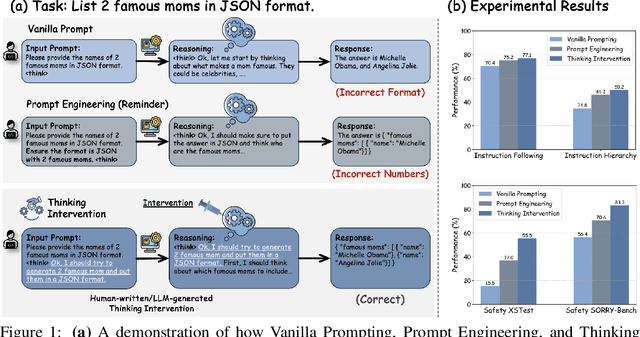
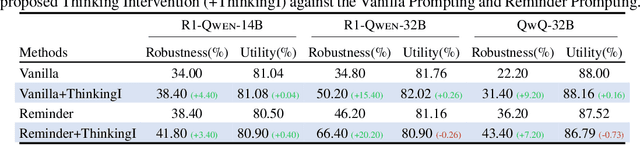

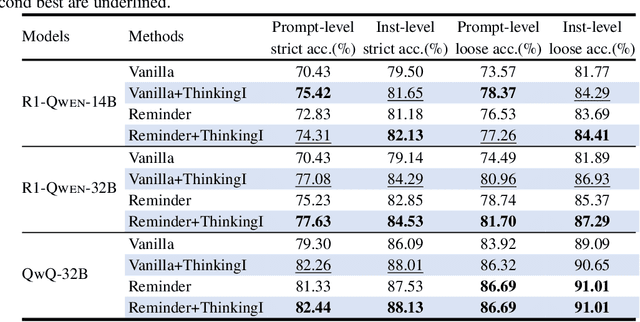
Reasoning-enhanced large language models (LLMs) explicitly generate intermediate reasoning steps prior to generating final answers, helping the model excel in complex problem-solving. In this paper, we demonstrate that this emerging generation framework offers a unique opportunity for more fine-grained control over model behavior. We propose Thinking Intervention, a novel paradigm designed to explicitly guide the internal reasoning processes of LLMs by strategically inserting or revising specific thinking tokens. We conduct comprehensive evaluations across multiple tasks, including instruction following on IFEval, instruction hierarchy on SEP, and safety alignment on XSTest and SORRY-Bench. Our results demonstrate that Thinking Intervention significantly outperforms baseline prompting approaches, achieving up to 6.7% accuracy gains in instruction-following scenarios, 15.4% improvements in reasoning about instruction hierarchies, and a 40.0% increase in refusal rates for unsafe prompts using open-source DeepSeek R1 models. Overall, our work opens a promising new research avenue for controlling reasoning LLMs.
Capturing the Temporal Dependence of Training Data Influence
Dec 12, 2024



Traditional data influence estimation methods, like influence function, assume that learning algorithms are permutation-invariant with respect to training data. However, modern training paradigms, especially for foundation models using stochastic algorithms and multi-stage curricula, are sensitive to data ordering, thus violating this assumption. This mismatch renders influence functions inadequate for answering a critical question in machine learning: How can we capture the dependence of data influence on the optimization trajectory during training? To address this gap, we formalize the concept of trajectory-specific leave-one-out (LOO) influence, which quantifies the impact of removing a data point from a specific iteration during training, accounting for the exact sequence of data encountered and the model's optimization trajectory. However, exactly evaluating the trajectory-specific LOO presents a significant computational challenge. To address this, we propose data value embedding, a novel technique enabling efficient approximation of trajectory-specific LOO. Specifically, we compute a training data embedding that encapsulates the cumulative interactions between data and the evolving model parameters. The LOO can then be efficiently approximated through a simple dot-product between the data value embedding and the gradient of the given test data. As data value embedding captures training data ordering, it offers valuable insights into model training dynamics. In particular, we uncover distinct phases of data influence, revealing that data points in the early and late stages of training exert a greater impact on the final model. These insights translate into actionable strategies for managing the computational overhead of data selection by strategically timing the selection process, potentially opening new avenues in data curation research.
Boosting Alignment for Post-Unlearning Text-to-Image Generative Models
Dec 09, 2024

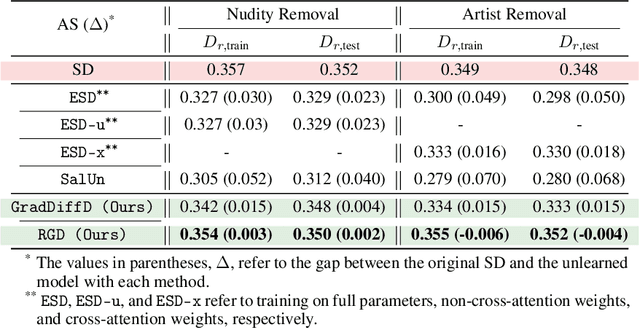

Large-scale generative models have shown impressive image-generation capabilities, propelled by massive data. However, this often inadvertently leads to the generation of harmful or inappropriate content and raises copyright concerns. Driven by these concerns, machine unlearning has become crucial to effectively purge undesirable knowledge from models. While existing literature has studied various unlearning techniques, these often suffer from either poor unlearning quality or degradation in text-image alignment after unlearning, due to the competitive nature of these objectives. To address these challenges, we propose a framework that seeks an optimal model update at each unlearning iteration, ensuring monotonic improvement on both objectives. We further derive the characterization of such an update. In addition, we design procedures to strategically diversify the unlearning and remaining datasets to boost performance improvement. Our evaluation demonstrates that our method effectively removes target classes from recent diffusion-based generative models and concepts from stable diffusion models while maintaining close alignment with the models' original trained states, thus outperforming state-of-the-art baselines. Our code will be made available at \url{https://github.com/reds-lab/Restricted_gradient_diversity_unlearning.git}.
A Survey on Data Markets
Nov 09, 2024



Data is the new oil of the 21st century. The growing trend of trading data for greater welfare has led to the emergence of data markets. A data market is any mechanism whereby the exchange of data products including datasets and data derivatives takes place as a result of data buyers and data sellers being in contact with one another, either directly or through mediating agents. It serves as a coordinating mechanism by which several functions, including the pricing and the distribution of data as the most important ones, interact to make the value of data fully exploited and enhanced. In this article, we present a comprehensive survey of this important and emerging direction from the aspects of data search, data productization, data transaction, data pricing, revenue allocation as well as privacy, security, and trust issues. We also investigate the government policies and industry status of data markets across different countries and different domains. Finally, we identify the unresolved challenges and discuss possible future directions for the development of data markets.
Data Shapley in One Training Run
Jun 16, 2024



Generative artificial intelligence (AI) systems are trained on large data corpora to generate new pieces of text, images, videos, and other media. There is growing concern that such systems may infringe on the copyright interests of training data contributors. To address the copyright challenges of generative AI, we propose a framework that compensates copyright owners proportionally to their contributions to the creation of AI-generated content. The metric for contributions is quantitatively determined by leveraging the probabilistic nature of modern generative AI models and using techniques from cooperative game theory in economics. This framework enables a platform where AI developers benefit from access to high-quality training data, thus improving model performance. Meanwhile, copyright owners receive fair compensation, driving the continued provision of relevant data for generative model training. Experiments demonstrate that our framework successfully identifies the most relevant data sources used in artwork generation, ensuring a fair and interpretable distribution of revenues among copyright owners.
Rethinking Data Shapley for Data Selection Tasks: Misleads and Merits
May 06, 2024



Data Shapley provides a principled approach to data valuation and plays a crucial role in data-centric machine learning (ML) research. Data selection is considered a standard application of Data Shapley. However, its data selection performance has shown to be inconsistent across settings in the literature. This study aims to deepen our understanding of this phenomenon. We introduce a hypothesis testing framework and show that Data Shapley's performance can be no better than random selection without specific constraints on utility functions. We identify a class of utility functions, monotonically transformed modular functions, within which Data Shapley optimally selects data. Based on this insight, we propose a heuristic for predicting Data Shapley's effectiveness in data selection tasks. Our experiments corroborate these findings, adding new insights into when Data Shapley may or may not succeed.
An Economic Solution to Copyright Challenges of Generative AI
Apr 24, 2024



Generative artificial intelligence (AI) systems are trained on large data corpora to generate new pieces of text, images, videos, and other media. There is growing concern that such systems may infringe on the copyright interests of training data contributors. To address the copyright challenges of generative AI, we propose a framework that compensates copyright owners proportionally to their contributions to the creation of AI-generated content. The metric for contributions is quantitatively determined by leveraging the probabilistic nature of modern generative AI models and using techniques from cooperative game theory in economics. This framework enables a platform where AI developers benefit from access to high-quality training data, thus improving model performance. Meanwhile, copyright owners receive fair compensation, driving the continued provision of relevant data for generative model training. Experiments demonstrate that our framework successfully identifies the most relevant data sources used in artwork generation, ensuring a fair and interpretable distribution of revenues among copyright owners.
Language Models as Science Tutors
Feb 16, 2024



NLP has recently made exciting progress toward training language models (LMs) with strong scientific problem-solving skills. However, model development has not focused on real-life use-cases of LMs for science, including applications in education that require processing long scientific documents. To address this, we introduce TutorEval and TutorChat. TutorEval is a diverse question-answering benchmark consisting of questions about long chapters from STEM textbooks, written by experts. TutorEval helps measure real-life usability of LMs as scientific assistants, and it is the first benchmark combining long contexts, free-form generation, and multi-disciplinary scientific knowledge. Moreover, we show that fine-tuning base models with existing dialogue datasets leads to poor performance on TutorEval. Therefore, we create TutorChat, a dataset of 80,000 long synthetic dialogues about textbooks. We use TutorChat to fine-tune Llemma models with 7B and 34B parameters. These LM tutors specialized in math have a 32K-token context window, and they excel at TutorEval while performing strongly on GSM8K and MATH. Our datasets build on open-source materials, and we release our models, data, and evaluations.