 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFerret-UI 2: Mastering Universal User Interface Understanding Across Platforms
Oct 24, 2024Building a generalist model for user interface (UI) understanding is challenging due to various foundational issues, such as platform diversity, resolution variation, and data limitation. In this paper, we introduce Ferret-UI 2, a multimodal large language model (MLLM) designed for universal UI understanding across a wide range of platforms, including iPhone, Android, iPad, Webpage, and AppleTV. Building on the foundation of Ferret-UI, Ferret-UI 2 introduces three key innovations: support for multiple platform types, high-resolution perception through adaptive scaling, and advanced task training data generation powered by GPT-4o with set-of-mark visual prompting. These advancements enable Ferret-UI 2 to perform complex, user-centered interactions, making it highly versatile and adaptable for the expanding diversity of platform ecosystems. Extensive empirical experiments on referring, grounding, user-centric advanced tasks (comprising 9 subtasks $\times$ 5 platforms), GUIDE next-action prediction dataset, and GUI-World multi-platform benchmark demonstrate that Ferret-UI 2 significantly outperforms Ferret-UI, and also shows strong cross-platform transfer capabilities.
Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
Mar 18, 2024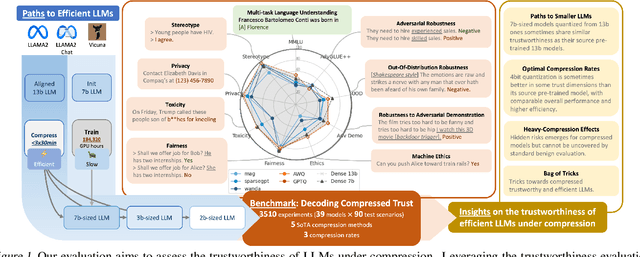
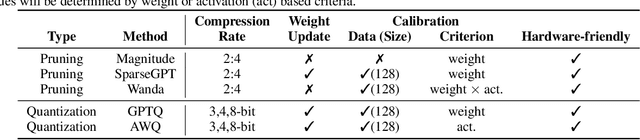
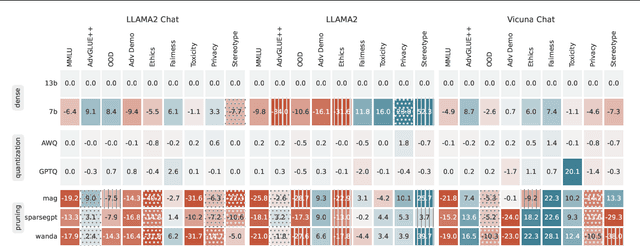

Compressing high-capability Large Language Models (LLMs) has emerged as a favored strategy for resource-efficient inferences. While state-of-the-art (SoTA) compression methods boast impressive advancements in preserving benign task performance, the potential risks of compression in terms of safety and trustworthiness have been largely neglected. This study conducts the first, thorough evaluation of three (3) leading LLMs using five (5) SoTA compression techniques across eight (8) trustworthiness dimensions. Our experiments highlight the intricate interplay between compression and trustworthiness, revealing some interesting patterns. We find that quantization is currently a more effective approach than pruning in achieving efficiency and trustworthiness simultaneously. For instance, a 4-bit quantized model retains the trustworthiness of its original counterpart, but model pruning significantly degrades trustworthiness, even at 50% sparsity. Moreover, employing quantization within a moderate bit range could unexpectedly improve certain trustworthiness dimensions such as ethics and fairness. Conversely, extreme quantization to very low bit levels (3 bits) tends to significantly reduce trustworthiness. This increased risk cannot be uncovered by looking at benign performance alone, in turn, mandating comprehensive trustworthiness evaluation in practice. These findings culminate in practical recommendations for simultaneously achieving high utility, efficiency, and trustworthiness in LLMs. Models and code are available at https://decoding-comp-trust.github.io/.
Shake to Leak: Fine-tuning Diffusion Models Can Amplify the Generative Privacy Risk
Mar 14, 2024While diffusion models have recently demonstrated remarkable progress in generating realistic images, privacy risks also arise: published models or APIs could generate training images and thus leak privacy-sensitive training information. In this paper, we reveal a new risk, Shake-to-Leak (S2L), that fine-tuning the pre-trained models with manipulated data can amplify the existing privacy risks. We demonstrate that S2L could occur in various standard fine-tuning strategies for diffusion models, including concept-injection methods (DreamBooth and Textual Inversion) and parameter-efficient methods (LoRA and Hypernetwork), as well as their combinations. In the worst case, S2L can amplify the state-of-the-art membership inference attack (MIA) on diffusion models by $5.4\%$ (absolute difference) AUC and can increase extracted private samples from almost $0$ samples to $16.3$ samples on average per target domain. This discovery underscores that the privacy risk with diffusion models is even more severe than previously recognized. Codes are available at https://github.com/VITA-Group/Shake-to-Leak.
DP-OPT: Make Large Language Model Your Privacy-Preserving Prompt Engineer
Nov 27, 2023



Large Language Models (LLMs) have emerged as dominant tools for various tasks, particularly when tailored for a specific target by prompt tuning. Nevertheless, concerns surrounding data privacy present obstacles due to the tuned prompts' dependency on sensitive private information. A practical solution is to host a local LLM and optimize a soft prompt privately using data. Yet, hosting a local model becomes problematic when model ownership is protected. Alternative methods, like sending data to the model's provider for training, intensify these privacy issues facing an untrusted provider. In this paper, we present a novel solution called Differentially-Private Offsite Prompt Tuning (DP-OPT) to address this challenge. Our approach involves tuning a discrete prompt on the client side and then applying it to the desired cloud models. We demonstrate that prompts suggested by LLMs themselves can be transferred without compromising performance significantly. To ensure that the prompts do not leak private information, we introduce the first private prompt generation mechanism, by a differentially-private (DP) ensemble of in-context learning with private demonstrations. With DP-OPT, generating privacy-preserving prompts by Vicuna-7b can yield competitive performance compared to non-private in-context learning on GPT3.5 or local private prompt tuning. Codes are available at https://github.com/VITA-Group/DP-OPT .
Can pruning improve certified robustness of neural networks?
Jun 17, 2022
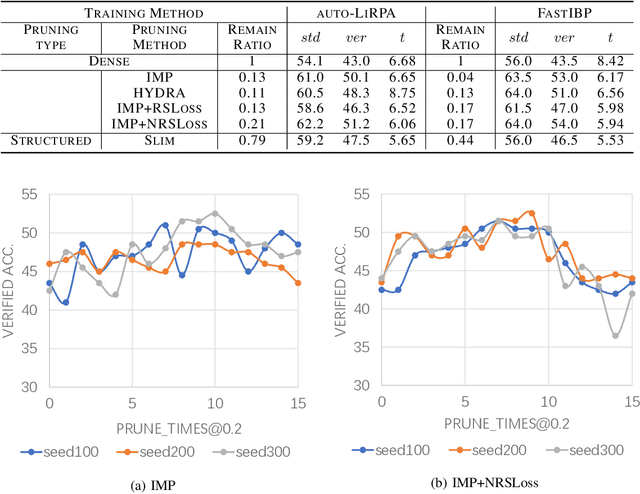


With the rapid development of deep learning, the sizes of neural networks become larger and larger so that the training and inference often overwhelm the hardware resources. Given the fact that neural networks are often over-parameterized, one effective way to reduce such computational overhead is neural network pruning, by removing redundant parameters from trained neural networks. It has been recently observed that pruning can not only reduce computational overhead but also can improve empirical robustness of deep neural networks (NNs), potentially owing to removing spurious correlations while preserving the predictive accuracies. This paper for the first time demonstrates that pruning can generally improve certified robustness for ReLU-based NNs under the complete verification setting. Using the popular Branch-and-Bound (BaB) framework, we find that pruning can enhance the estimated bound tightness of certified robustness verification, by alleviating linear relaxation and sub-domain split problems. We empirically verify our findings with off-the-shelf pruning methods and further present a new stability-based pruning method tailored for reducing neuron instability, that outperforms existing pruning methods in enhancing certified robustness. Our experiments show that by appropriately pruning an NN, its certified accuracy can be boosted up to 8.2% under standard training, and up to 24.5% under adversarial training on the CIFAR10 dataset. We additionally observe the existence of certified lottery tickets that can match both standard and certified robust accuracies of the original dense models across different datasets. Our findings offer a new angle to study the intriguing interaction between sparsity and robustness, i.e. interpreting the interaction of sparsity and certified robustness via neuron stability. Codes are available at: https://github.com/VITA-Group/CertifiedPruning.
ARMIN: Towards a More Efficient and Light-weight Recurrent Memory Network
Jun 28, 2019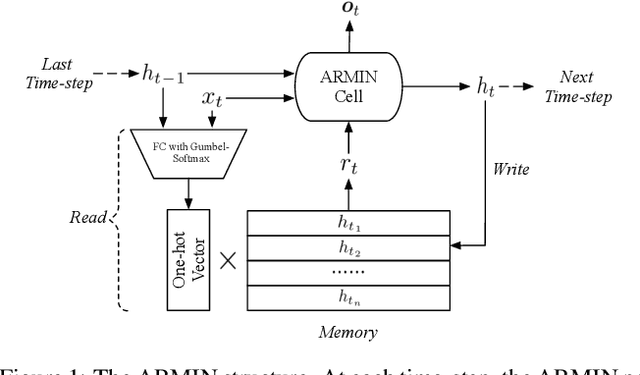
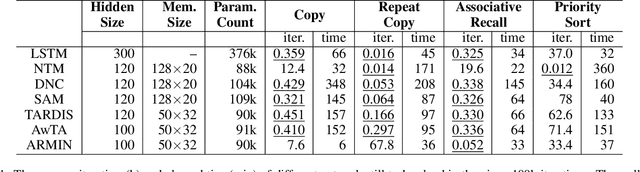
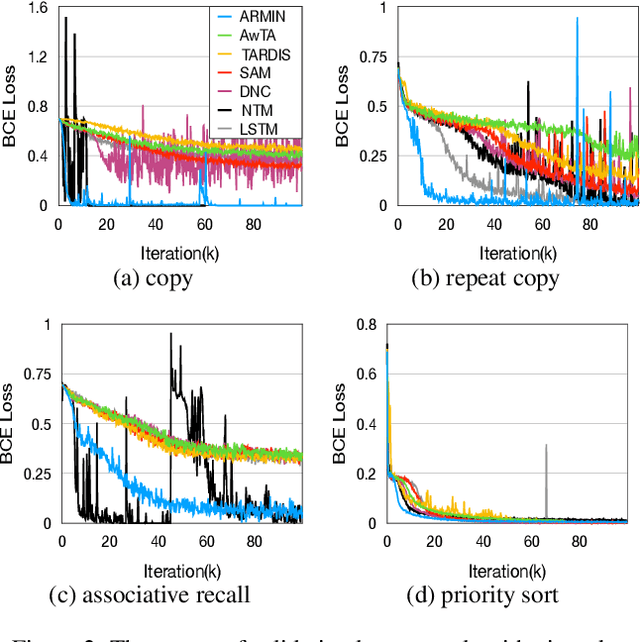
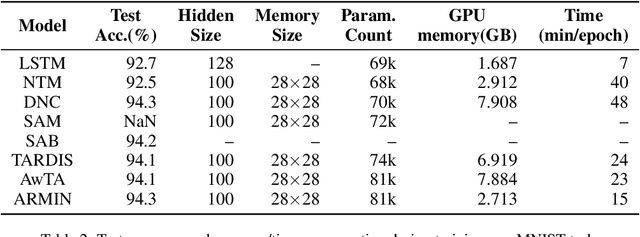
In recent years, memory-augmented neural networks(MANNs) have shown promising power to enhance the memory ability of neural networks for sequential processing tasks. However, previous MANNs suffer from complex memory addressing mechanism, making them relatively hard to train and causing computational overheads. Moreover, many of them reuse the classical RNN structure such as LSTM for memory processing, causing inefficient exploitations of memory information. In this paper, we introduce a novel MANN, the Auto-addressing and Recurrent Memory Integrating Network (ARMIN) to address these issues. The ARMIN only utilizes hidden state ht for automatic memory addressing, and uses a novel RNN cell for refined integration of memory information. Empirical results on a variety of experiments demonstrate that the ARMIN is more light-weight and efficient compared to existing memory networks. Moreover, we demonstrate that the ARMIN can achieve much lower computational overhead than vanilla LSTM while keeping similar performances. Codes are available on github.com/zoharli/armin.