 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Over a Distribution of Hyperparameters for Enhanced Performance and Adaptability on Imbalanced Classification
Oct 04, 2024



Although binary classification is a well-studied problem, training reliable classifiers under severe class imbalance remains a challenge. Recent techniques mitigate the ill effects of imbalance on training by modifying the loss functions or optimization methods. We observe that different hyperparameter values on these loss functions perform better at different recall values. We propose to exploit this fact by training one model over a distribution of hyperparameter values--instead of a single value--via Loss Conditional Training (LCT). Experiments show that training over a distribution of hyperparameters not only approximates the performance of several models but actually improves the overall performance of models on both CIFAR and real medical imaging applications, such as melanoma and diabetic retinopathy detection. Furthermore, training models with LCT is more efficient because some hyperparameter tuning can be conducted after training to meet individual needs without needing to retrain from scratch.
Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
Mar 18, 2024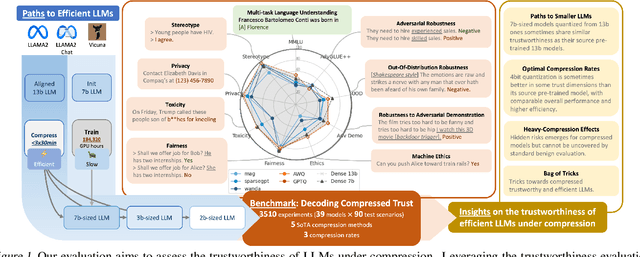
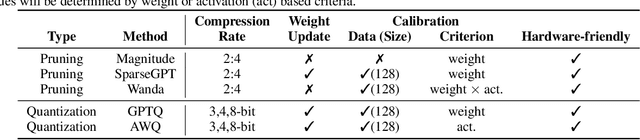
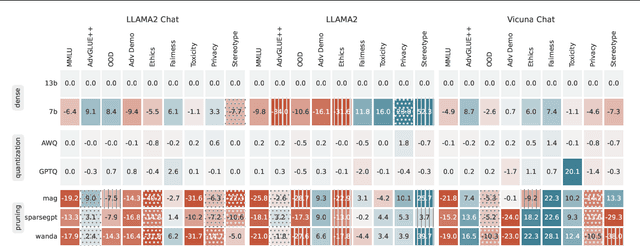

Compressing high-capability Large Language Models (LLMs) has emerged as a favored strategy for resource-efficient inferences. While state-of-the-art (SoTA) compression methods boast impressive advancements in preserving benign task performance, the potential risks of compression in terms of safety and trustworthiness have been largely neglected. This study conducts the first, thorough evaluation of three (3) leading LLMs using five (5) SoTA compression techniques across eight (8) trustworthiness dimensions. Our experiments highlight the intricate interplay between compression and trustworthiness, revealing some interesting patterns. We find that quantization is currently a more effective approach than pruning in achieving efficiency and trustworthiness simultaneously. For instance, a 4-bit quantized model retains the trustworthiness of its original counterpart, but model pruning significantly degrades trustworthiness, even at 50% sparsity. Moreover, employing quantization within a moderate bit range could unexpectedly improve certain trustworthiness dimensions such as ethics and fairness. Conversely, extreme quantization to very low bit levels (3 bits) tends to significantly reduce trustworthiness. This increased risk cannot be uncovered by looking at benign performance alone, in turn, mandating comprehensive trustworthiness evaluation in practice. These findings culminate in practical recommendations for simultaneously achieving high utility, efficiency, and trustworthiness in LLMs. Models and code are available at https://decoding-comp-trust.github.io/.
Optimizing for ROC Curves on Class-Imbalanced Data by Training over a Family of Loss Functions
Feb 08, 2024



Although binary classification is a well-studied problem in computer vision, training reliable classifiers under severe class imbalance remains a challenging problem. Recent work has proposed techniques that mitigate the effects of training under imbalance by modifying the loss functions or optimization methods. While this work has led to significant improvements in the overall accuracy in the multi-class case, we observe that slight changes in hyperparameter values of these methods can result in highly variable performance in terms of Receiver Operating Characteristic (ROC) curves on binary problems with severe imbalance. To reduce the sensitivity to hyperparameter choices and train more general models, we propose training over a family of loss functions, instead of a single loss function. We develop a method for applying Loss Conditional Training (LCT) to an imbalanced classification problem. Extensive experiment results, on both CIFAR and Kaggle competition datasets, show that our method improves model performance and is more robust to hyperparameter choices. Code will be made available at: https://github.com/klieberman/roc_lct.
Neural Image Compression: Generalization, Robustness, and Spectral Biases
Jul 17, 2023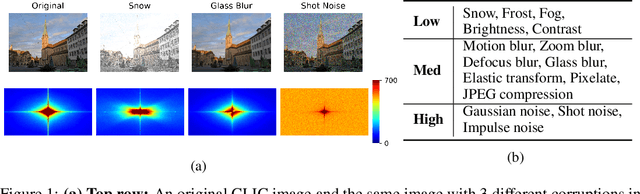
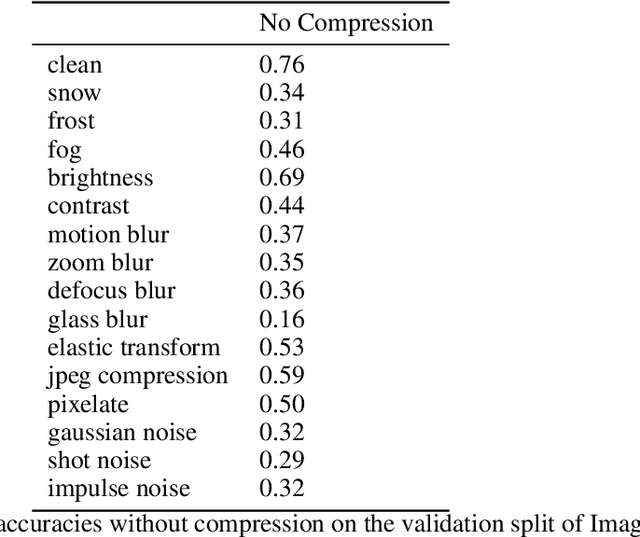
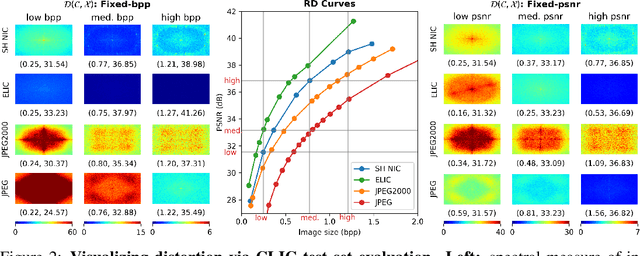
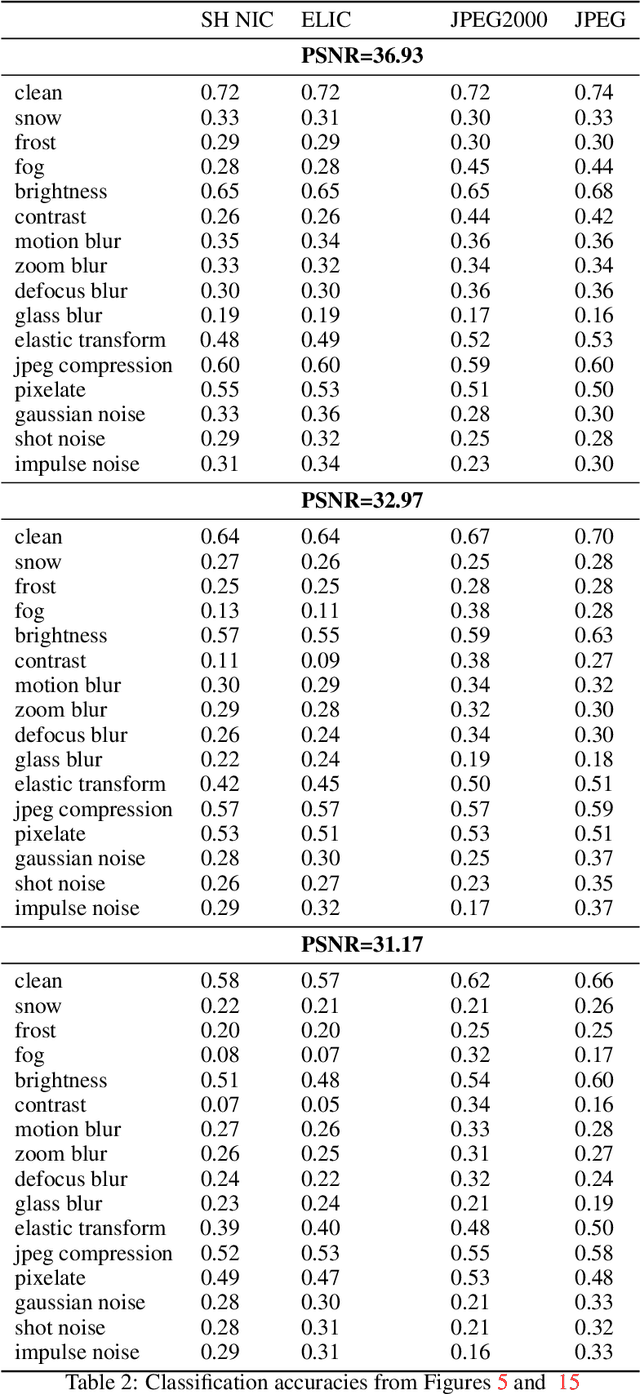
Recent neural image compression (NIC) advances have produced models which are starting to outperform traditional codecs. While this has led to growing excitement about using NIC in real-world applications, the successful adoption of any machine learning system in the wild requires it to generalize (and be robust) to unseen distribution shifts at deployment. Unfortunately, current research lacks comprehensive datasets and informative tools to evaluate and understand NIC performance in real-world settings. To bridge this crucial gap, first, this paper presents a comprehensive benchmark suite to evaluate the out-of-distribution (OOD) performance of image compression methods. Specifically, we provide CLIC-C and Kodak-C by introducing 15 corruptions to popular CLIC and Kodak benchmarks. Next, we propose spectrally inspired inspection tools to gain deeper insight into errors introduced by image compression methods as well as their OOD performance. We then carry out a detailed performance comparison of a classical codec with several NIC variants, revealing intriguing findings that challenge our current understanding of the strengths and limitations of NIC. Finally, we corroborate our empirical findings with theoretical analysis, providing an in-depth view of the OOD performance of NIC and its dependence on the spectral properties of the data. Our benchmarks, spectral inspection tools, and findings provide a crucial bridge to the real-world adoption of NIC. We hope that our work will propel future efforts in designing robust and generalizable NIC methods. Code and data will be made available at https://github.com/klieberman/ood_nic.