 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Splatter: A 3D Gaussian Splatting Model for Quantifying Animal Pose and Appearance
May 23, 2025Accurate and scalable quantification of animal pose and appearance is crucial for studying behavior. Current 3D pose estimation techniques, such as keypoint- and mesh-based techniques, often face challenges including limited representational detail, labor-intensive annotation requirements, and expensive per-frame optimization. These limitations hinder the study of subtle movements and can make large-scale analyses impractical. We propose Pose Splatter, a novel framework leveraging shape carving and 3D Gaussian splatting to model the complete pose and appearance of laboratory animals without prior knowledge of animal geometry, per-frame optimization, or manual annotations. We also propose a novel rotation-invariant visual embedding technique for encoding pose and appearance, designed to be a plug-in replacement for 3D keypoint data in downstream behavioral analyses. Experiments on datasets of mice, rats, and zebra finches show Pose Splatter learns accurate 3D animal geometries. Notably, Pose Splatter represents subtle variations in pose, provides better low-dimensional pose embeddings over state-of-the-art as evaluated by humans, and generalizes to unseen data. By eliminating annotation and per-frame optimization bottlenecks, Pose Splatter enables analysis of large-scale, longitudinal behavior needed to map genotype, neural activity, and micro-behavior at unprecedented resolution.
Training Over a Distribution of Hyperparameters for Enhanced Performance and Adaptability on Imbalanced Classification
Oct 04, 2024



Although binary classification is a well-studied problem, training reliable classifiers under severe class imbalance remains a challenge. Recent techniques mitigate the ill effects of imbalance on training by modifying the loss functions or optimization methods. We observe that different hyperparameter values on these loss functions perform better at different recall values. We propose to exploit this fact by training one model over a distribution of hyperparameter values--instead of a single value--via Loss Conditional Training (LCT). Experiments show that training over a distribution of hyperparameters not only approximates the performance of several models but actually improves the overall performance of models on both CIFAR and real medical imaging applications, such as melanoma and diabetic retinopathy detection. Furthermore, training models with LCT is more efficient because some hyperparameter tuning can be conducted after training to meet individual needs without needing to retrain from scratch.
Optimizing for ROC Curves on Class-Imbalanced Data by Training over a Family of Loss Functions
Feb 08, 2024



Although binary classification is a well-studied problem in computer vision, training reliable classifiers under severe class imbalance remains a challenging problem. Recent work has proposed techniques that mitigate the effects of training under imbalance by modifying the loss functions or optimization methods. While this work has led to significant improvements in the overall accuracy in the multi-class case, we observe that slight changes in hyperparameter values of these methods can result in highly variable performance in terms of Receiver Operating Characteristic (ROC) curves on binary problems with severe imbalance. To reduce the sensitivity to hyperparameter choices and train more general models, we propose training over a family of loss functions, instead of a single loss function. We develop a method for applying Loss Conditional Training (LCT) to an imbalanced classification problem. Extensive experiment results, on both CIFAR and Kaggle competition datasets, show that our method improves model performance and is more robust to hyperparameter choices. Code will be made available at: https://github.com/klieberman/roc_lct.
RandMSAugment: A Mixed-Sample Augmentation for Limited-Data Scenarios
Nov 25, 2023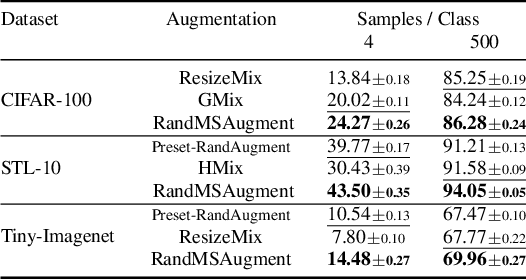
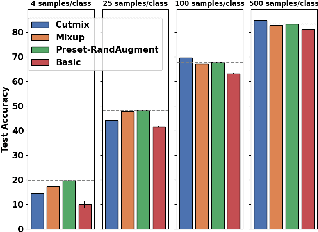
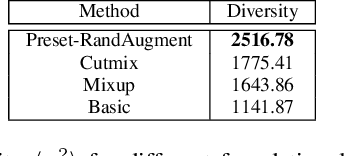
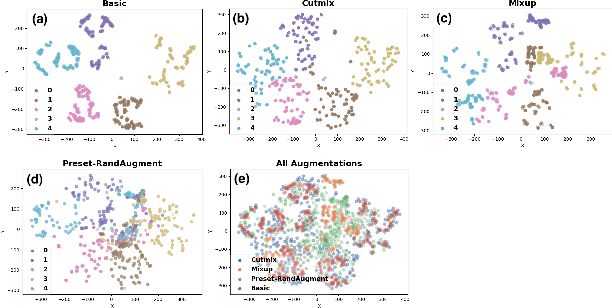
The high costs of annotating large datasets suggests a need for effectively training CNNs with limited data, and data augmentation is a promising direction. We study foundational augmentation techniques, including Mixed Sample Data Augmentations (MSDAs) and a no-parameter variant of RandAugment termed Preset-RandAugment, in the fully supervised scenario. We observe that Preset-RandAugment excels in limited-data contexts while MSDAs are moderately effective. We show that low-level feature transforms play a pivotal role in this performance difference, postulate a new property of augmentations related to their data efficiency, and propose new ways to measure the diversity and realism of augmentations. Building on these insights, we introduce a novel augmentation technique called RandMSAugment that integrates complementary strengths of existing methods. RandMSAugment significantly outperforms the competition on CIFAR-100, STL-10, and Tiny-Imagenet. With very small training sets (4, 25, 100 samples/class), RandMSAugment achieves compelling performance gains between 4.1% and 6.75%. Even with more training data (500 samples/class) we improve performance by 1.03% to 2.47%. RandMSAugment does not require hyperparameter tuning, extra validation data, or cumbersome optimizations.
UFD-PRiME: Unsupervised Joint Learning of Optical Flow and Stereo Depth through Pixel-Level Rigid Motion Estimation
Oct 07, 2023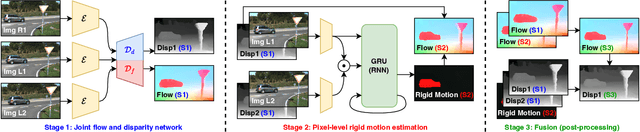
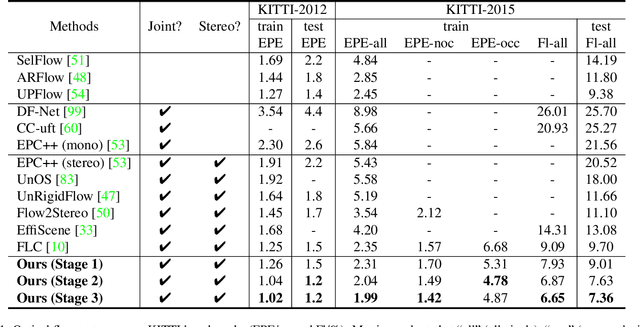
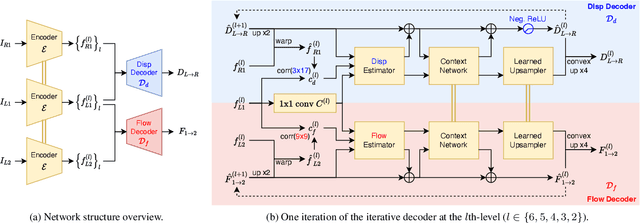
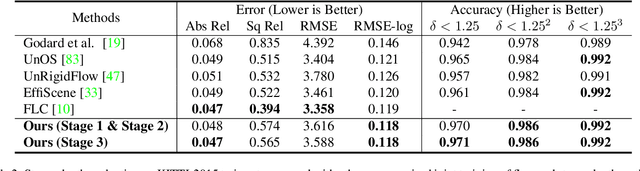
Both optical flow and stereo disparities are image matches and can therefore benefit from joint training. Depth and 3D motion provide geometric rather than photometric information and can further improve optical flow. Accordingly, we design a first network that estimates flow and disparity jointly and is trained without supervision. A second network, trained with optical flow from the first as pseudo-labels, takes disparities from the first network, estimates 3D rigid motion at every pixel, and reconstructs optical flow again. A final stage fuses the outputs from the two networks. In contrast with previous methods that only consider camera motion, our method also estimates the rigid motions of dynamic objects, which are of key interest in applications. This leads to better optical flow with visibly more detailed occlusions and object boundaries as a result. Our unsupervised pipeline achieves 7.36% optical flow error on the KITTI-2015 benchmark and outperforms the previous state-of-the-art 9.38% by a wide margin. It also achieves slightly better or comparable stereo depth results. Code will be made available.
SemARFlow: Injecting Semantics into Unsupervised Optical Flow Estimation for Autonomous Driving
Mar 10, 2023
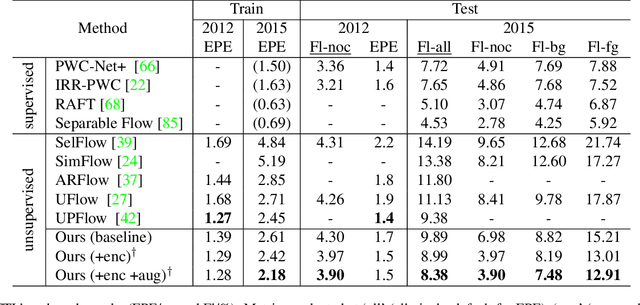


Unsupervised optical flow estimation is especially hard near occlusions and motion boundaries and in low-texture regions. We show that additional information such as semantics and domain knowledge can help better constrain this problem. We introduce SemARFlow, an unsupervised optical flow network designed for autonomous driving data that takes estimated semantic segmentation masks as additional inputs. This additional information is injected into the encoder and into a learned upsampler that refines the flow output. In addition, a simple yet effective semantic augmentation module provides self-supervision when learning flow and its boundaries for vehicles, poles, and sky. Together, these injections of semantic information improve the KITTI-2015 optical flow test error rate from 11.80% to 8.38%. We also show visible improvements around object boundaries as well as a greater ability to generalize across datasets. Code will be made available.
Unsupervised Flow Refinement near Motion Boundaries
Aug 03, 2022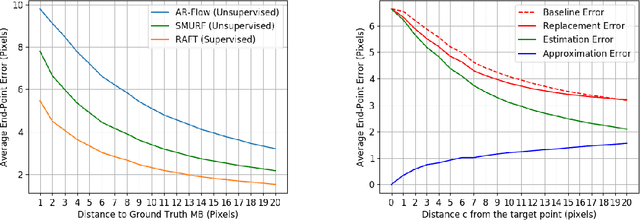

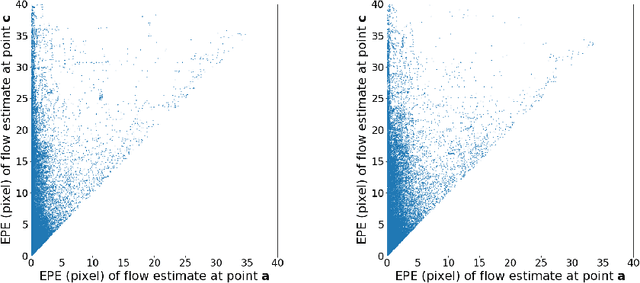

Unsupervised optical flow estimators based on deep learning have attracted increasing attention due to the cost and difficulty of annotating for ground truth. Although performance measured by average End-Point Error (EPE) has improved over the years, flow estimates are still poorer along motion boundaries (MBs), where the flow is not smooth, as is typically assumed, and where features computed by neural networks are contaminated by multiple motions. To improve flow in the unsupervised settings, we design a framework that detects MBs by analyzing visual changes along boundary candidates and replaces motions close to detections with motions farther away. Our proposed algorithm detects boundaries more accurately than a baseline method with the same inputs and can improve estimates from any flow predictor without additional training.
Cross-Attention Transformer for Video Interpolation
Jul 08, 2022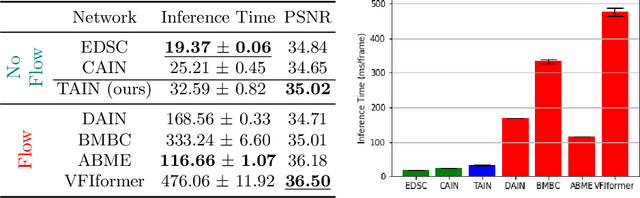
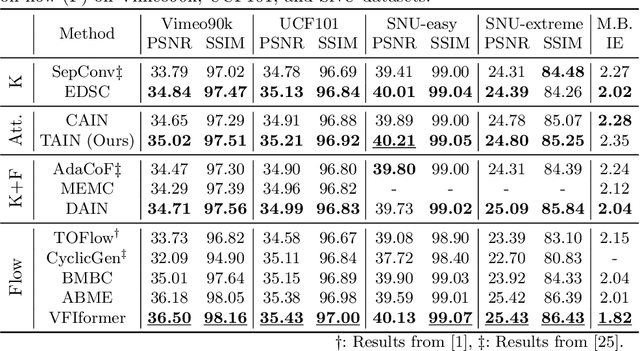
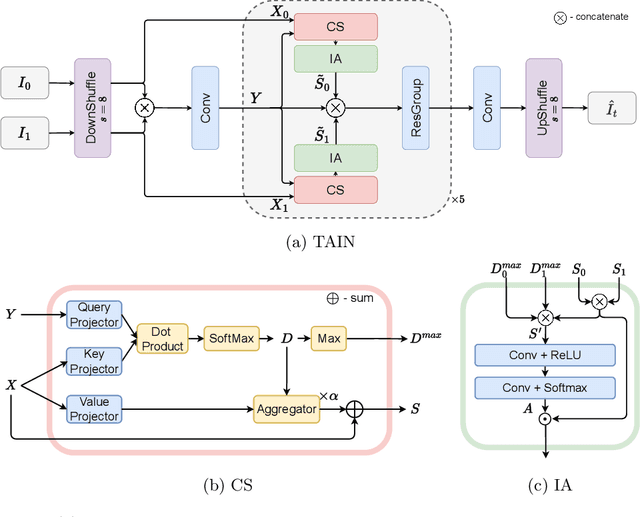
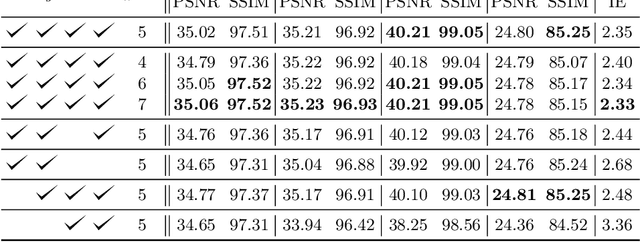
We propose TAIN (Transformers and Attention for video INterpolation), a residual neural network for video interpolation, which aims to interpolate an intermediate frame given two consecutive image frames around it. We first present a novel visual transformer module, named Cross-Similarity (CS), to globally aggregate input image features with similar appearance as those of the predicted interpolated frame. These CS features are then used to refine the interpolated prediction. To account for occlusions in the CS features, we propose an Image Attention (IA) module to allow the network to focus on CS features from one frame over those of the other. Additionally, we augment our training dataset with an occluder patch that moves across frames to improve the network's robustness to occlusions and large motion. Because existing methods yield smooth predictions especially near MBs, we use an additional training loss based on image gradient to yield sharper predictions. TAIN outperforms existing methods that do not require flow estimation and performs comparably to flow-based methods while being computationally efficient in terms of inference time on Vimeo90k, UCF101, and SNU-FILM benchmarks.
Optical Flow Training under Limited Label Budget via Active Learning
Mar 09, 2022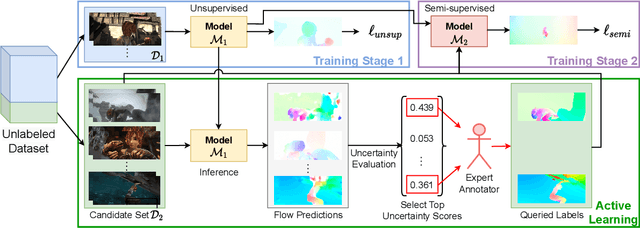
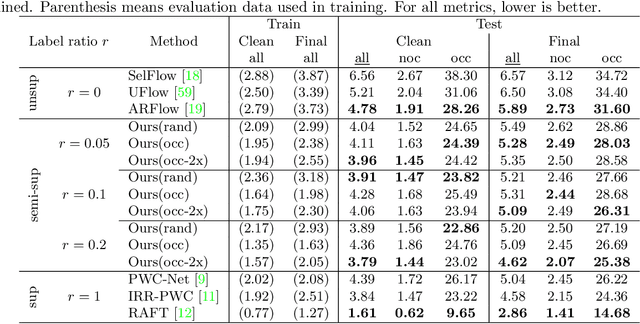
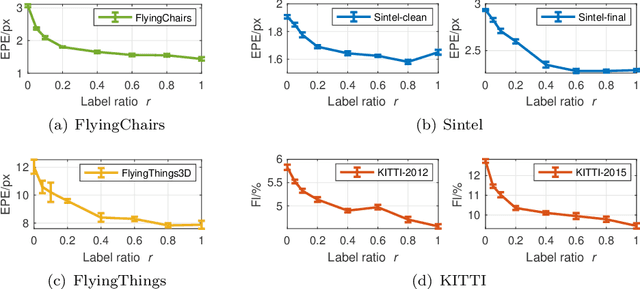
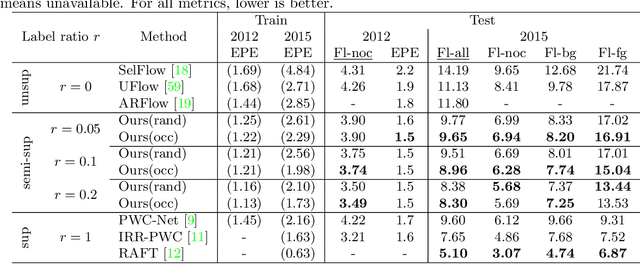
Supervised training of optical flow predictors generally yields better accuracy than unsupervised training. However, the improved performance comes at an often high annotation cost. Semi-supervised training trades off accuracy against annotation cost. We use a simple yet effective semi-supervised training method to show that even a small fraction of labels can improve flow accuracy by a significant margin over unsupervised training. In addition, we propose active learning methods based on simple heuristics to further reduce the number of labels required to achieve the same target accuracy. Our experiments on both synthetic and real optical flow datasets show that our semi-supervised networks generally need around 50% of the labels to achieve close to full-label accuracy, and only around 20% with active learning on Sintel. We also analyze and show insights on the factors that may influence our active learning performance. Code will be made available soon.
Joint Detection of Motion Boundaries and Occlusions
Nov 01, 2021



We propose MONet, a convolutional neural network that jointly detects motion boundaries (MBs) and occlusion regions (Occs) in video both forward and backward in time. Detection is difficult because optical flow is discontinuous along MBs and undefined in Occs, while many flow estimators assume smoothness and a flow defined everywhere. To reason in the two time directions simultaneously, we direct-warp the estimated maps between the two frames. Since appearance mismatches between frames often signal vicinity to MBs or Occs, we construct a cost block that for each feature in one frame records the lowest discrepancy with matching features in a search range. This cost block is two-dimensional, and much less expensive than the four-dimensional cost volumes used in flow analysis. Cost-block features are computed by an encoder, and MB and Occ estimates are computed by a decoder. We found that arranging decoder layers fine-to-coarse, rather than coarse-to-fine, improves performance. MONet outperforms the prior state of the art for both tasks on the Sintel and FlyingChairsOcc benchmarks without any fine-tuning on them.