 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemARFlow: Injecting Semantics into Unsupervised Optical Flow Estimation for Autonomous Driving
Mar 10, 2023
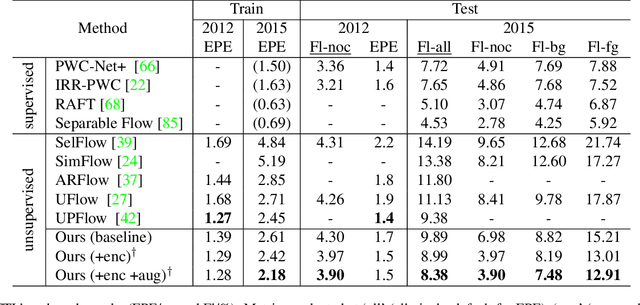


Unsupervised optical flow estimation is especially hard near occlusions and motion boundaries and in low-texture regions. We show that additional information such as semantics and domain knowledge can help better constrain this problem. We introduce SemARFlow, an unsupervised optical flow network designed for autonomous driving data that takes estimated semantic segmentation masks as additional inputs. This additional information is injected into the encoder and into a learned upsampler that refines the flow output. In addition, a simple yet effective semantic augmentation module provides self-supervision when learning flow and its boundaries for vehicles, poles, and sky. Together, these injections of semantic information improve the KITTI-2015 optical flow test error rate from 11.80% to 8.38%. We also show visible improvements around object boundaries as well as a greater ability to generalize across datasets. Code will be made available.
Unsupervised Flow Refinement near Motion Boundaries
Aug 03, 2022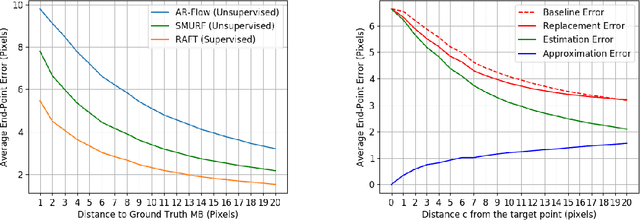

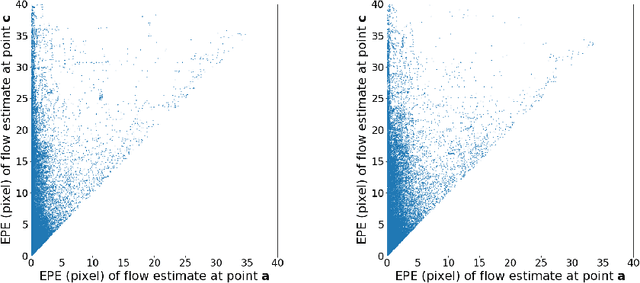

Unsupervised optical flow estimators based on deep learning have attracted increasing attention due to the cost and difficulty of annotating for ground truth. Although performance measured by average End-Point Error (EPE) has improved over the years, flow estimates are still poorer along motion boundaries (MBs), where the flow is not smooth, as is typically assumed, and where features computed by neural networks are contaminated by multiple motions. To improve flow in the unsupervised settings, we design a framework that detects MBs by analyzing visual changes along boundary candidates and replaces motions close to detections with motions farther away. Our proposed algorithm detects boundaries more accurately than a baseline method with the same inputs and can improve estimates from any flow predictor without additional training.
Cross-Attention Transformer for Video Interpolation
Jul 08, 2022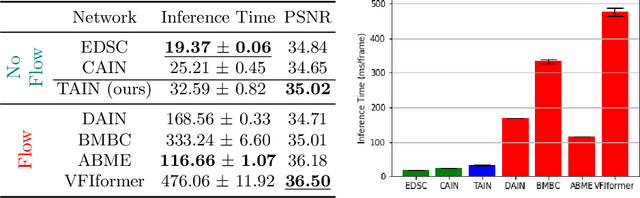
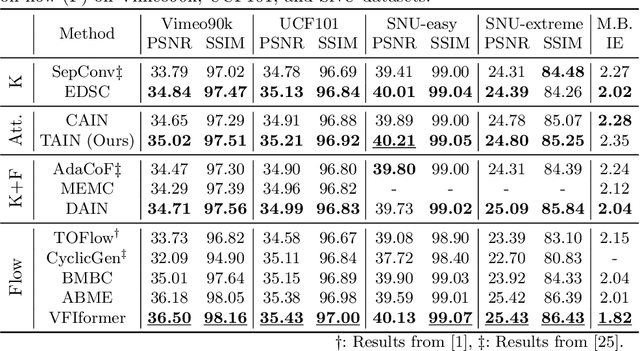
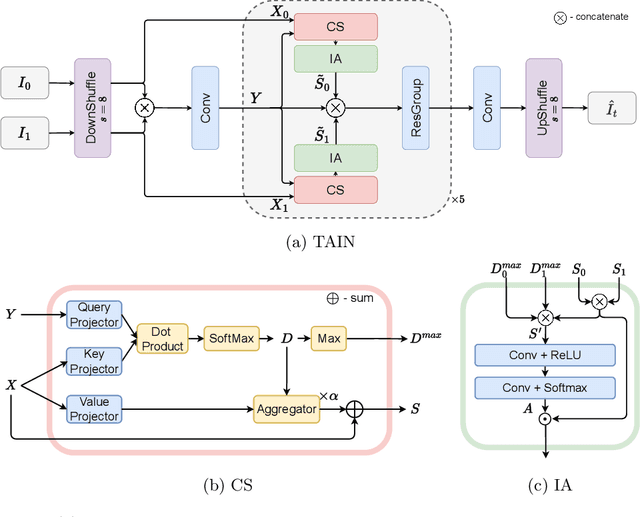
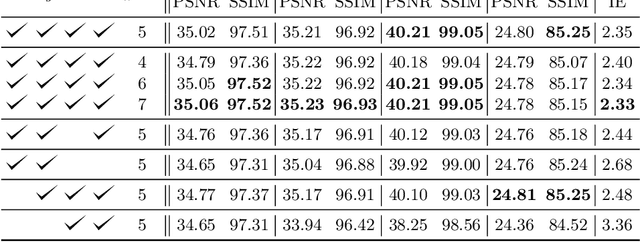
We propose TAIN (Transformers and Attention for video INterpolation), a residual neural network for video interpolation, which aims to interpolate an intermediate frame given two consecutive image frames around it. We first present a novel visual transformer module, named Cross-Similarity (CS), to globally aggregate input image features with similar appearance as those of the predicted interpolated frame. These CS features are then used to refine the interpolated prediction. To account for occlusions in the CS features, we propose an Image Attention (IA) module to allow the network to focus on CS features from one frame over those of the other. Additionally, we augment our training dataset with an occluder patch that moves across frames to improve the network's robustness to occlusions and large motion. Because existing methods yield smooth predictions especially near MBs, we use an additional training loss based on image gradient to yield sharper predictions. TAIN outperforms existing methods that do not require flow estimation and performs comparably to flow-based methods while being computationally efficient in terms of inference time on Vimeo90k, UCF101, and SNU-FILM benchmarks.
TDT: Teaching Detectors to Track without Fully Annotated Videos
May 11, 2022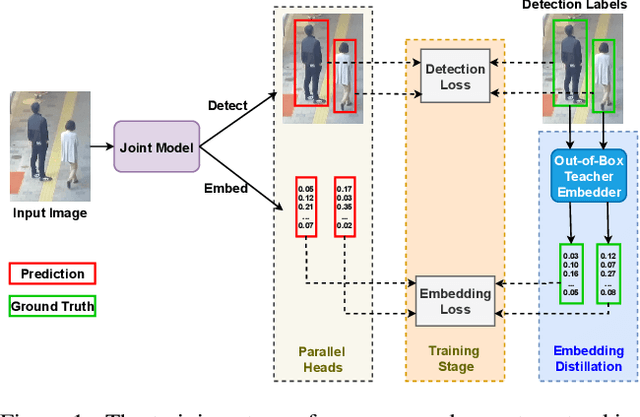

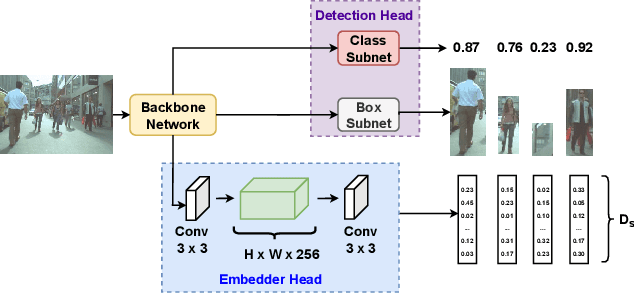
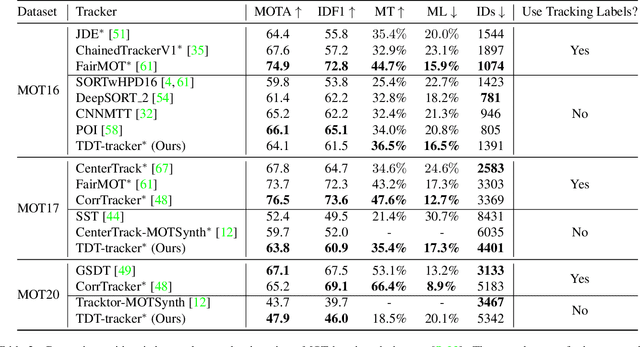
Recently, one-stage trackers that use a joint model to predict both detections and appearance embeddings in one forward pass received much attention and achieved state-of-the-art results on the Multi-Object Tracking (MOT) benchmarks. However, their success depends on the availability of videos that are fully annotated with tracking data, which is expensive and hard to obtain. This can limit the model generalization. In comparison, the two-stage approach, which performs detection and embedding separately, is slower but easier to train as their data are easier to annotate. We propose to combine the best of the two worlds through a data distillation approach. Specifically, we use a teacher embedder, trained on Re-ID datasets, to generate pseudo appearance embedding labels for the detection datasets. Then, we use the augmented dataset to train a detector that is also capable of regressing these pseudo-embeddings in a fully-convolutional fashion. Our proposed one-stage solution matches the two-stage counterpart in quality but is 3 times faster. Even though the teacher embedder has not seen any tracking data during training, our proposed tracker achieves competitive performance with some popular trackers (e.g. JDE) trained with fully labeled tracking data.
Optical Flow Training under Limited Label Budget via Active Learning
Mar 09, 2022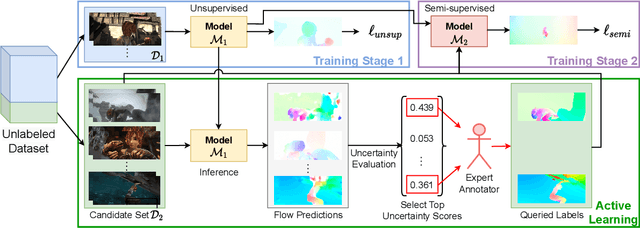
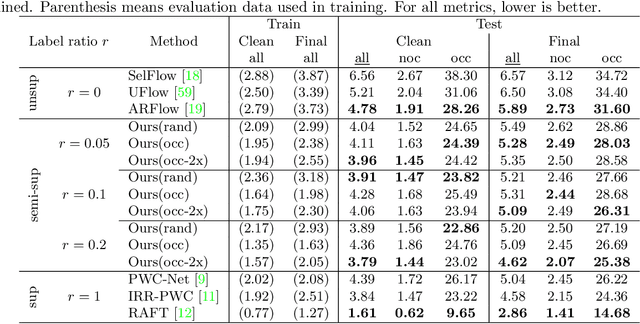
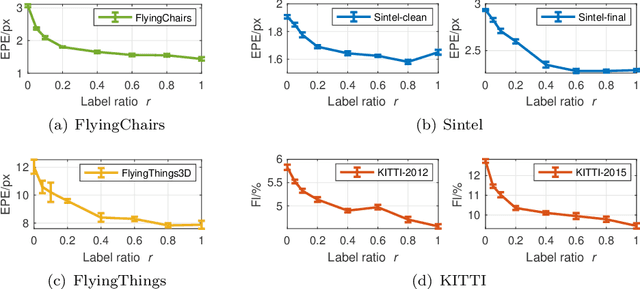
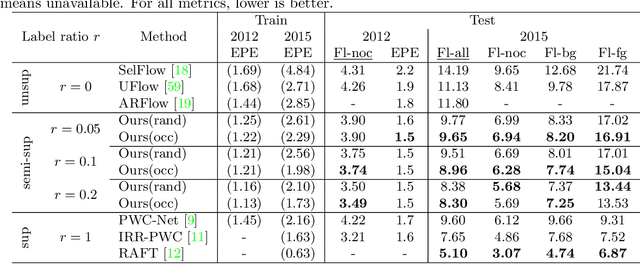
Supervised training of optical flow predictors generally yields better accuracy than unsupervised training. However, the improved performance comes at an often high annotation cost. Semi-supervised training trades off accuracy against annotation cost. We use a simple yet effective semi-supervised training method to show that even a small fraction of labels can improve flow accuracy by a significant margin over unsupervised training. In addition, we propose active learning methods based on simple heuristics to further reduce the number of labels required to achieve the same target accuracy. Our experiments on both synthetic and real optical flow datasets show that our semi-supervised networks generally need around 50% of the labels to achieve close to full-label accuracy, and only around 20% with active learning on Sintel. We also analyze and show insights on the factors that may influence our active learning performance. Code will be made available soon.
Joint Detection of Motion Boundaries and Occlusions
Nov 01, 2021



We propose MONet, a convolutional neural network that jointly detects motion boundaries (MBs) and occlusion regions (Occs) in video both forward and backward in time. Detection is difficult because optical flow is discontinuous along MBs and undefined in Occs, while many flow estimators assume smoothness and a flow defined everywhere. To reason in the two time directions simultaneously, we direct-warp the estimated maps between the two frames. Since appearance mismatches between frames often signal vicinity to MBs or Occs, we construct a cost block that for each feature in one frame records the lowest discrepancy with matching features in a search range. This cost block is two-dimensional, and much less expensive than the four-dimensional cost volumes used in flow analysis. Cost-block features are computed by an encoder, and MB and Occ estimates are computed by a decoder. We found that arranging decoder layers fine-to-coarse, rather than coarse-to-fine, improves performance. MONet outperforms the prior state of the art for both tasks on the Sintel and FlyingChairsOcc benchmarks without any fine-tuning on them.
Identity Connections in Residual Nets Improve Noise Stability
May 27, 2019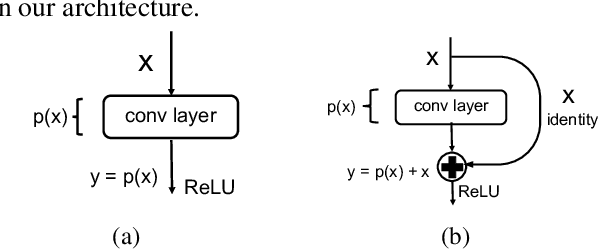
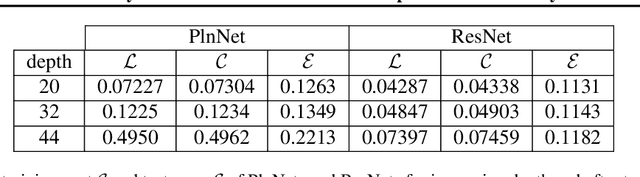

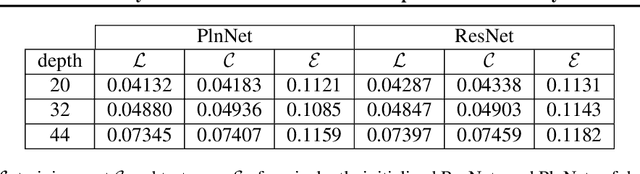
Residual Neural Networks (ResNets) achieve state-of-the-art performance in many computer vision problems. Compared to plain networks without residual connections (PlnNets), ResNets train faster, generalize better, and suffer less from the so-called degradation problem. We introduce simplified (but still nonlinear) versions of ResNets and PlnNets for which these discrepancies still hold, although to a lesser degree. We establish a 1-1 mapping between simplified ResNets and simplified PlnNets, and show that they are exactly equivalent to each other in expressive power for the same computational complexity. We conjecture that ResNets generalize better because they have better noise stability, and empirically support it for both simplified and fully-fledged networks.