 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandMSAugment: A Mixed-Sample Augmentation for Limited-Data Scenarios
Paper and Code
Nov 25, 2023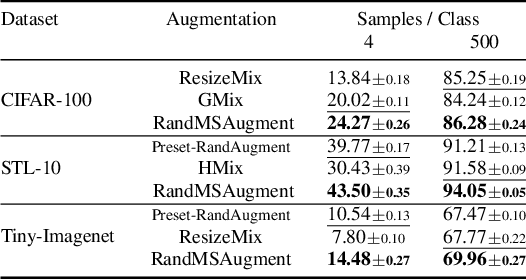
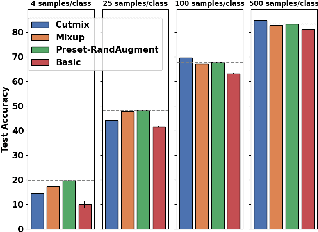
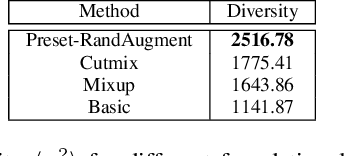
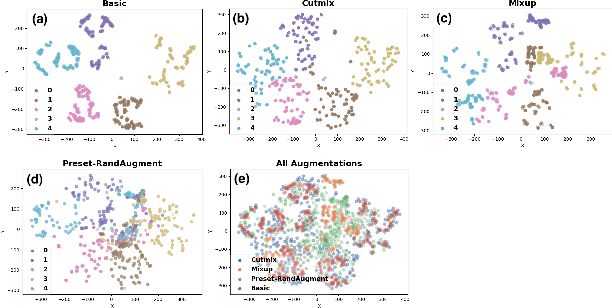
The high costs of annotating large datasets suggests a need for effectively training CNNs with limited data, and data augmentation is a promising direction. We study foundational augmentation techniques, including Mixed Sample Data Augmentations (MSDAs) and a no-parameter variant of RandAugment termed Preset-RandAugment, in the fully supervised scenario. We observe that Preset-RandAugment excels in limited-data contexts while MSDAs are moderately effective. We show that low-level feature transforms play a pivotal role in this performance difference, postulate a new property of augmentations related to their data efficiency, and propose new ways to measure the diversity and realism of augmentations. Building on these insights, we introduce a novel augmentation technique called RandMSAugment that integrates complementary strengths of existing methods. RandMSAugment significantly outperforms the competition on CIFAR-100, STL-10, and Tiny-Imagenet. With very small training sets (4, 25, 100 samples/class), RandMSAugment achieves compelling performance gains between 4.1% and 6.75%. Even with more training data (500 samples/class) we improve performance by 1.03% to 2.47%. RandMSAugment does not require hyperparameter tuning, extra validation data, or cumbersome optimizations.