 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Over a Distribution of Hyperparameters for Enhanced Performance and Adaptability on Imbalanced Classification
Oct 04, 2024



Although binary classification is a well-studied problem, training reliable classifiers under severe class imbalance remains a challenge. Recent techniques mitigate the ill effects of imbalance on training by modifying the loss functions or optimization methods. We observe that different hyperparameter values on these loss functions perform better at different recall values. We propose to exploit this fact by training one model over a distribution of hyperparameter values--instead of a single value--via Loss Conditional Training (LCT). Experiments show that training over a distribution of hyperparameters not only approximates the performance of several models but actually improves the overall performance of models on both CIFAR and real medical imaging applications, such as melanoma and diabetic retinopathy detection. Furthermore, training models with LCT is more efficient because some hyperparameter tuning can be conducted after training to meet individual needs without needing to retrain from scratch.
Optimizing for ROC Curves on Class-Imbalanced Data by Training over a Family of Loss Functions
Feb 08, 2024



Although binary classification is a well-studied problem in computer vision, training reliable classifiers under severe class imbalance remains a challenging problem. Recent work has proposed techniques that mitigate the effects of training under imbalance by modifying the loss functions or optimization methods. While this work has led to significant improvements in the overall accuracy in the multi-class case, we observe that slight changes in hyperparameter values of these methods can result in highly variable performance in terms of Receiver Operating Characteristic (ROC) curves on binary problems with severe imbalance. To reduce the sensitivity to hyperparameter choices and train more general models, we propose training over a family of loss functions, instead of a single loss function. We develop a method for applying Loss Conditional Training (LCT) to an imbalanced classification problem. Extensive experiment results, on both CIFAR and Kaggle competition datasets, show that our method improves model performance and is more robust to hyperparameter choices. Code will be made available at: https://github.com/klieberman/roc_lct.
RandMSAugment: A Mixed-Sample Augmentation for Limited-Data Scenarios
Nov 25, 2023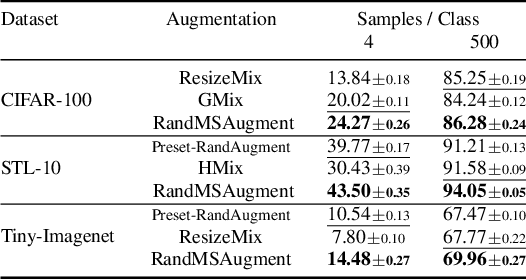
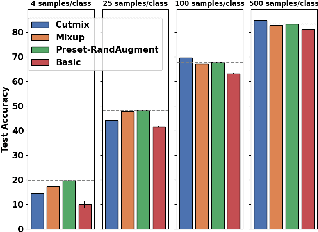
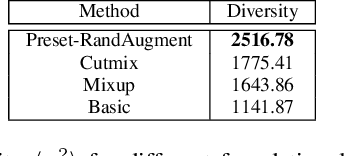
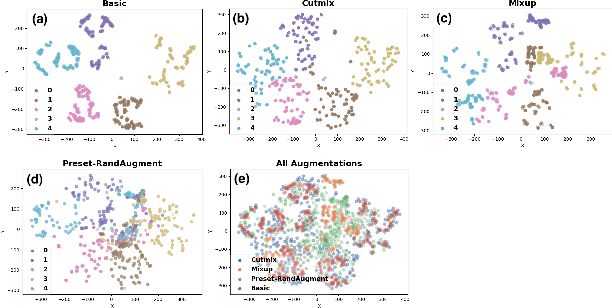
The high costs of annotating large datasets suggests a need for effectively training CNNs with limited data, and data augmentation is a promising direction. We study foundational augmentation techniques, including Mixed Sample Data Augmentations (MSDAs) and a no-parameter variant of RandAugment termed Preset-RandAugment, in the fully supervised scenario. We observe that Preset-RandAugment excels in limited-data contexts while MSDAs are moderately effective. We show that low-level feature transforms play a pivotal role in this performance difference, postulate a new property of augmentations related to their data efficiency, and propose new ways to measure the diversity and realism of augmentations. Building on these insights, we introduce a novel augmentation technique called RandMSAugment that integrates complementary strengths of existing methods. RandMSAugment significantly outperforms the competition on CIFAR-100, STL-10, and Tiny-Imagenet. With very small training sets (4, 25, 100 samples/class), RandMSAugment achieves compelling performance gains between 4.1% and 6.75%. Even with more training data (500 samples/class) we improve performance by 1.03% to 2.47%. RandMSAugment does not require hyperparameter tuning, extra validation data, or cumbersome optimizations.
CoMaL Tracking: Tracking Points at the Object Boundaries
Jun 07, 2017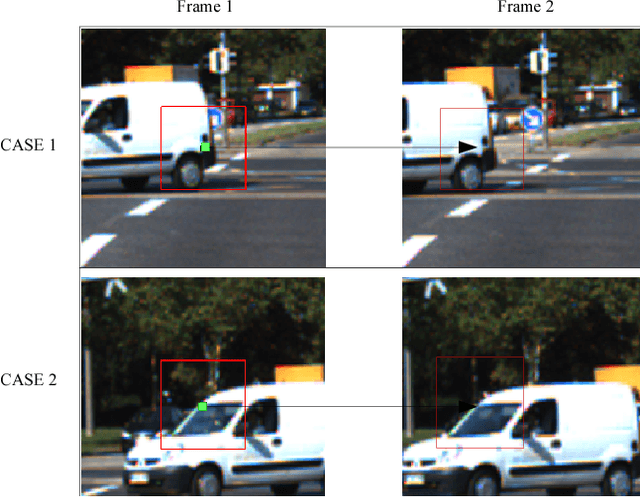
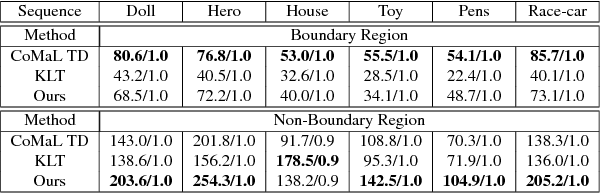
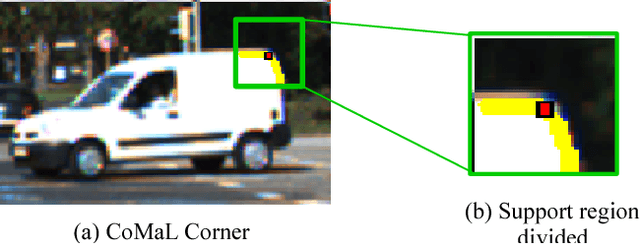
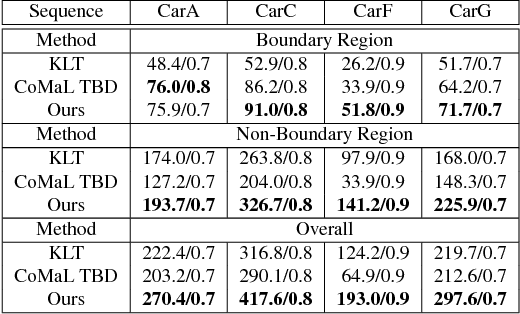
Traditional point tracking algorithms such as the KLT use local 2D information aggregation for feature detection and tracking, due to which their performance degrades at the object boundaries that separate multiple objects. Recently, CoMaL Features have been proposed that handle such a case. However, they proposed a simple tracking framework where the points are re-detected in each frame and matched. This is inefficient and may also lose many points that are not re-detected in the next frame. We propose a novel tracking algorithm to accurately and efficiently track CoMaL points. For this, the level line segment associated with the CoMaL points is matched to MSER segments in the next frame using shape-based matching and the matches are further filtered using texture-based matching. Experiments show improvements over a simple re-detect-and-match framework as well as KLT in terms of speed/accuracy on different real-world applications, especially at the object boundaries.
CoMIC: Good features for detection and matching at object boundaries
Dec 05, 2014


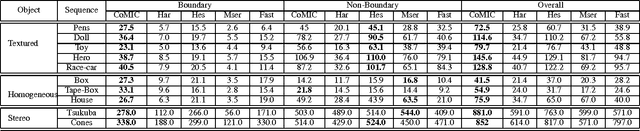
Feature or interest points typically use information aggregation in 2D patches which does not remain stable at object boundaries when there is object motion against a significantly varying background. Level or iso-intensity curves are much more stable under such conditions, especially the longer ones. In this paper, we identify stable portions on long iso-curves and detect corners on them. Further, the iso-curve associated with a corner is used to discard portions from the background and improve matching. Such CoMIC (Corners on Maximally-stable Iso-intensity Curves) points yield superior results at the object boundary regions compared to state-of-the-art detectors while performing comparably at the interior regions as well. This is illustrated in exhaustive matching experiments for both boundary and non-boundary regions in applications such as stereo and point tracking for structure from motion in video sequences.