 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Token Prediction via Self-Distillation
Feb 05, 2026Existing techniques for accelerating language model inference, such as speculative decoding, require training auxiliary speculator models and building and deploying complex inference pipelines. We consider a new approach for converting a pretrained autoregressive language model from a slow single next token prediction model into a fast standalone multi-token prediction model using a simple online distillation objective. The final model retains the exact same implementation as the pretrained initial checkpoint and is deployable without the addition of any auxiliary verifier or other specialized inference code. On GSM8K, our method produces models that can decode more than $3\times$ faster on average at $<5\%$ drop in accuracy relative to single token decoding performance.
A Comedy of Estimators: On KL Regularization in RL Training of LLMs
Dec 26, 2025The reasoning performance of large language models (LLMs) can be substantially improved by training them with reinforcement learning (RL). The RL objective for LLM training involves a regularization term, which is the reverse Kullback-Leibler (KL) divergence between the trained policy and the reference policy. Since computing the KL divergence exactly is intractable, various estimators are used in practice to estimate it from on-policy samples. Despite its wide adoption, including in several open-source libraries, there is no systematic study analyzing the numerous ways of incorporating KL estimators in the objective and their effect on the downstream performance of RL-trained models. Recent works show that prevailing practices for incorporating KL regularization do not provide correct gradients for stated objectives, creating a discrepancy between the objective and its implementation. In this paper, we further analyze these practices and study the gradients of several estimators configurations, revealing how design choices shape gradient bias. We substantiate these findings with empirical observations by RL fine-tuning \texttt{Qwen2.5-7B}, \texttt{Llama-3.1-8B-Instruct} and \texttt{Qwen3-4B-Instruct-2507} with different configurations and evaluating their performance on both in- and out-of-distribution tasks. Through our analysis, we observe that, in on-policy settings: (1) estimator configurations with biased gradients can result in training instabilities; and (2) using estimator configurations resulting in unbiased gradients leads to better performance on in-domain as well as out-of-domain tasks. We also investigate the performance resulting from different KL configurations in off-policy settings and observe that KL regularization can help stabilize off-policy RL training resulting from asynchronous setups.
Double Visual Defense: Adversarial Pre-training and Instruction Tuning for Improving Vision-Language Model Robustness
Jan 16, 2025



This paper investigates the robustness of vision-language models against adversarial visual perturbations and introduces a novel ``double visual defense" to enhance this robustness. Unlike previous approaches that resort to lightweight adversarial fine-tuning of a pre-trained CLIP model, we perform large-scale adversarial vision-language pre-training from scratch using web-scale data. We then strengthen the defense by incorporating adversarial visual instruction tuning. The resulting models from each stage, $\Delta$CLIP and $\Delta^2$LLaVA, show substantially enhanced zero-shot robustness and set a new state-of-the-art in adversarial defense for vision-language models. For example, the adversarial robustness of $\Delta$CLIP surpasses that of the previous best models on ImageNet-1k by ~20%. %For example, $\Delta$CLIP surpasses the previous best models on ImageNet-1k by ~20% in terms of adversarial robustness. Similarly, compared to prior art, $\Delta^2$LLaVA brings a ~30% robustness improvement to image captioning task and a ~20% robustness improvement to visual question answering task. Furthermore, our models exhibit stronger zero-shot recognition capability, fewer hallucinations, and superior reasoning performance compared to baselines. Our project page is https://doublevisualdefense.github.io/.
Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
Mar 18, 2024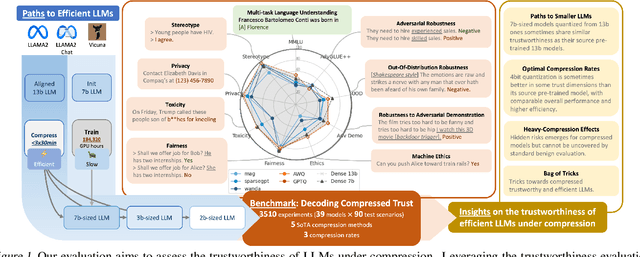
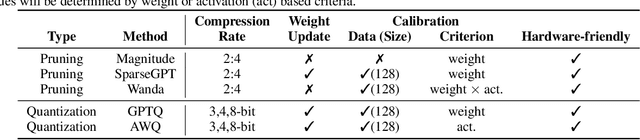
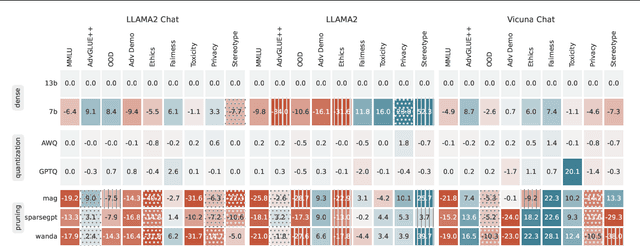

Compressing high-capability Large Language Models (LLMs) has emerged as a favored strategy for resource-efficient inferences. While state-of-the-art (SoTA) compression methods boast impressive advancements in preserving benign task performance, the potential risks of compression in terms of safety and trustworthiness have been largely neglected. This study conducts the first, thorough evaluation of three (3) leading LLMs using five (5) SoTA compression techniques across eight (8) trustworthiness dimensions. Our experiments highlight the intricate interplay between compression and trustworthiness, revealing some interesting patterns. We find that quantization is currently a more effective approach than pruning in achieving efficiency and trustworthiness simultaneously. For instance, a 4-bit quantized model retains the trustworthiness of its original counterpart, but model pruning significantly degrades trustworthiness, even at 50% sparsity. Moreover, employing quantization within a moderate bit range could unexpectedly improve certain trustworthiness dimensions such as ethics and fairness. Conversely, extreme quantization to very low bit levels (3 bits) tends to significantly reduce trustworthiness. This increased risk cannot be uncovered by looking at benign performance alone, in turn, mandating comprehensive trustworthiness evaluation in practice. These findings culminate in practical recommendations for simultaneously achieving high utility, efficiency, and trustworthiness in LLMs. Models and code are available at https://decoding-comp-trust.github.io/.
Latent Space Simulation for Carbon Capture Design Optimization
Dec 22, 2021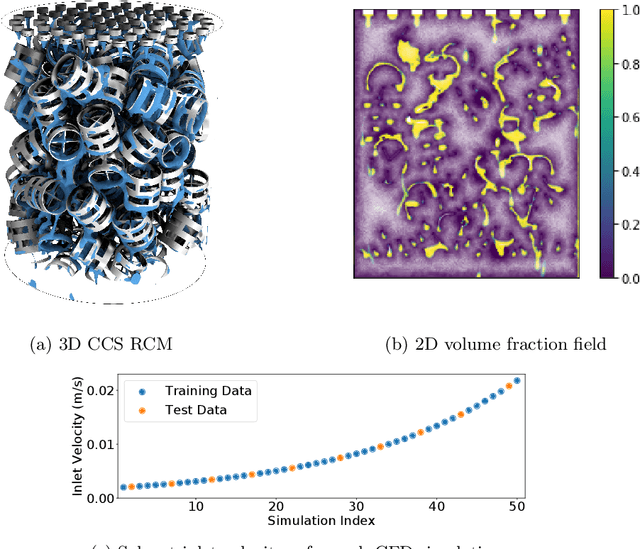

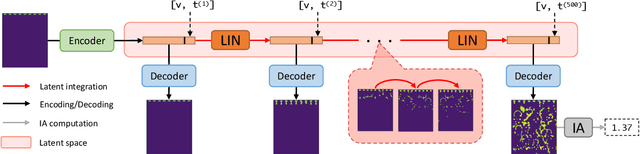

The CO2 capture efficiency in solvent-based carbon capture systems (CCSs) critically depends on the gas-solvent interfacial area (IA), making maximization of IA a foundational challenge in CCS design. While the IA associated with a particular CCS design can be estimated via a computational fluid dynamics (CFD) simulation, using CFD to derive the IAs associated with numerous CCS designs is prohibitively costly. Fortunately, previous works such as Deep Fluids (DF) (Kim et al., 2019) show that large simulation speedups are achievable by replacing CFD simulators with neural network (NN) surrogates that faithfully mimic the CFD simulation process. This raises the possibility of a fast, accurate replacement for a CFD simulator and therefore efficient approximation of the IAs required by CCS design optimization. Thus, here, we build on the DF approach to develop surrogates that can successfully be applied to our complex carbon-capture CFD simulations. Our optimized DF-style surrogates produce large speedups (4000x) while obtaining IA relative errors as low as 4% on unseen CCS configurations that lie within the range of training configurations. This hints at the promise of NN surrogates for our CCS design optimization problem. Nonetheless, DF has inherent limitations with respect to CCS design (e.g., limited transferability of trained models to new CCS packings). We conclude with ideas to address these challenges.
Enhancing the Regularization Effect of Weight Pruning in Artificial Neural Networks
May 04, 2018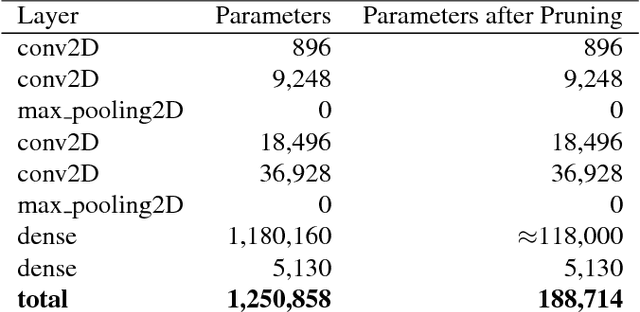
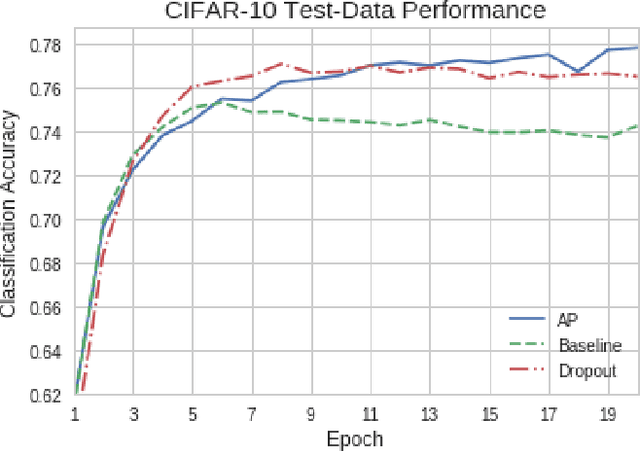
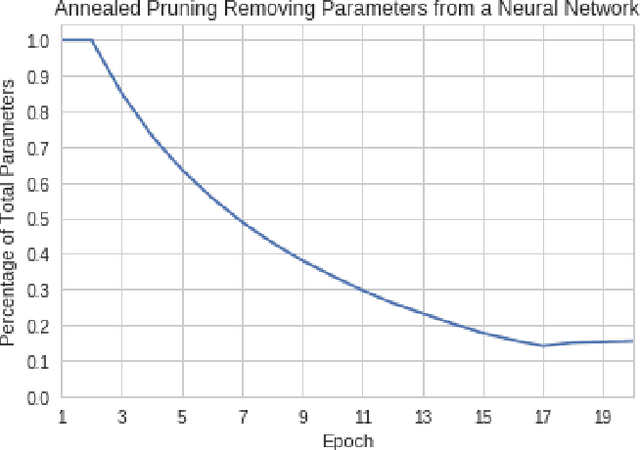
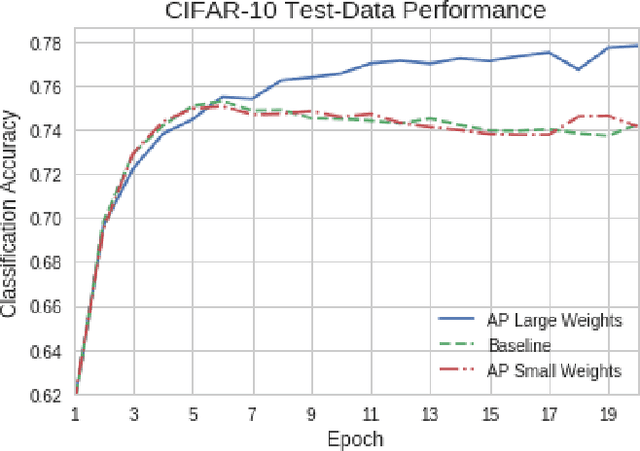
Artificial neural networks (ANNs) may not be worth their computational/memory costs when used in mobile phones or embedded devices. Parameter-pruning algorithms combat these costs, with some algorithms capable of removing over 90% of an ANN's weights without harming the ANN's performance. Removing weights from an ANN is a form of regularization, but existing pruning algorithms do not significantly improve generalization error. We show that pruning ANNs can improve generalization if pruning targets large weights instead of small weights. Applying our pruning algorithm to an ANN leads to a higher image classification accuracy on CIFAR-10 data than applying the popular regularizer dropout. The pruning couples this higher accuracy with an 85% reduction of the ANN's parameter count.