 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScientific Computing Algorithms to Learn Enhanced Scalable Surrogates for Mesh Physics
Apr 01, 2023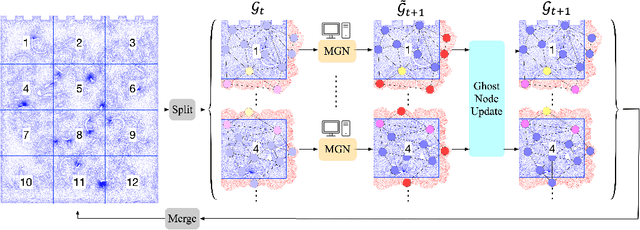

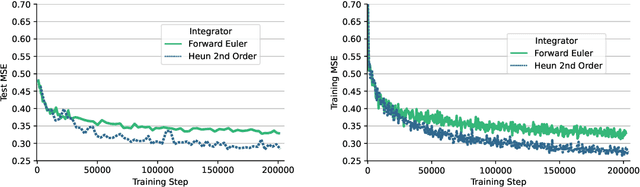
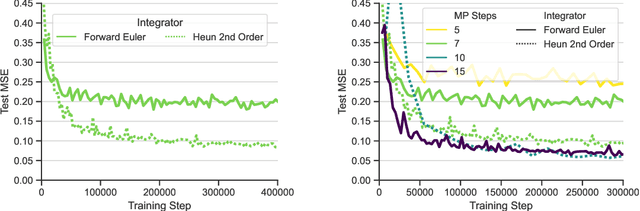
Data-driven modeling approaches can produce fast surrogates to study large-scale physics problems. Among them, graph neural networks (GNNs) that operate on mesh-based data are desirable because they possess inductive biases that promote physical faithfulness, but hardware limitations have precluded their application to large computational domains. We show that it is \textit{possible} to train a class of GNN surrogates on 3D meshes. We scale MeshGraphNets (MGN), a subclass of GNNs for mesh-based physics modeling, via our domain decomposition approach to facilitate training that is mathematically equivalent to training on the whole domain under certain conditions. With this, we were able to train MGN on meshes with \textit{millions} of nodes to generate computational fluid dynamics (CFD) simulations. Furthermore, we show how to enhance MGN via higher-order numerical integration, which can reduce MGN's error and training time. We validated our methods on an accompanying dataset of 3D $\text{CO}_2$-capture CFD simulations on a 3.1M-node mesh. This work presents a practical path to scaling MGN for real-world applications.
Detect, Retrieve, Comprehend: A Flexible Framework for Zero-Shot Document-Level Question Answering
Oct 04, 2022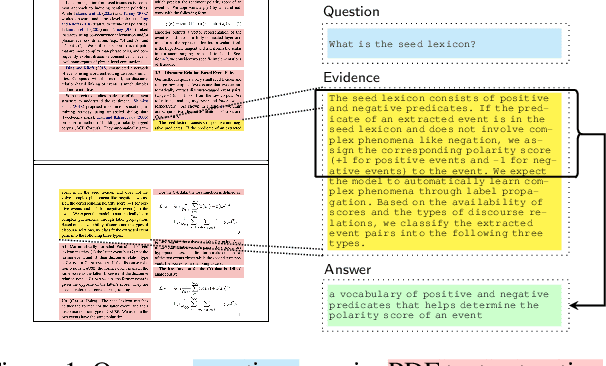
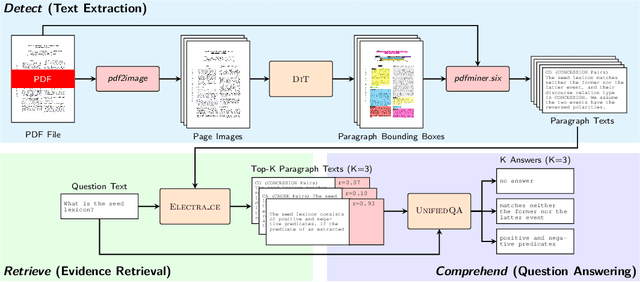

Businesses generate thousands of documents that communicate their strategic vision and provide details of key products, services, entities, and processes. Knowledge workers then face the laborious task of reading these documents to identify, extract, and synthesize information relevant to their organizational goals. To automate information gathering, question answering (QA) offers a flexible framework where human-posed questions can be adapted to extract diverse knowledge. Finetuning QA systems requires access to labeled data (tuples of context, question, and answer). However, data curation for document QA is uniquely challenging because the context (i.e., answer evidence passage) needs to be retrieved from potentially long, ill-formatted documents. Existing QA datasets sidestep this challenge by providing short, well-defined contexts that are unrealistic in real-world applications. We present a three-stage document QA approach: (1) text extraction from PDF; (2) evidence retrieval from extracted texts to form well-posed contexts; (3) QA to extract knowledge from contexts to return high-quality answers - extractive, abstractive, or Boolean. Using QASPER as a surrogate to our proprietary data, our detect-retrieve-comprehend (DRC) system achieves a +6.25 improvement in Answer-F1 over existing baselines while delivering superior context selection. Our results demonstrate that DRC holds tremendous promise as a flexible framework for practical document QA.
Latent Space Simulation for Carbon Capture Design Optimization
Dec 22, 2021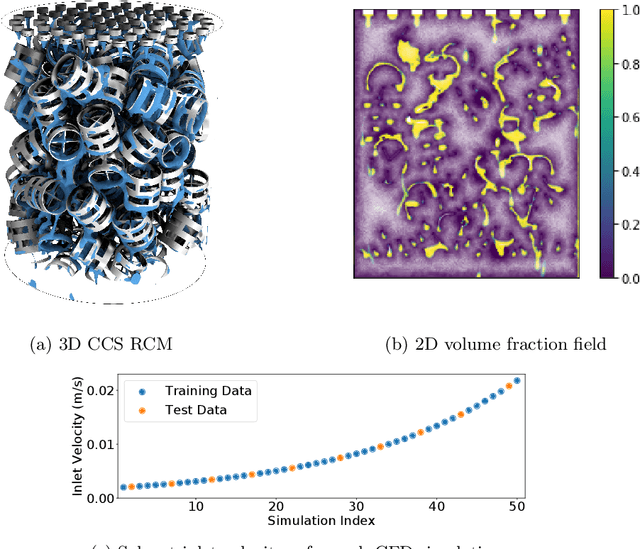

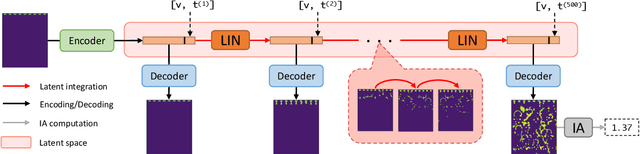

The CO2 capture efficiency in solvent-based carbon capture systems (CCSs) critically depends on the gas-solvent interfacial area (IA), making maximization of IA a foundational challenge in CCS design. While the IA associated with a particular CCS design can be estimated via a computational fluid dynamics (CFD) simulation, using CFD to derive the IAs associated with numerous CCS designs is prohibitively costly. Fortunately, previous works such as Deep Fluids (DF) (Kim et al., 2019) show that large simulation speedups are achievable by replacing CFD simulators with neural network (NN) surrogates that faithfully mimic the CFD simulation process. This raises the possibility of a fast, accurate replacement for a CFD simulator and therefore efficient approximation of the IAs required by CCS design optimization. Thus, here, we build on the DF approach to develop surrogates that can successfully be applied to our complex carbon-capture CFD simulations. Our optimized DF-style surrogates produce large speedups (4000x) while obtaining IA relative errors as low as 4% on unseen CCS configurations that lie within the range of training configurations. This hints at the promise of NN surrogates for our CCS design optimization problem. Nonetheless, DF has inherent limitations with respect to CCS design (e.g., limited transferability of trained models to new CCS packings). We conclude with ideas to address these challenges.
Attend and Decode: 4D fMRI Task State Decoding Using Attention Models
Apr 10, 2020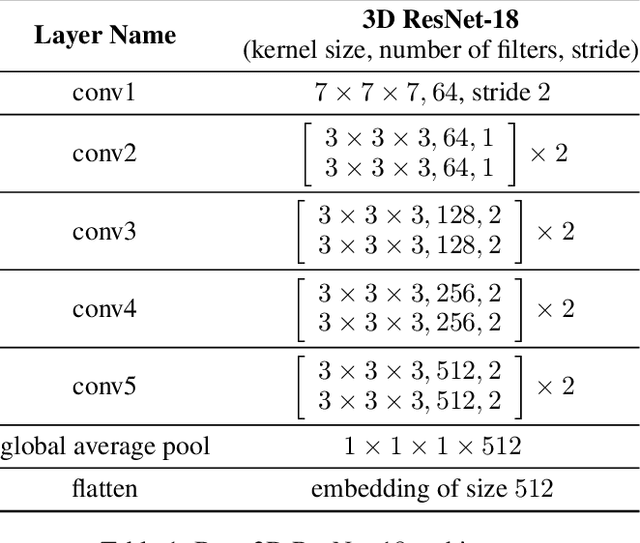



Functional magnetic resonance imaging (fMRI) is a neuroimaging modality that captures the blood oxygen level in a subject's brain while the subject performs a variety of functional tasks under different conditions. Given fMRI data, the problem of inferring the task, known as task state decoding, is challenging due to the high dimensionality (hundreds of million sampling points per datum) and complex spatio-temporal blood flow patterns inherent in the data. In this work, we propose to tackle the fMRI task state decoding problem by casting it as a 4D spatio-temporal classification problem. We present a novel architecture called Brain Attend and Decode (BAnD), that uses residual convolutional neural networks for spatial feature extraction and self-attention mechanisms for temporal modeling. We achieve significant performance gain compared to previous works on a 7-task benchmark from the large-scale Human Connectome Project (HCP) dataset. We also investigate the transferability of BAnD's extracted features on unseen HCP tasks, either by freezing the spatial feature extraction layers and retraining the temporal model, or finetuning the entire model. The pre-trained features from BAnD are useful on similar tasks while finetuning them yields competitive results on unseen tasks/conditions.
Factored Particles for Scalable Monitoring
Dec 12, 2012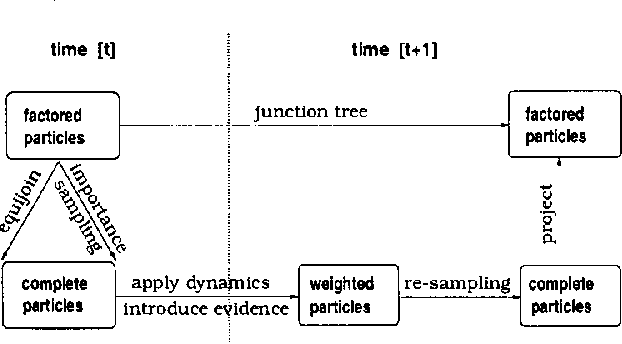
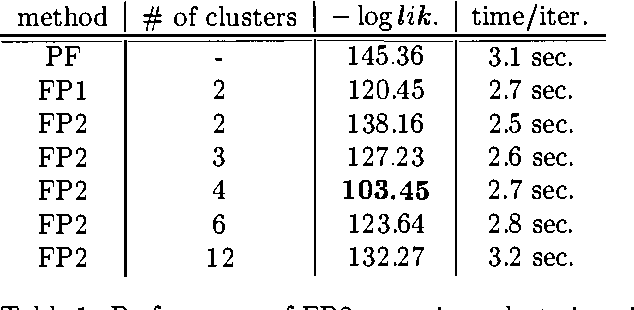

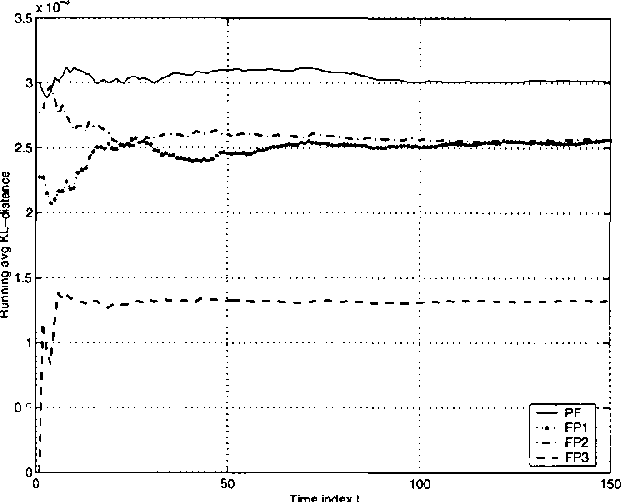
Exact monitoring in dynamic Bayesian networks is intractable, so approximate algorithms are necessary. This paper presents a new family of approximate monitoring algorithms that combine the best qualities of the particle filtering and Boyen-Koller methods. Our algorithms maintain an approximate representation the belief state in the form of sets of factored particles, that correspond to samples of clusters of state variables. Empirical results show that our algorithms outperform both ordinary particle filtering and the Boyen-Koller algorithm on large systems.