 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation Intelligence: Towards a New Generation of Scientific Methods
Dec 06, 2021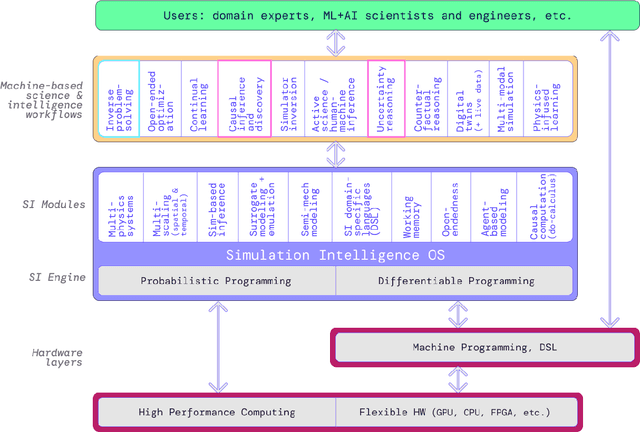
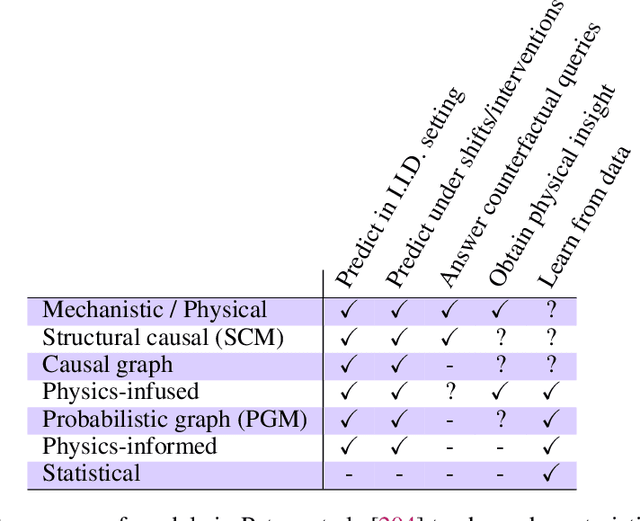
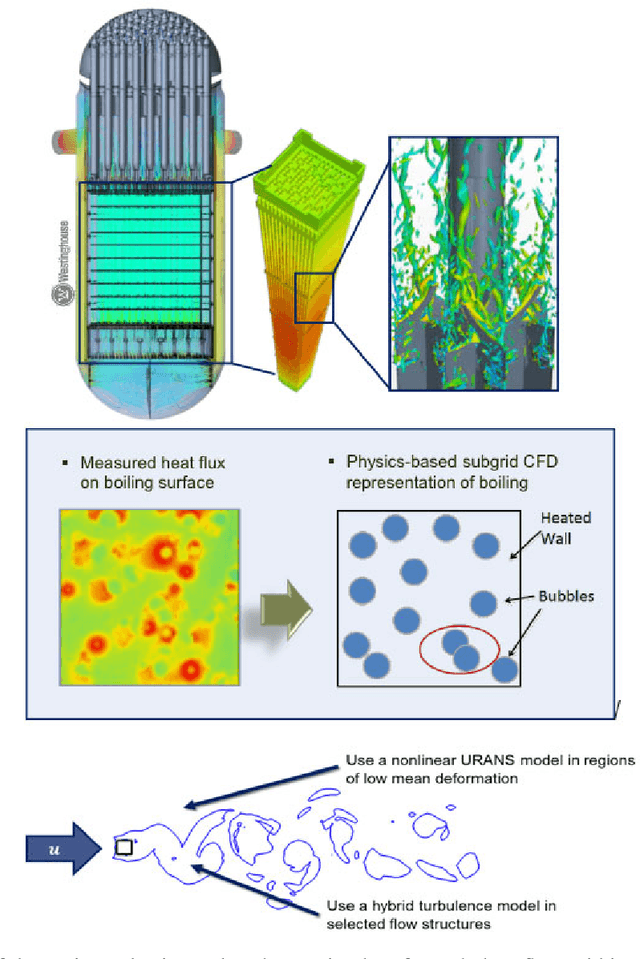
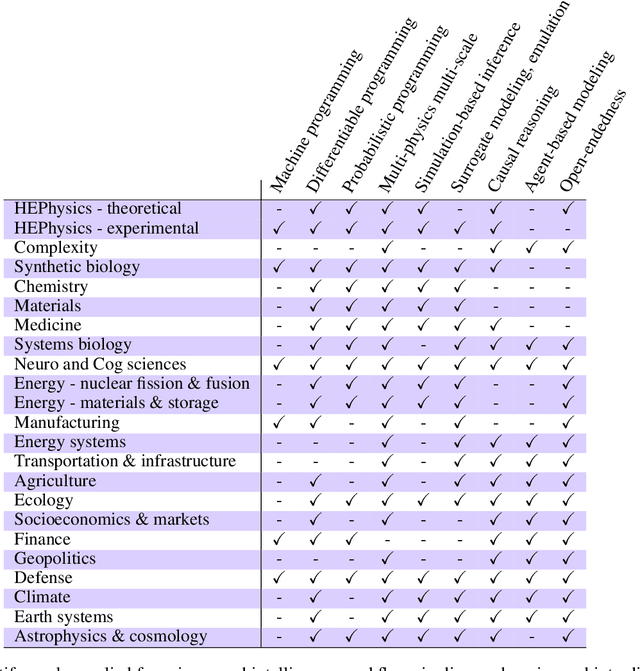
The original "Seven Motifs" set forth a roadmap of essential methods for the field of scientific computing, where a motif is an algorithmic method that captures a pattern of computation and data movement. We present the "Nine Motifs of Simulation Intelligence", a roadmap for the development and integration of the essential algorithms necessary for a merger of scientific computing, scientific simulation, and artificial intelligence. We call this merger simulation intelligence (SI), for short. We argue the motifs of simulation intelligence are interconnected and interdependent, much like the components within the layers of an operating system. Using this metaphor, we explore the nature of each layer of the simulation intelligence operating system stack (SI-stack) and the motifs therein: (1) Multi-physics and multi-scale modeling; (2) Surrogate modeling and emulation; (3) Simulation-based inference; (4) Causal modeling and inference; (5) Agent-based modeling; (6) Probabilistic programming; (7) Differentiable programming; (8) Open-ended optimization; (9) Machine programming. We believe coordinated efforts between motifs offers immense opportunity to accelerate scientific discovery, from solving inverse problems in synthetic biology and climate science, to directing nuclear energy experiments and predicting emergent behavior in socioeconomic settings. We elaborate on each layer of the SI-stack, detailing the state-of-art methods, presenting examples to highlight challenges and opportunities, and advocating for specific ways to advance the motifs and the synergies from their combinations. Advancing and integrating these technologies can enable a robust and efficient hypothesis-simulation-analysis type of scientific method, which we introduce with several use-cases for human-machine teaming and automated science.
Unifying AI Algorithms with Probabilistic Programming using Implicitly Defined Representations
Oct 05, 2021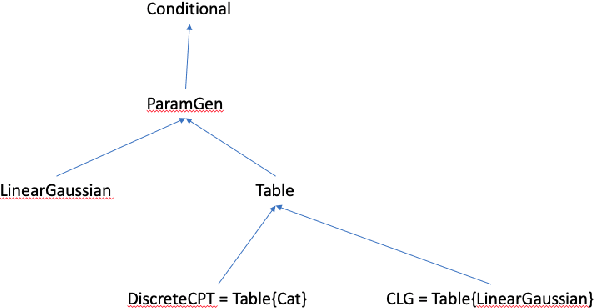
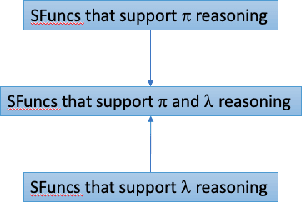
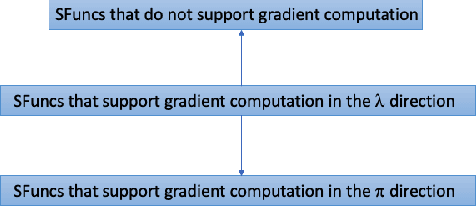
We introduce Scruff, a new framework for developing AI systems using probabilistic programming. Scruff enables a variety of representations to be included, such as code with stochastic choices, neural networks, differential equations, and constraint systems. These representations are defined implicitly using a set of standardized operations that can be performed on them. General-purpose algorithms are then implemented using these operations, enabling generalization across different representations. Zero, one, or more operation implementations can be provided for any given representation, giving algorithms the flexibility to use the most appropriate available implementations for their purposes and enabling representations to be used in ways that suit their capabilities. In this paper, we explain the general approach of implicitly defined representations and provide a variety of examples of representations at varying degrees of abstraction. We also show how a relatively small set of operations can serve to unify a variety of AI algorithms. Finally, we discuss how algorithms can use policies to choose which operation implementations to use during execution.
Learning Probabilistic Programs Using Backpropagation
May 15, 2017Probabilistic modeling enables combining domain knowledge with learning from data, thereby supporting learning from fewer training instances than purely data-driven methods. However, learning probabilistic models is difficult and has not achieved the level of performance of methods such as deep neural networks on many tasks. In this paper, we attempt to address this issue by presenting a method for learning the parameters of a probabilistic program using backpropagation. Our approach opens the possibility to building deep probabilistic programming models that are trained in a similar way to neural networks.
Artificial Intelligence Based Malware Analysis
Apr 27, 2017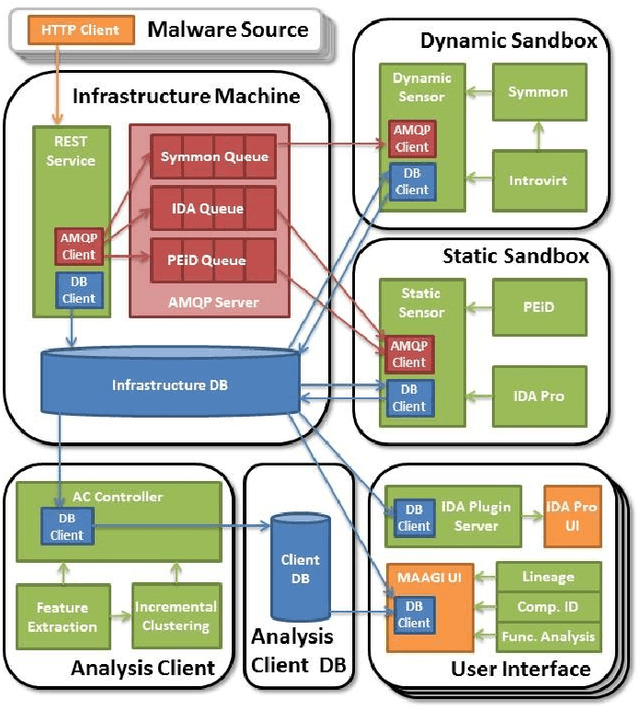
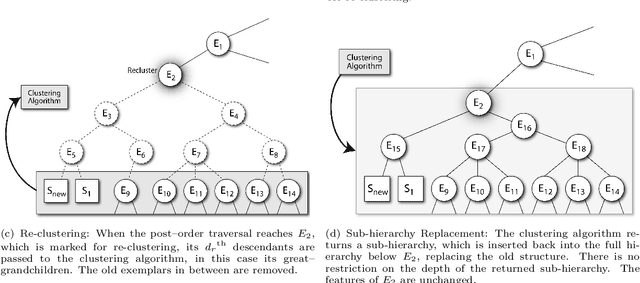

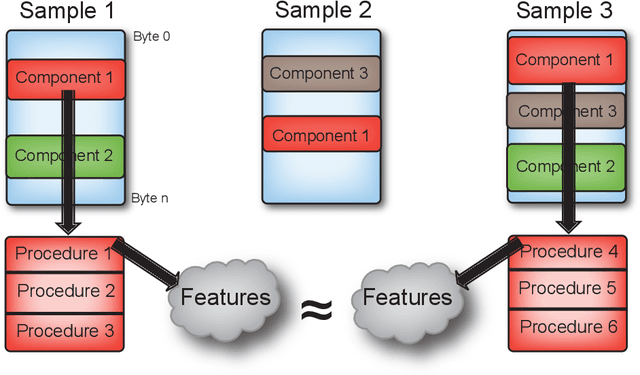
Artificial intelligence methods have often been applied to perform specific functions or tasks in the cyber-defense realm. However, as adversary methods become more complex and difficult to divine, piecemeal efforts to understand cyber-attacks, and malware-based attacks in particular, are not providing sufficient means for malware analysts to understand the past, present and future characteristics of malware. In this paper, we present the Malware Analysis and Attributed using Genetic Information (MAAGI) system. The underlying idea behind the MAAGI system is that there are strong similarities between malware behavior and biological organism behavior, and applying biologically inspired methods to corpora of malware can help analysts better understand the ecosystem of malware attacks. Due to the sophistication of the malware and the analysis, the MAAGI system relies heavily on artificial intelligence techniques to provide this capability. It has already yielded promising results over its development life, and will hopefully inspire more integration between the artificial intelligence and cyber--defense communities.
Structured Factored Inference: A Framework for Automated Reasoning in Probabilistic Programming Languages
Jun 10, 2016
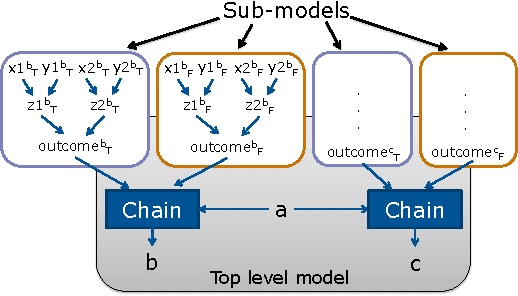
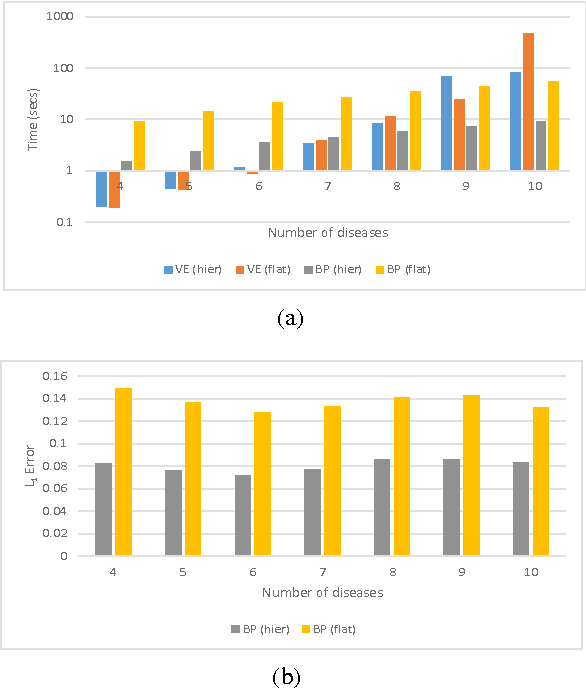
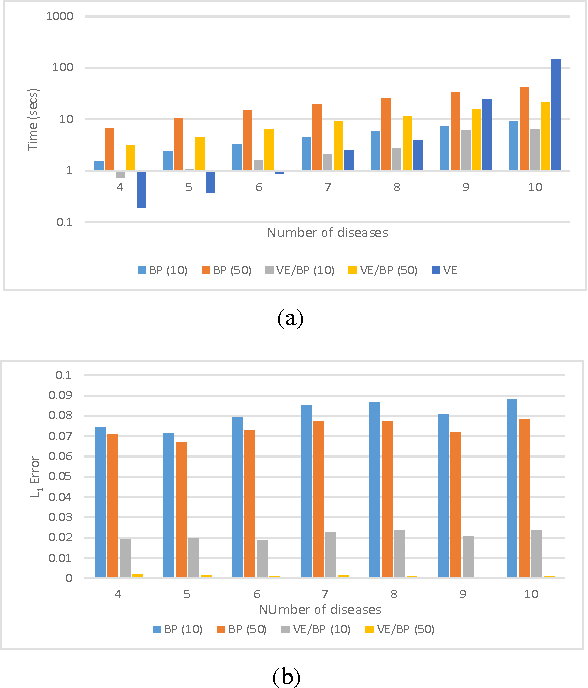
Reasoning on large and complex real-world models is a computationally difficult task, yet one that is required for effective use of many AI applications. A plethora of inference algorithms have been developed that work well on specific models or only on parts of general models. Consequently, a system that can intelligently apply these inference algorithms to different parts of a model for fast reasoning is highly desirable. We introduce a new framework called structured factored inference (SFI) that provides the foundation for such a system. Using models encoded in a probabilistic programming language, SFI provides a sound means to decompose a model into sub-models, apply an inference algorithm to each sub-model, and combine the resulting information to answer a query. Our results show that SFI is nearly as accurate as exact inference yet retains the benefits of approximate inference methods.
Lazy Factored Inference for Functional Probabilistic Programming
Sep 11, 2015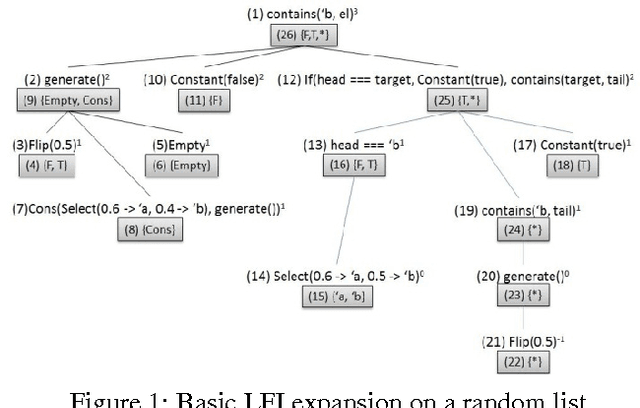
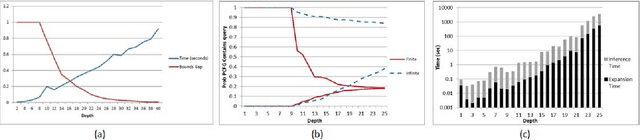
Probabilistic programming provides the means to represent and reason about complex probabilistic models using programming language constructs. Even simple probabilistic programs can produce models with infinitely many variables. Factored inference algorithms are widely used for probabilistic graphical models, but cannot be applied to these programs because all the variables and factors have to be enumerated. In this paper, we present a new inference framework, lazy factored inference (LFI), that enables factored algorithms to be used for models with infinitely many variables. LFI expands the model to a bounded depth and uses the structure of the program to precisely quantify the effect of the unexpanded part of the model, producing lower and upper bounds to the probability of the query.
Proceedings of the Twenty-Seventh Conference on Uncertainty in Artificial Intelligence (2011)
Aug 28, 2014This is the Proceedings of the Twenty-Seventh Conference on Uncertainty in Artificial Intelligence, which was held in Barcelona, Spain, July 14 - 17 2011.
Decision-Making with Complex Data Structures using Probabilistic Programming
Jul 11, 2014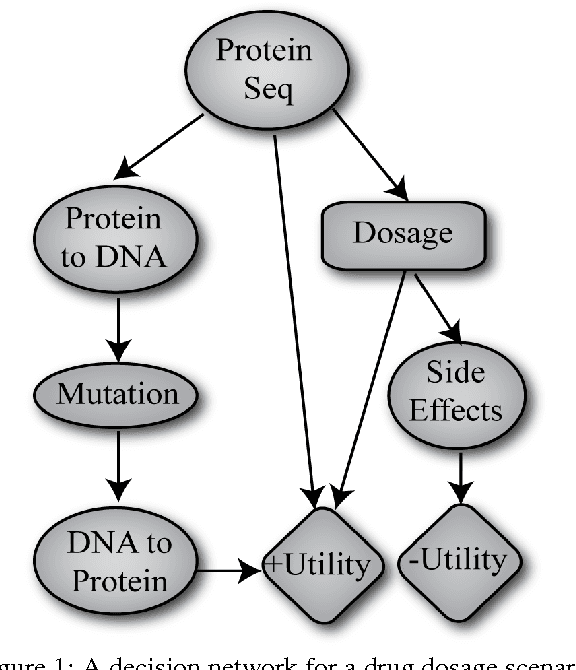

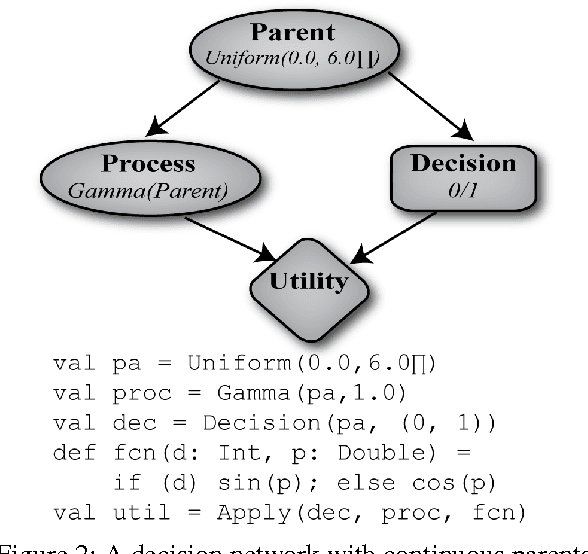

Existing decision-theoretic reasoning frameworks such as decision networks use simple data structures and processes. However, decisions are often made based on complex data structures, such as social networks and protein sequences, and rich processes involving those structures. We present a framework for representing decision problems with complex data structures using probabilistic programming, allowing probabilistic models to be created with programming language constructs such as data structures and control flow. We provide a way to use arbitrary data types with minimal effort from the user, and an approximate decision-making algorithm that is effective even when the information space is very large or infinite. Experimental results show our algorithm working on problems with very large information spaces.
Networks of Influence Diagrams: A Formalism for Representing Agents' Beliefs and Decision-Making Processes
Jan 15, 2014
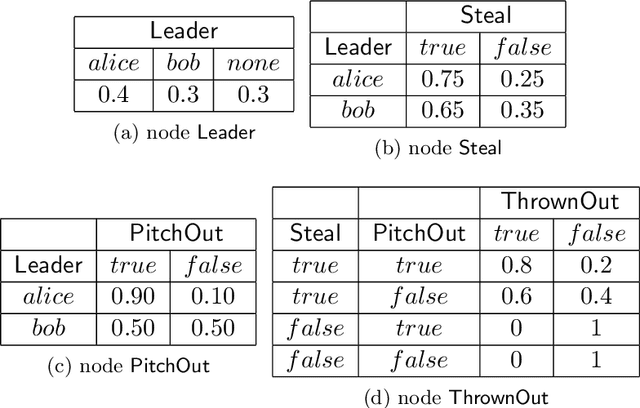
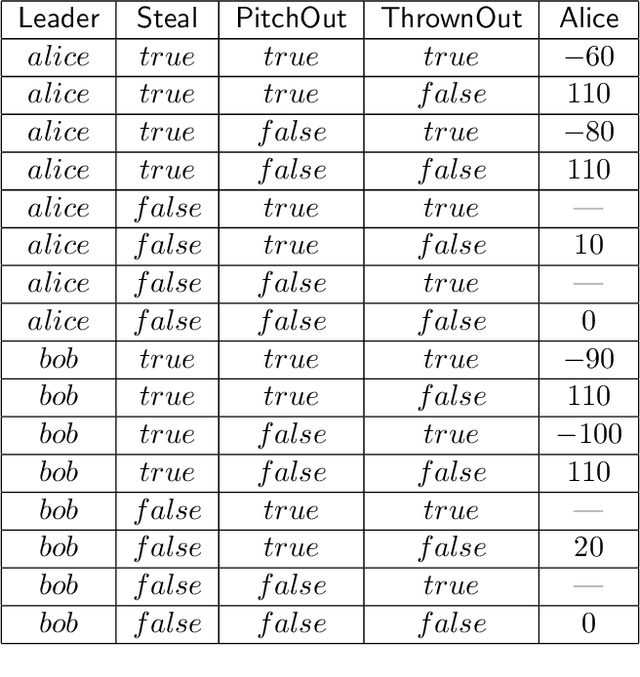
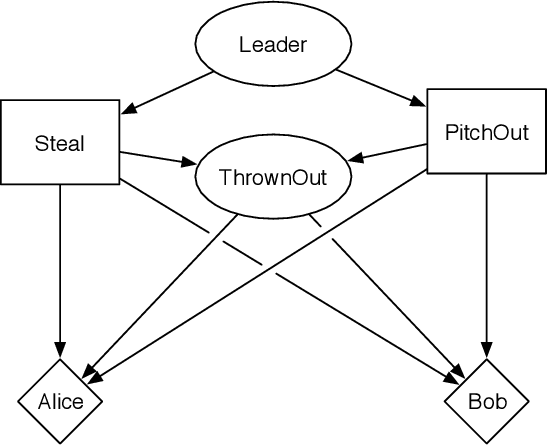
This paper presents Networks of Influence Diagrams (NID), a compact, natural and highly expressive language for reasoning about agents beliefs and decision-making processes. NIDs are graphical structures in which agents mental models are represented as nodes in a network; a mental model for an agent may itself use descriptions of the mental models of other agents. NIDs are demonstrated by examples, showing how they can be used to describe conflicting and cyclic belief structures, and certain forms of bounded rationality. In an opponent modeling domain, NIDs were able to outperform other computational agents whose strategies were not known in advance. NIDs are equivalent in representation to Bayesian games but they are more compact and structured than this formalism. In particular, the equilibrium definition for NIDs makes an explicit distinction between agents optimal strategies, and how they actually behave in reality.
Object-Oriented Bayesian Networks
Feb 06, 2013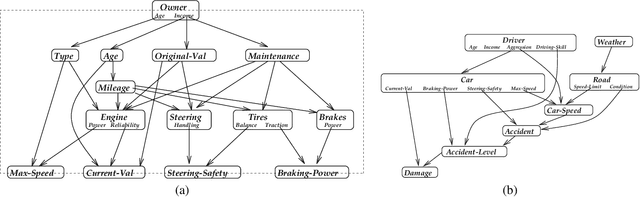

Bayesian networks provide a modeling language and associated inference algorithm for stochastic domains. They have been successfully applied in a variety of medium-scale applications. However, when faced with a large complex domain, the task of modeling using Bayesian networks begins to resemble the task of programming using logical circuits. In this paper, we describe an object-oriented Bayesian network (OOBN) language, which allows complex domains to be described in terms of inter-related objects. We use a Bayesian network fragment to describe the probabilistic relations between the attributes of an object. These attributes can themselves be objects, providing a natural framework for encoding part-of hierarchies. Classes are used to provide a reusable probabilistic model which can be applied to multiple similar objects. Classes also support inheritance of model fragments from a class to a subclass, allowing the common aspects of related classes to be defined only once. Our language has clear declarative semantics: an OOBN can be interpreted as a stochastic functional program, so that it uniquely specifies a probabilistic model. We provide an inference algorithm for OOBNs, and show that much of the structural information encoded by an OOBN--particularly the encapsulation of variables within an object and the reuse of model fragments in different contexts--can also be used to speed up the inference process.