 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFake News Detection on Social Media: A Data Mining Perspective
Sep 03, 2017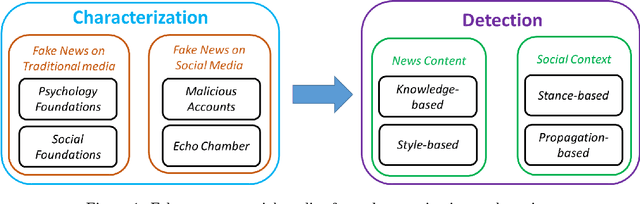


Social media for news consumption is a double-edged sword. On the one hand, its low cost, easy access, and rapid dissemination of information lead people to seek out and consume news from social media. On the other hand, it enables the wide spread of "fake news", i.e., low quality news with intentionally false information. The extensive spread of fake news has the potential for extremely negative impacts on individuals and society. Therefore, fake news detection on social media has recently become an emerging research that is attracting tremendous attention. Fake news detection on social media presents unique characteristics and challenges that make existing detection algorithms from traditional news media ineffective or not applicable. First, fake news is intentionally written to mislead readers to believe false information, which makes it difficult and nontrivial to detect based on news content; therefore, we need to include auxiliary information, such as user social engagements on social media, to help make a determination. Second, exploiting this auxiliary information is challenging in and of itself as users' social engagements with fake news produce data that is big, incomplete, unstructured, and noisy. Because the issue of fake news detection on social media is both challenging and relevant, we conducted this survey to further facilitate research on the problem. In this survey, we present a comprehensive review of detecting fake news on social media, including fake news characterizations on psychology and social theories, existing algorithms from a data mining perspective, evaluation metrics and representative datasets. We also discuss related research areas, open problems, and future research directions for fake news detection on social media.
Lazy Factored Inference for Functional Probabilistic Programming
Sep 11, 2015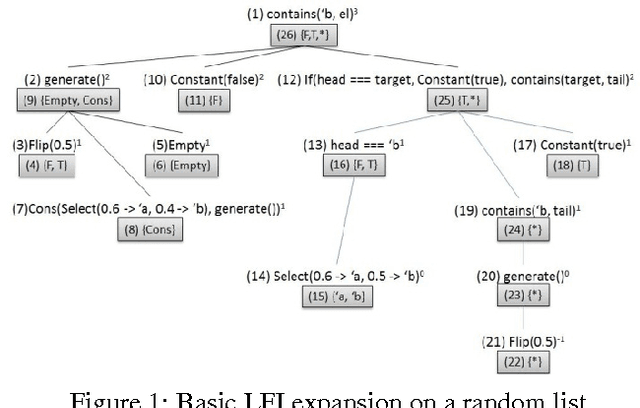
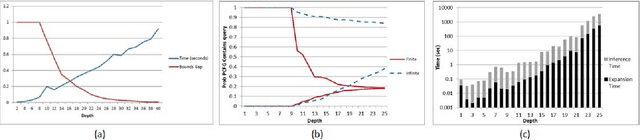
Probabilistic programming provides the means to represent and reason about complex probabilistic models using programming language constructs. Even simple probabilistic programs can produce models with infinitely many variables. Factored inference algorithms are widely used for probabilistic graphical models, but cannot be applied to these programs because all the variables and factors have to be enumerated. In this paper, we present a new inference framework, lazy factored inference (LFI), that enables factored algorithms to be used for models with infinitely many variables. LFI expands the model to a bounded depth and uses the structure of the program to precisely quantify the effect of the unexpanded part of the model, producing lower and upper bounds to the probability of the query.