 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying AI Algorithms with Probabilistic Programming using Implicitly Defined Representations
Oct 05, 2021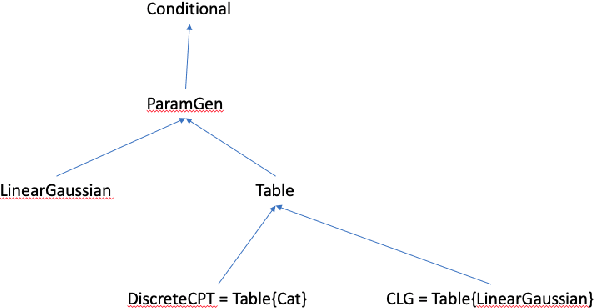
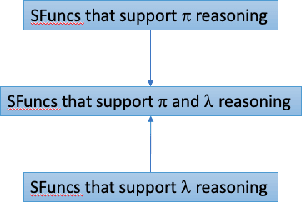
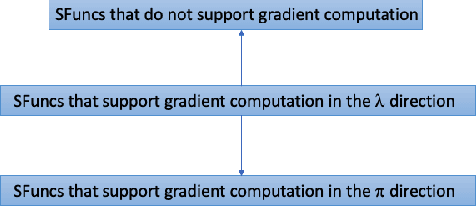
We introduce Scruff, a new framework for developing AI systems using probabilistic programming. Scruff enables a variety of representations to be included, such as code with stochastic choices, neural networks, differential equations, and constraint systems. These representations are defined implicitly using a set of standardized operations that can be performed on them. General-purpose algorithms are then implemented using these operations, enabling generalization across different representations. Zero, one, or more operation implementations can be provided for any given representation, giving algorithms the flexibility to use the most appropriate available implementations for their purposes and enabling representations to be used in ways that suit their capabilities. In this paper, we explain the general approach of implicitly defined representations and provide a variety of examples of representations at varying degrees of abstraction. We also show how a relatively small set of operations can serve to unify a variety of AI algorithms. Finally, we discuss how algorithms can use policies to choose which operation implementations to use during execution.
Explainable Artificial Intelligence for Increasing User Trust in Deep Reinforcement Learning Driven Autonomous Systems
Jun 07, 2021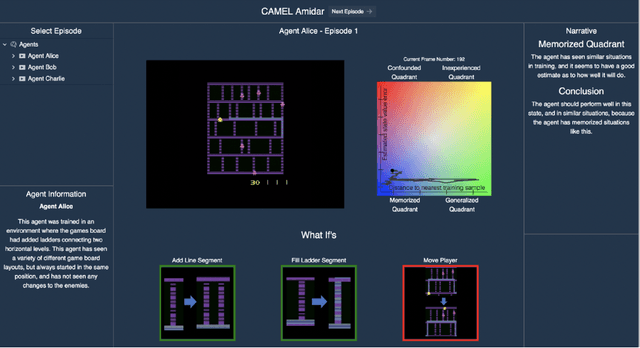
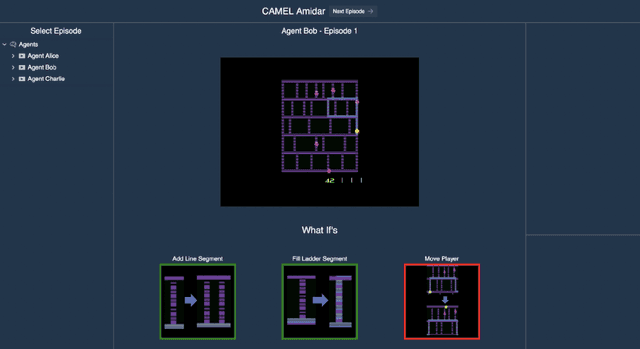
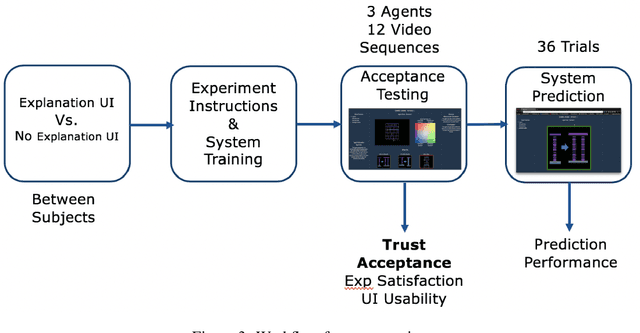
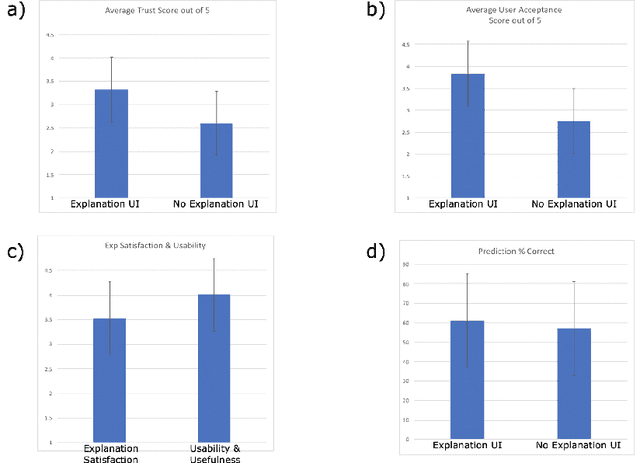
We consider the problem of providing users of deep Reinforcement Learning (RL) based systems with a better understanding of when their output can be trusted. We offer an explainable artificial intelligence (XAI) framework that provides a three-fold explanation: a graphical depiction of the systems generalization and performance in the current game state, how well the agent would play in semantically similar environments, and a narrative explanation of what the graphical information implies. We created a user-interface for our XAI framework and evaluated its efficacy via a human-user experiment. The results demonstrate a statistically significant increase in user trust and acceptance of the AI system with explanation, versus the AI system without explanation.
Causal Learning and Explanation of Deep Neural Networks via Autoencoded Activations
Feb 02, 2018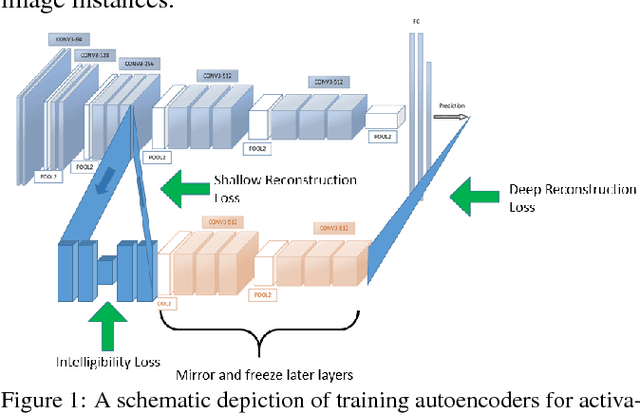
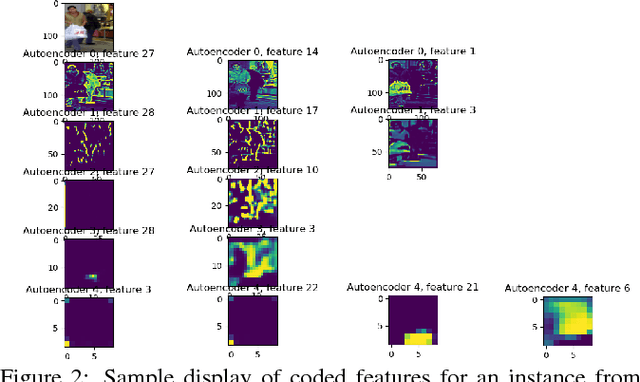

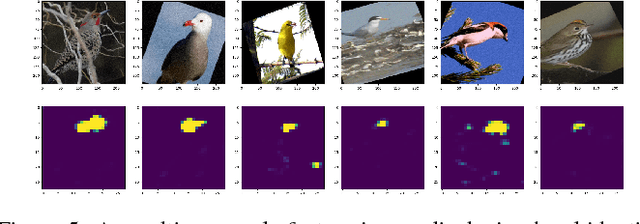
Deep neural networks are complex and opaque. As they enter application in a variety of important and safety critical domains, users seek methods to explain their output predictions. We develop an approach to explaining deep neural networks by constructing causal models on salient concepts contained in a CNN. We develop methods to extract salient concepts throughout a target network by using autoencoders trained to extract human-understandable representations of network activations. We then build a bayesian causal model using these extracted concepts as variables in order to explain image classification. Finally, we use this causal model to identify and visualize features with significant causal influence on final classification.