 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Active Learning based Experimental Design to Uncover Synergistic Genetic Interactions for Host Targeted Therapeutics
Feb 03, 2025



Recent technological advances have introduced new high-throughput methods for studying host-virus interactions, but testing synergistic interactions between host gene pairs during infection remains relatively slow and labor intensive. Identification of multiple gene knockdowns that effectively inhibit viral replication requires a search over the combinatorial space of all possible target gene pairs and is infeasible via brute-force experiments. Although active learning methods for sequential experimental design have shown promise, existing approaches have generally been restricted to single-gene knockdowns or small-scale double knockdown datasets. In this study, we present an integrated Deep Active Learning (DeepAL) framework that incorporates information from a biological knowledge graph (SPOKE, the Scalable Precision Medicine Open Knowledge Engine) to efficiently search the configuration space of a large dataset of all pairwise knockdowns of 356 human genes in HIV infection. Through graph representation learning, the framework is able to generate task-specific representations of genes while also balancing the exploration-exploitation trade-off to pinpoint highly effective double-knockdown pairs. We additionally present an ensemble method for uncertainty quantification and an interpretation of the gene pairs selected by our algorithm via pathway analysis. To our knowledge, this is the first work to show promising results on double-gene knockdown experimental data of appreciable scale (356 by 356 matrix).
Sequential Inference of Hospitalization ElectronicHealth Records Using Probabilistic Models
Mar 27, 2024In the dynamic hospital setting, decision support can be a valuable tool for improving patient outcomes. Data-driven inference of future outcomes is challenging in this dynamic setting, where long sequences such as laboratory tests and medications are updated frequently. This is due in part to heterogeneity of data types and mixed-sequence types contained in variable length sequences. In this work we design a probabilistic unsupervised model for multiple arbitrary-length sequences contained in hospitalization Electronic Health Record (EHR) data. The model uses a latent variable structure and captures complex relationships between medications, diagnoses, laboratory tests, neurological assessments, and medications. It can be trained on original data, without requiring any lossy transformations or time binning. Inference algorithms are derived that use partial data to infer properties of the complete sequences, including their length and presence of specific values. We train this model on data from subjects receiving medical care in the Kaiser Permanente Northern California integrated healthcare delivery system. The results are evaluated against held-out data for predicting the length of sequences and presence of Intensive Care Unit (ICU) in hospitalization bed sequences. Our method outperforms a baseline approach, showing that in these experiments the trained model captures information in the sequences that is informative of their future values.
Unsupervised Probabilistic Models for Sequential Electronic Health Records
Apr 15, 2022
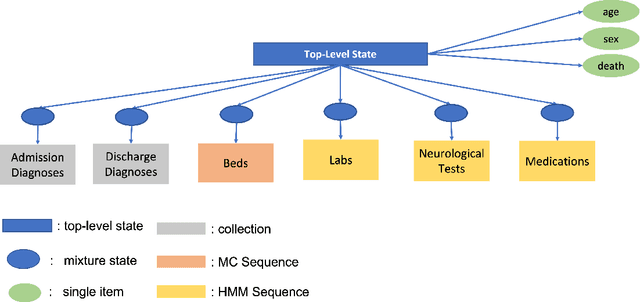
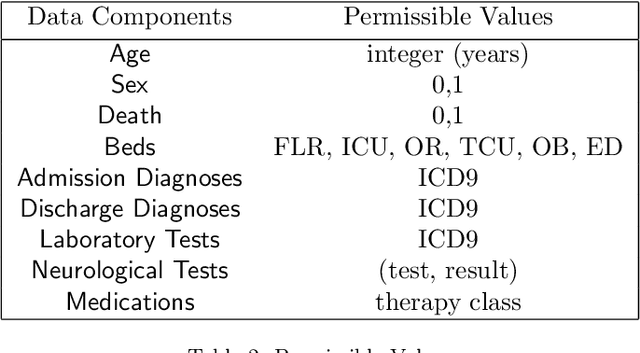
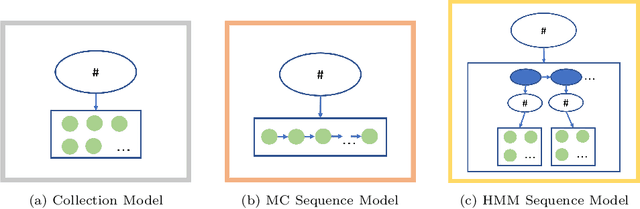
We develop an unsupervised probabilistic model for heterogeneous Electronic Health Record (EHR) data. Utilizing a mixture model formulation, our approach directly models sequences of arbitrary length, such as medications and laboratory results. This allows for subgrouping and incorporation of the dynamics underlying heterogeneous data types. The model consists of a layered set of latent variables that encode underlying structure in the data. These variables represent subject subgroups at the top layer, and unobserved states for sequences in the second layer. We train this model on episodic data from subjects receiving medical care in the Kaiser Permanente Northern California integrated healthcare delivery system. The resulting properties of the trained model generate novel insight from these complex and multifaceted data. In addition, we show how the model can be used to analyze sequences that contribute to assessment of mortality likelihood.
Attend and Decode: 4D fMRI Task State Decoding Using Attention Models
Apr 10, 2020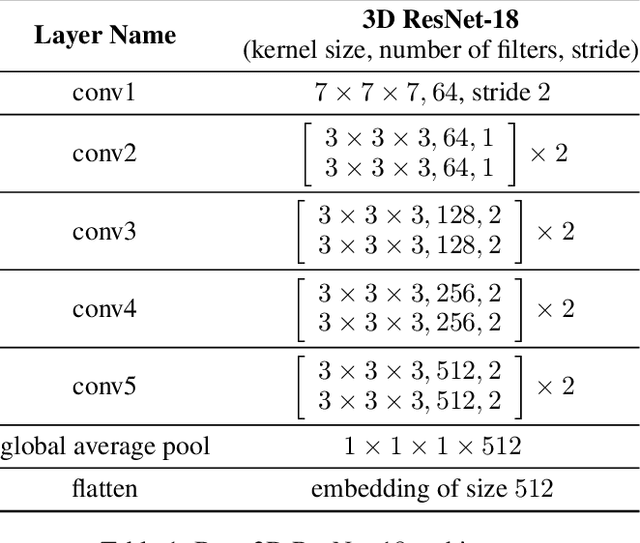



Functional magnetic resonance imaging (fMRI) is a neuroimaging modality that captures the blood oxygen level in a subject's brain while the subject performs a variety of functional tasks under different conditions. Given fMRI data, the problem of inferring the task, known as task state decoding, is challenging due to the high dimensionality (hundreds of million sampling points per datum) and complex spatio-temporal blood flow patterns inherent in the data. In this work, we propose to tackle the fMRI task state decoding problem by casting it as a 4D spatio-temporal classification problem. We present a novel architecture called Brain Attend and Decode (BAnD), that uses residual convolutional neural networks for spatial feature extraction and self-attention mechanisms for temporal modeling. We achieve significant performance gain compared to previous works on a 7-task benchmark from the large-scale Human Connectome Project (HCP) dataset. We also investigate the transferability of BAnD's extracted features on unseen HCP tasks, either by freezing the spatial feature extraction layers and retraining the temporal model, or finetuning the entire model. The pre-trained features from BAnD are useful on similar tasks while finetuning them yields competitive results on unseen tasks/conditions.
Nonstationary Multivariate Gaussian Processes for Electronic Health Records
Oct 13, 2019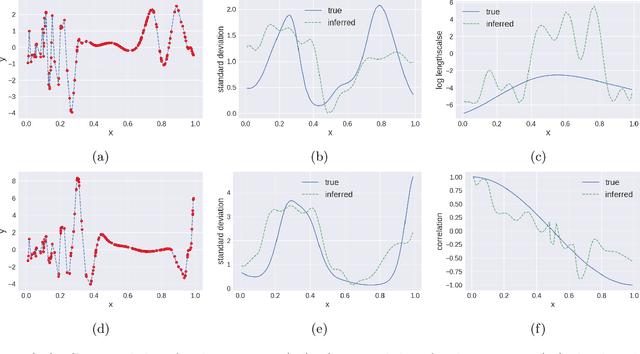

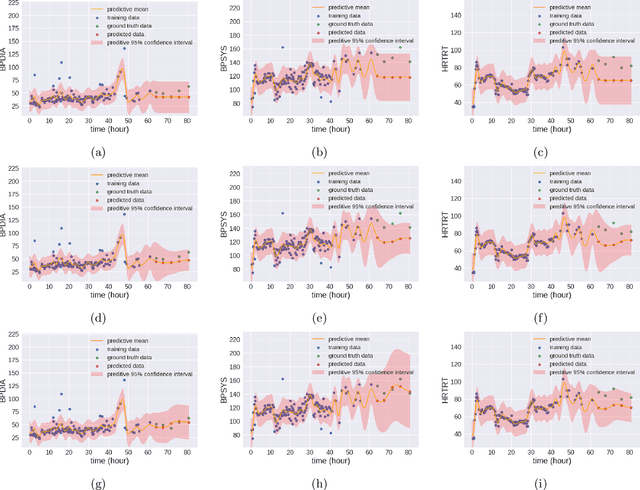
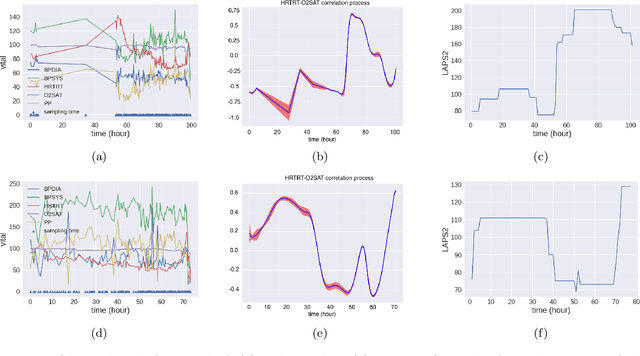
We propose multivariate nonstationary Gaussian processes for jointly modeling multiple clinical variables, where the key parameters, length-scales, standard deviations and the correlations between the observed output, are all time dependent. We perform posterior inference via Hamiltonian Monte Carlo (HMC). We also provide methods for obtaining computationally efficient gradient-based maximum a posteriori (MAP) estimates. We validate our model on synthetic data as well as on electronic health records (EHR) data from Kaiser Permanente (KP). We show that the proposed model provides better predictive performance over a stationary model as well as uncovers interesting latent correlation processes across vitals which are potentially predictive of patient risk.
Regularized Sparse Gaussian Processes
Oct 13, 2019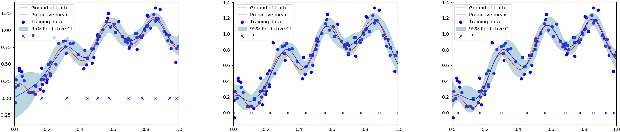
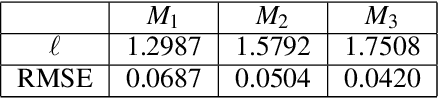
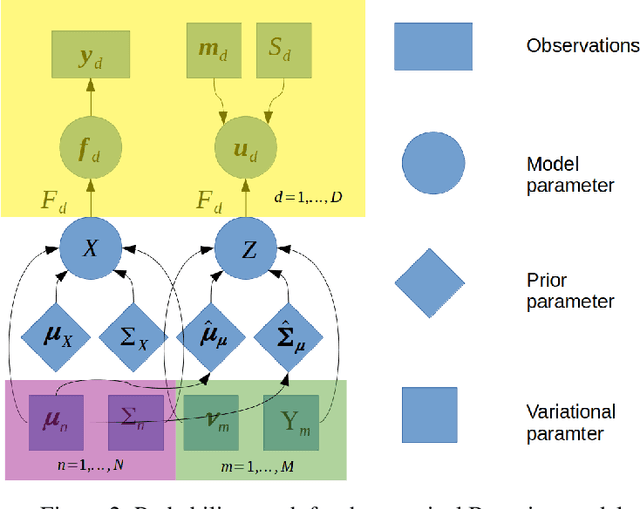
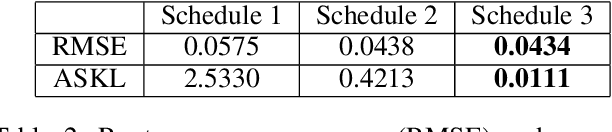
Gaussian processes are a flexible Bayesian nonparametric modelling approach that has been widely applied to learning tasks such as facial expression recognition, image reconstruction, and human pose estimation. To address the issues of poor scaling from exact inference methods, approximation methods based on sparse Gaussian processes (SGP) and variational inference (VI) are necessary for the inference on large datasets. However, one of the problems involved in SGP, especially in latent variable models, is that the distribution of the inducing inputs may fail to capture the distribution of training inputs, which may lead to inefficient inference and poor model prediction. Hence, we propose a regularization approach for sparse Gaussian processes. We also extend this regularization approach into latent sparse Gaussian processes in a unified view, considering the balance of the distribution of inducing inputs and embedding inputs. Furthermore, we justify that performing VI on a sparse latent Gaussian process with this regularization term is equivalent to performing VI on a related empirical Bayes model with a prior on the inducing inputs. Also stochastic variational inference is available for our regularization approach. Finally, the feasibility of our proposed regularization method is demonstrated on three real-world datasets.
Robust Decentralized Learning Using ADMM with Unreliable Agents
May 21, 2018
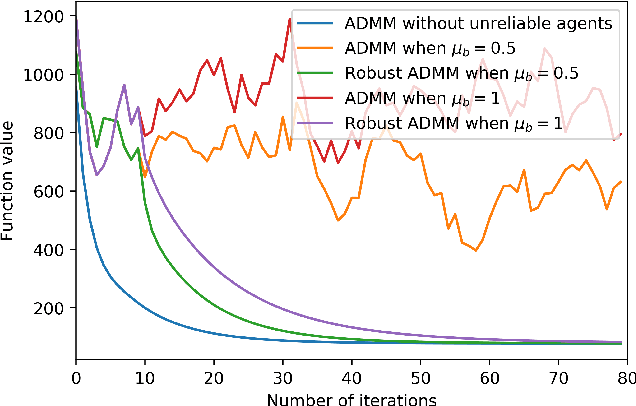
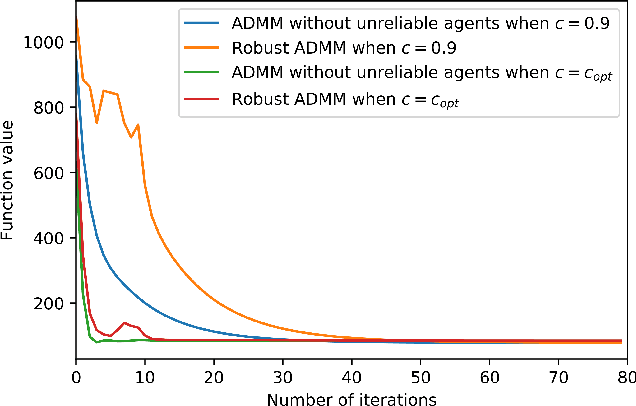
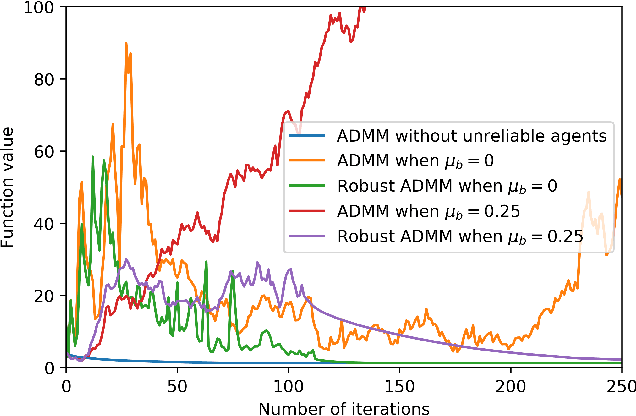
Many machine learning problems can be formulated as consensus optimization problems which can be solved efficiently via a cooperative multi-agent system. However, the agents in the system can be unreliable due to a variety of reasons: noise, faults and attacks. Providing erroneous updates leads the optimization process in a wrong direction, and degrades the performance of distributed machine learning algorithms. This paper considers the problem of decentralized learning using ADMM in the presence of unreliable agents. First, we rigorously analyze the effect of erroneous updates (in ADMM learning iterations) on the convergence behavior of multi-agent system. We show that the algorithm linearly converges to a neighborhood of the optimal solution under certain conditions and characterize the neighborhood size analytically. Next, we provide guidelines for network design to achieve a faster convergence. We also provide conditions on the erroneous updates for exact convergence to the optimal solution. Finally, to mitigate the influence of unreliable agents, we propose \textsf{ROAD}, a robust variant of ADMM, and show its resilience to unreliable agents with an exact convergence to the optimum.
Modeling sepsis progression using hidden Markov models
Jan 09, 2018
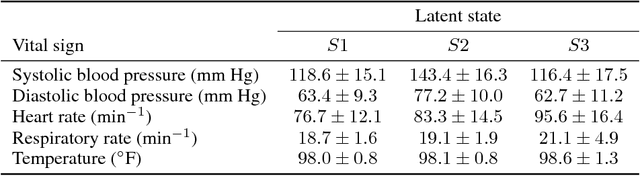
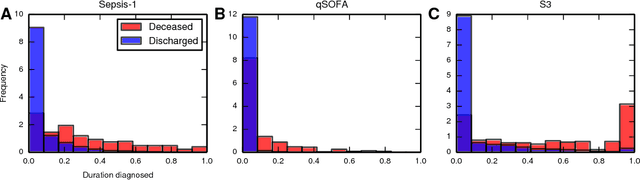
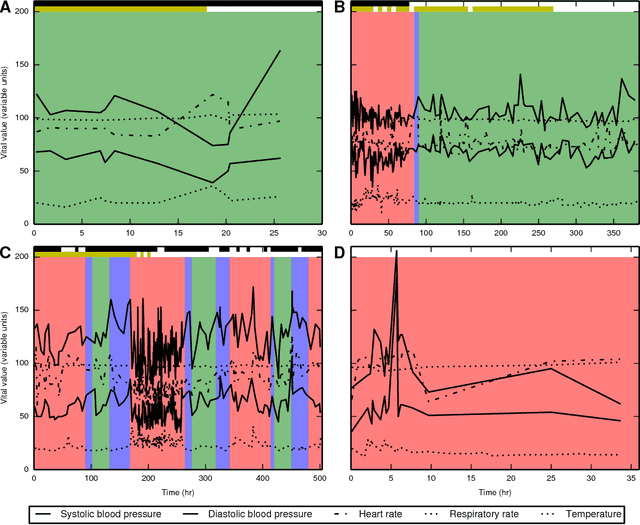
Characterizing a patient's progression through stages of sepsis is critical for enabling risk stratification and adaptive, personalized treatment. However, commonly used sepsis diagnostic criteria fail to account for significant underlying heterogeneity, both between patients as well as over time in a single patient. We introduce a hidden Markov model of sepsis progression that explicitly accounts for patient heterogeneity. Benchmarked against two sepsis diagnostic criteria, the model provides a useful tool to uncover a patient's latent sepsis trajectory and to identify high-risk patients in whom more aggressive therapy may be indicated.