 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Fully Unsupervised Domain Adaptation for Lane Detection in Autonomous Driving
Jun 29, 2023

While deep neural networks are being utilized heavily for autonomous driving, they need to be adapted to new unseen environmental conditions for which they were not trained. We focus on a safety critical application of lane detection, and propose a lightweight, fully unsupervised, real-time adaptation approach that only adapts the batch-normalization parameters of the model. We demonstrate that our technique can perform inference, followed by on-device adaptation, under a tight constraint of 30 FPS on Nvidia Jetson Orin. It shows similar accuracy (avg. of 92.19%) as a state-of-the-art semi-supervised adaptation algorithm but which does not support real-time adaptation.
Less is More: Data Pruning for Faster Adversarial Training
Feb 28, 2023Deep neural networks (DNNs) are sensitive to adversarial examples, resulting in fragile and unreliable performance in the real world. Although adversarial training (AT) is currently one of the most effective methodologies to robustify DNNs, it is computationally very expensive (e.g., 5-10X costlier than standard training). To address this challenge, existing approaches focus on single-step AT, referred to as Fast AT, reducing the overhead of adversarial example generation. Unfortunately, these approaches are known to fail against stronger adversaries. To make AT computationally efficient without compromising robustness, this paper takes a different view of the efficient AT problem. Specifically, we propose to minimize redundancies at the data level by leveraging data pruning. Extensive experiments demonstrate that the data pruning based AT can achieve similar or superior robust (and clean) accuracy as its unpruned counterparts while being significantly faster. For instance, proposed strategies accelerate CIFAR-10 training up to 3.44X and CIFAR-100 training to 2.02X. Additionally, the data pruning methods can readily be reconciled with existing adversarial acceleration tricks to obtain the striking speed-ups of 5.66X and 5.12X on CIFAR-10, 3.67X and 3.07X on CIFAR-100 with TRADES and MART, respectively.
Efficient Multi-Prize Lottery Tickets: Enhanced Accuracy, Training, and Inference Speed
Sep 26, 2022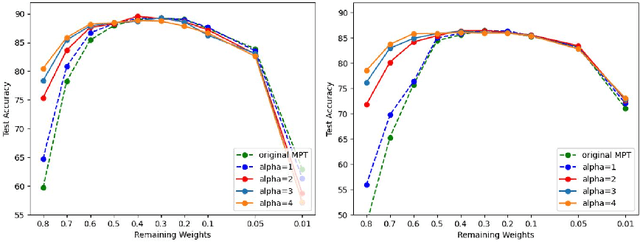
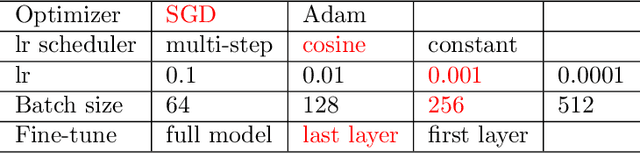


Recently, Diffenderfer and Kailkhura proposed a new paradigm for learning compact yet highly accurate binary neural networks simply by pruning and quantizing randomly weighted full precision neural networks. However, the accuracy of these multi-prize tickets (MPTs) is highly sensitive to the optimal prune ratio, which limits their applicability. Furthermore, the original implementation did not attain any training or inference speed benefits. In this report, we discuss several improvements to overcome these limitations. We show the benefit of the proposed techniques by performing experiments on CIFAR-10.
Mixture of Robust Experts : A Flexible Defense Against Multiple Perturbations
Apr 21, 2021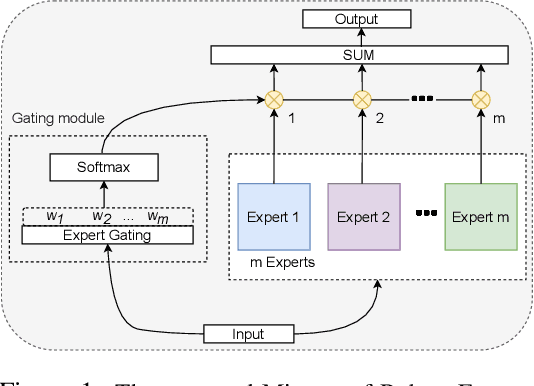
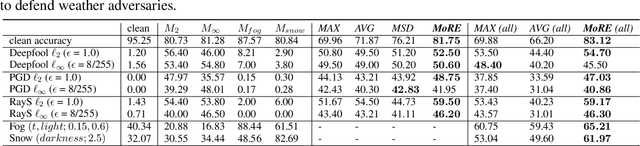
To tackle the susceptibility of deep neural networks to adversarial examples, the adversarial training has been proposed which provides a notion of security through an inner maximization problem presenting the first-order adversaries embedded within the outer minimization of the training loss. To generalize the adversarial robustness over different perturbation types, the adversarial training method has been augmented with the improved inner maximization presenting a union of multiple perturbations e.g., various $\ell_p$ norm-bounded perturbations. However, the improved inner maximization only enjoys limited flexibility in terms of the allowable perturbation types. In this work, through a gating mechanism, we assemble a set of expert networks, each one either adversarially trained to deal with a particular perturbation type or normally trained for boosting accuracy on clean data. The gating module assigns weights dynamically to each expert to achieve superior accuracy under various data types e.g., adversarial examples, adverse weather perturbations, and clean input. In order to deal with the obfuscated gradients issue, the training of the gating module is conducted together with fine-tuning of the last fully connected layers of expert networks through adversarial training approach. Using extensive experiments, we show that our Mixture of Robust Experts (MoRE) approach enables flexible integration of a broad range of robust experts with superior performance.
Certifiably-Robust Federated Adversarial Learning via Randomized Smoothing
Mar 30, 2021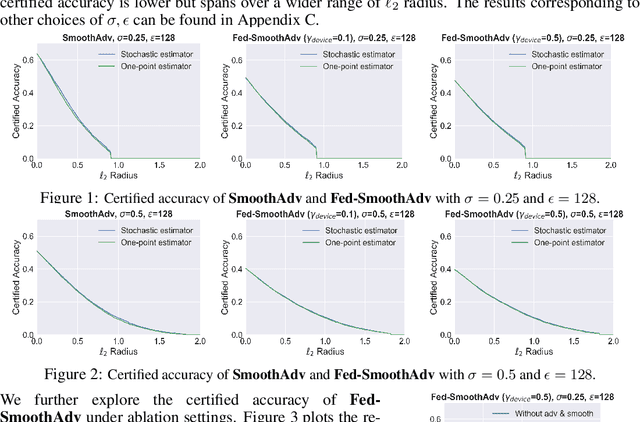


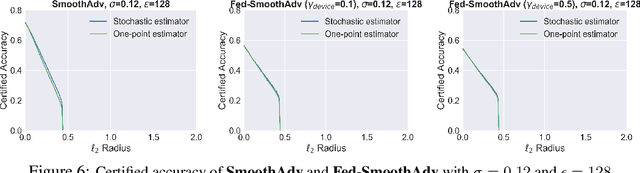
Federated learning is an emerging data-private distributed learning framework, which, however, is vulnerable to adversarial attacks. Although several heuristic defenses are proposed to enhance the robustness of federated learning, they do not provide certifiable robustness guarantees. In this paper, we incorporate randomized smoothing techniques into federated adversarial training to enable data-private distributed learning with certifiable robustness to test-time adversarial perturbations. Our experiments show that such an advanced federated adversarial learning framework can deliver models as robust as those trained by the centralized training. Further, this enables provably-robust classifiers to $\ell_2$-bounded adversarial perturbations in a distributed setup. We also show that one-point gradient estimation based training approach is $2-3\times$ faster than popular stochastic estimator based approach without any noticeable certified robustness differences.
Robust Decentralized Learning Using ADMM with Unreliable Agents
May 21, 2018
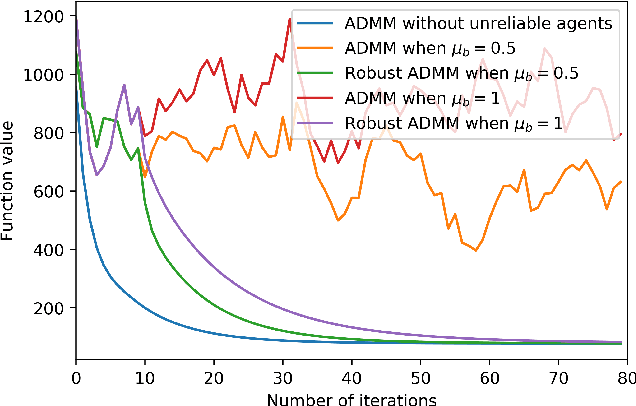
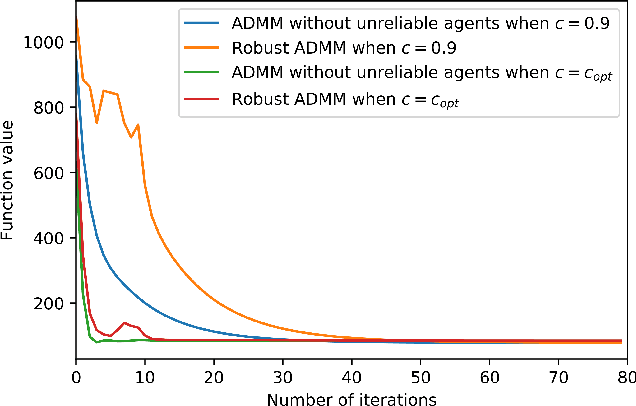
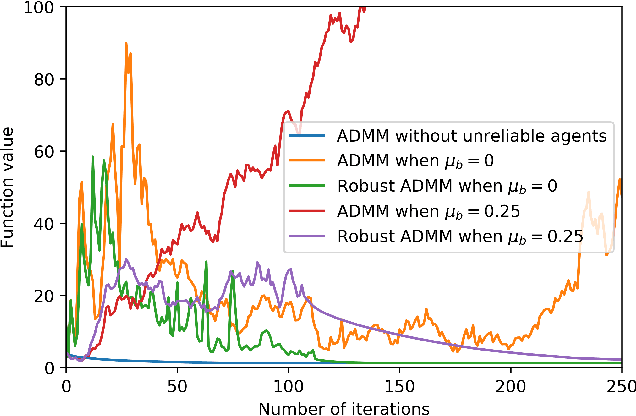
Many machine learning problems can be formulated as consensus optimization problems which can be solved efficiently via a cooperative multi-agent system. However, the agents in the system can be unreliable due to a variety of reasons: noise, faults and attacks. Providing erroneous updates leads the optimization process in a wrong direction, and degrades the performance of distributed machine learning algorithms. This paper considers the problem of decentralized learning using ADMM in the presence of unreliable agents. First, we rigorously analyze the effect of erroneous updates (in ADMM learning iterations) on the convergence behavior of multi-agent system. We show that the algorithm linearly converges to a neighborhood of the optimal solution under certain conditions and characterize the neighborhood size analytically. Next, we provide guidelines for network design to achieve a faster convergence. We also provide conditions on the erroneous updates for exact convergence to the optimal solution. Finally, to mitigate the influence of unreliable agents, we propose \textsf{ROAD}, a robust variant of ADMM, and show its resilience to unreliable agents with an exact convergence to the optimum.