Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multi-Prize Lottery Tickets: Enhanced Accuracy, Training, and Inference Speed
Paper and Code
Sep 26, 2022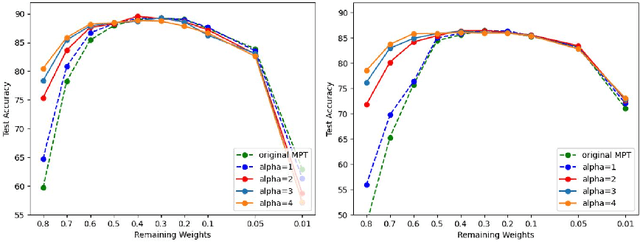
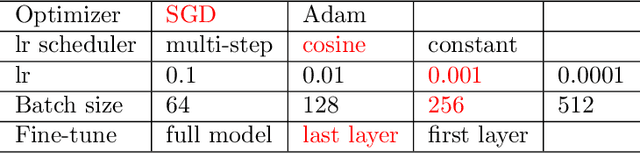


Recently, Diffenderfer and Kailkhura proposed a new paradigm for learning compact yet highly accurate binary neural networks simply by pruning and quantizing randomly weighted full precision neural networks. However, the accuracy of these multi-prize tickets (MPTs) is highly sensitive to the optimal prune ratio, which limits their applicability. Furthermore, the original implementation did not attain any training or inference speed benefits. In this report, we discuss several improvements to overcome these limitations. We show the benefit of the proposed techniques by performing experiments on CIFAR-10.
View paper on