 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Robust Experts : A Flexible Defense Against Multiple Perturbations
Paper and Code
Apr 21, 2021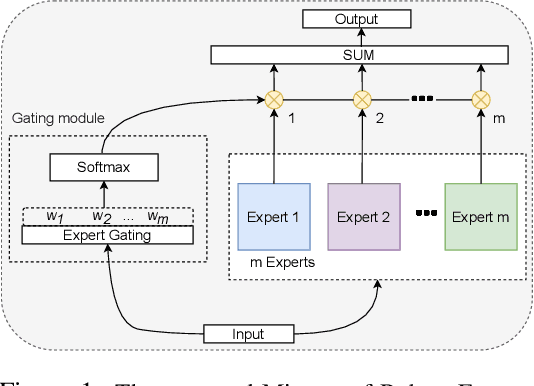
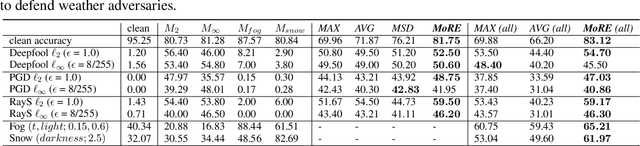
To tackle the susceptibility of deep neural networks to adversarial examples, the adversarial training has been proposed which provides a notion of security through an inner maximization problem presenting the first-order adversaries embedded within the outer minimization of the training loss. To generalize the adversarial robustness over different perturbation types, the adversarial training method has been augmented with the improved inner maximization presenting a union of multiple perturbations e.g., various $\ell_p$ norm-bounded perturbations. However, the improved inner maximization only enjoys limited flexibility in terms of the allowable perturbation types. In this work, through a gating mechanism, we assemble a set of expert networks, each one either adversarially trained to deal with a particular perturbation type or normally trained for boosting accuracy on clean data. The gating module assigns weights dynamically to each expert to achieve superior accuracy under various data types e.g., adversarial examples, adverse weather perturbations, and clean input. In order to deal with the obfuscated gradients issue, the training of the gating module is conducted together with fine-tuning of the last fully connected layers of expert networks through adversarial training approach. Using extensive experiments, we show that our Mixture of Robust Experts (MoRE) approach enables flexible integration of a broad range of robust experts with superior performance.