 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Sampling with Reinforcement Learning
Jan 18, 2026Inference time latency has remained an open challenge for real world applications of large language models (LLMs). State-of-the-art (SOTA) speculative sampling (SpS) methods for LLMs, like EAGLE-3, use tree-based drafting to explore multiple candidate continuations in parallel. However, the hyperparameters controlling the tree structure are static, which limits flexibility and efficiency across diverse contexts and domains. We introduce Reinforcement learning for Speculative Sampling (Re-SpS), the first reinforcement learning (RL)-based framework for draft tree hyperparameter optimization. Re-SpS dynamically adjusts draft tree hyperparameters in real-time, learning context-aware policies that maximize generation speed by balancing speculative aggression with computational overhead. It leverages efficient state representations from target model hidden states and introduces multi-step action persistence for better context modeling. Evaluation results across five diverse benchmarks demonstrate consistent improvements over the SOTA method EAGLE-3, achieving up to 5.45$\times$ speedup over the backbone LLM and up to 1.12$\times$ speedup compared to EAGLE-3 across five diverse benchmarks, with no loss in output fidelity.
DIP: Dynamic In-Context Planner For Diffusion Language Models
Jan 06, 2026Diffusion language models (DLMs) have shown strong potential for general natural language tasks with in-context examples. However, due to the bidirectional attention mechanism, DLMs incur substantial computational cost as context length increases. This work addresses this issue with a key discovery: unlike the sequential generation in autoregressive language models (ARLMs), the diffusion generation paradigm in DLMs allows \textit{efficient dynamic adjustment of the context} during generation. Building on this insight, we propose \textbf{D}ynamic \textbf{I}n-Context \textbf{P}lanner (DIP), a context-optimization method that dynamically selects and inserts in-context examples during generation, rather than providing all examples in the prompt upfront. Results show DIP maintains generation quality while achieving up to 12.9$\times$ inference speedup over standard inference and 1.17$\times$ over KV cache-enhanced inference.
GuideLLM: Exploring LLM-Guided Conversation with Applications in Autobiography Interviewing
Feb 10, 2025



Although Large Language Models (LLMs) succeed in human-guided conversations such as instruction following and question answering, the potential of LLM-guided conversations-where LLMs direct the discourse and steer the conversation's objectives-remains under-explored. In this study, we first characterize LLM-guided conversation into three fundamental components: (i) Goal Navigation; (ii) Context Management; (iii) Empathetic Engagement, and propose GuideLLM as an installation. We then implement an interviewing environment for the evaluation of LLM-guided conversation. Specifically, various topics are involved in this environment for comprehensive interviewing evaluation, resulting in around 1.4k turns of utterances, 184k tokens, and over 200 events mentioned during the interviewing for each chatbot evaluation. We compare GuideLLM with 6 state-of-the-art LLMs such as GPT-4o and Llama-3-70b-Instruct, from the perspective of interviewing quality, and autobiography generation quality. For automatic evaluation, we derive user proxies from multiple autobiographies and employ LLM-as-a-judge to score LLM behaviors. We further conduct a human-involved experiment by employing 45 human participants to chat with GuideLLM and baselines. We then collect human feedback, preferences, and ratings regarding the qualities of conversation and autobiography. Experimental results indicate that GuideLLM significantly outperforms baseline LLMs in automatic evaluation and achieves consistent leading performances in human ratings.
Detection and Recovery Against Deep Neural Network Fault Injection Attacks Based on Contrastive Learning
Jan 30, 2024Deep Neural Network (DNN) models when implemented on executing devices as the inference engines are susceptible to Fault Injection Attacks (FIAs) that manipulate model parameters to disrupt inference execution with disastrous performance. This work introduces Contrastive Learning (CL) of visual representations i.e., a self-supervised learning approach into the deep learning training and inference pipeline to implement DNN inference engines with self-resilience under FIAs. Our proposed CL based FIA Detection and Recovery (CFDR) framework features (i) real-time detection with only a single batch of testing data and (ii) fast recovery effective even with only a small amount of unlabeled testing data. Evaluated with the CIFAR-10 dataset on multiple types of FIAs, our CFDR shows promising detection and recovery effectiveness.
Dynamic Adversarial Attacks on Autonomous Driving Systems
Dec 10, 2023This paper introduces an attacking mechanism to challenge the resilience of autonomous driving systems. Specifically, we manipulate the decision-making processes of an autonomous vehicle by dynamically displaying adversarial patches on a screen mounted on another moving vehicle. These patches are optimized to deceive the object detection models into misclassifying targeted objects, e.g., traffic signs. Such manipulation has significant implications for critical multi-vehicle interactions such as intersection crossing and lane changing, which are vital for safe and efficient autonomous driving systems. Particularly, we make four major contributions. First, we introduce a novel adversarial attack approach where the patch is not co-located with its target, enabling more versatile and stealthy attacks. Moreover, our method utilizes dynamic patches displayed on a screen, allowing for adaptive changes and movement, enhancing the flexibility and performance of the attack. To do so, we design a Screen Image Transformation Network (SIT-Net), which simulates environmental effects on the displayed images, narrowing the gap between simulated and real-world scenarios. Further, we integrate a positional loss term into the adversarial training process to increase the success rate of the dynamic attack. Finally, we shift the focus from merely attacking perceptual systems to influencing the decision-making algorithms of self-driving systems. Our experiments demonstrate the first successful implementation of such dynamic adversarial attacks in real-world autonomous driving scenarios, paving the way for advancements in the field of robust and secure autonomous driving.
Can Protective Perturbation Safeguard Personal Data from Being Exploited by Stable Diffusion?
Nov 30, 2023Stable Diffusion has established itself as a foundation model in generative AI artistic applications, receiving widespread research and application. Some recent fine-tuning methods have made it feasible for individuals to implant personalized concepts onto the basic Stable Diffusion model with minimal computational costs on small datasets. However, these innovations have also given rise to issues like facial privacy forgery and artistic copyright infringement. In recent studies, researchers have explored the addition of imperceptible adversarial perturbations to images to prevent potential unauthorized exploitation and infringements when personal data is used for fine-tuning Stable Diffusion. Although these studies have demonstrated the ability to protect images, it is essential to consider that these methods may not be entirely applicable in real-world scenarios. In this paper, we systematically evaluate the use of perturbations to protect images within a practical threat model. The results suggest that these approaches may not be sufficient to safeguard image privacy and copyright effectively. Furthermore, we introduce a purification method capable of removing protected perturbations while preserving the original image structure to the greatest extent possible. Experiments reveal that Stable Diffusion can effectively learn from purified images over all protective methods.
Semantic Adversarial Attacks via Diffusion Models
Sep 14, 2023Traditional adversarial attacks concentrate on manipulating clean examples in the pixel space by adding adversarial perturbations. By contrast, semantic adversarial attacks focus on changing semantic attributes of clean examples, such as color, context, and features, which are more feasible in the real world. In this paper, we propose a framework to quickly generate a semantic adversarial attack by leveraging recent diffusion models since semantic information is included in the latent space of well-trained diffusion models. Then there are two variants of this framework: 1) the Semantic Transformation (ST) approach fine-tunes the latent space of the generated image and/or the diffusion model itself; 2) the Latent Masking (LM) approach masks the latent space with another target image and local backpropagation-based interpretation methods. Additionally, the ST approach can be applied in either white-box or black-box settings. Extensive experiments are conducted on CelebA-HQ and AFHQ datasets, and our framework demonstrates great fidelity, generalizability, and transferability compared to other baselines. Our approaches achieve approximately 100% attack success rate in multiple settings with the best FID as 36.61. Code is available at https://github.com/steven202/semantic_adv_via_dm.
Shifting Attention to Relevance: Towards the Uncertainty Estimation of Large Language Models
Jul 03, 2023



Although Large Language Models (LLMs) have shown great potential in Natural Language Generation, it is still challenging to characterize the uncertainty of model generations, i.e., when users could trust model outputs. Our research is derived from the heuristic facts that tokens are created unequally in reflecting the meaning of generations by auto-regressive LLMs, i.e., some tokens are more relevant (or representative) than others, yet all the tokens are equally valued when estimating uncertainty. It is because of the linguistic redundancy where mostly a few keywords are sufficient to convey the meaning of a long sentence. We name these inequalities as generative inequalities and investigate how they affect uncertainty estimation. Our results reveal that considerable tokens and sentences containing limited semantics are weighted equally or even heavily when estimating uncertainty. To tackle these biases posed by generative inequalities, we propose to jointly Shifting Attention to more Relevant (SAR) components from both the token level and the sentence level while estimating uncertainty. We conduct experiments over popular "off-the-shelf" LLMs (e.g., OPT, LLaMA) with model sizes up to 30B and powerful commercial LLMs (e.g., Davinci from OpenAI), across various free-form question-answering tasks. Experimental results and detailed demographic analysis indicate the superior performance of SAR. Code is available at https://github.com/jinhaoduan/shifting-attention-to-relevance.
Unlearnable Examples for Diffusion Models: Protect Data from Unauthorized Exploitation
Jun 02, 2023



Diffusion models have demonstrated remarkable performance in image generation tasks, paving the way for powerful AIGC applications. However, these widely-used generative models can also raise security and privacy concerns, such as copyright infringement, and sensitive data leakage. To tackle these issues, we propose a method, Unlearnable Diffusion Perturbation, to safeguard images from unauthorized exploitation. Our approach involves designing an algorithm to generate sample-wise perturbation noise for each image to be protected. This imperceptible protective noise makes the data almost unlearnable for diffusion models, i.e., diffusion models trained or fine-tuned on the protected data cannot generate high-quality and diverse images related to the protected training data. Theoretically, we frame this as a max-min optimization problem and introduce EUDP, a noise scheduler-based method to enhance the effectiveness of the protective noise. We evaluate our methods on both Denoising Diffusion Probabilistic Model and Latent Diffusion Models, demonstrating that training diffusion models on the protected data lead to a significant reduction in the quality of the generated images. Especially, the experimental results on Stable Diffusion demonstrate that our method effectively safeguards images from being used to train Diffusion Models in various tasks, such as training specific objects and styles. This achievement holds significant importance in real-world scenarios, as it contributes to the protection of privacy and copyright against AI-generated content.
Mixture of Robust Experts : A Flexible Defense Against Multiple Perturbations
Apr 21, 2021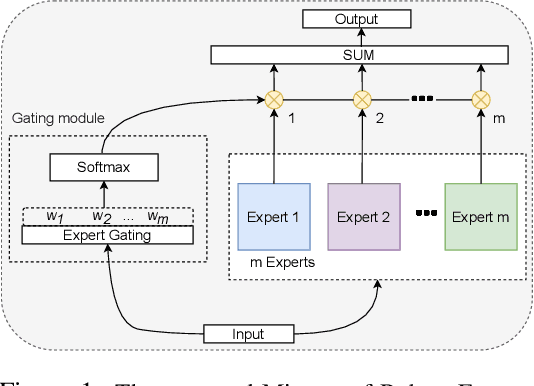
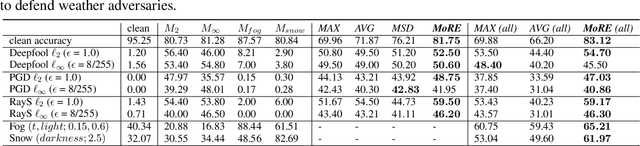
To tackle the susceptibility of deep neural networks to adversarial examples, the adversarial training has been proposed which provides a notion of security through an inner maximization problem presenting the first-order adversaries embedded within the outer minimization of the training loss. To generalize the adversarial robustness over different perturbation types, the adversarial training method has been augmented with the improved inner maximization presenting a union of multiple perturbations e.g., various $\ell_p$ norm-bounded perturbations. However, the improved inner maximization only enjoys limited flexibility in terms of the allowable perturbation types. In this work, through a gating mechanism, we assemble a set of expert networks, each one either adversarially trained to deal with a particular perturbation type or normally trained for boosting accuracy on clean data. The gating module assigns weights dynamically to each expert to achieve superior accuracy under various data types e.g., adversarial examples, adverse weather perturbations, and clean input. In order to deal with the obfuscated gradients issue, the training of the gating module is conducted together with fine-tuning of the last fully connected layers of expert networks through adversarial training approach. Using extensive experiments, we show that our Mixture of Robust Experts (MoRE) approach enables flexible integration of a broad range of robust experts with superior performance.