 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasonDrive: Efficient Visual Question Answering for Autonomous Vehicles with Reasoning-Enhanced Small Vision-Language Models
Apr 14, 2025
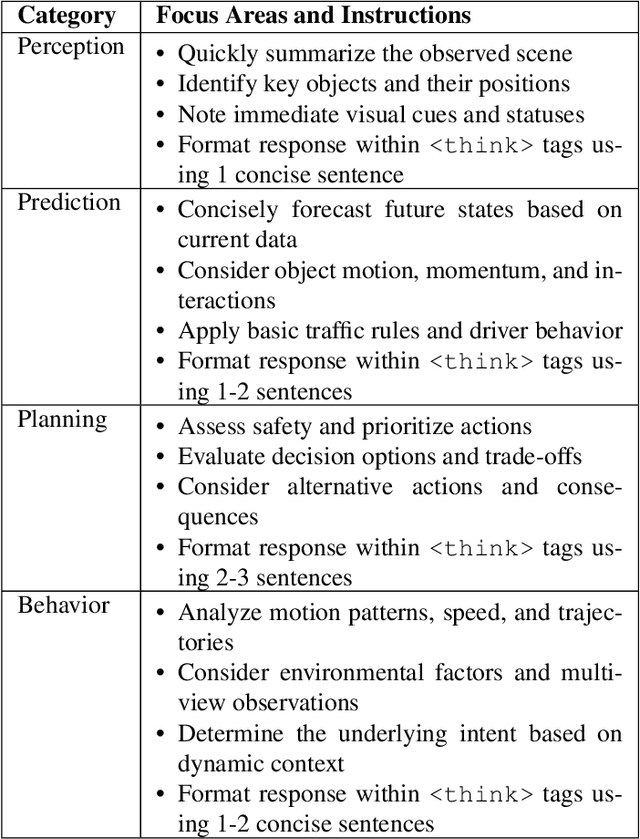


Vision-language models (VLMs) show promise for autonomous driving but often lack transparent reasoning capabilities that are critical for safety. We investigate whether explicitly modeling reasoning during fine-tuning enhances VLM performance on driving decision tasks. Using GPT-4o, we generate structured reasoning chains for driving scenarios from the DriveLM benchmark with category-specific prompting strategies. We compare reasoning-based fine-tuning, answer-only fine-tuning, and baseline instruction-tuned models across multiple small VLM families (Llama 3.2, Llava 1.5, and Qwen 2.5VL). Our results demonstrate that reasoning-based fine-tuning consistently outperforms alternatives, with Llama3.2-11B-reason achieving the highest performance. Models fine-tuned with reasoning show substantial improvements in accuracy and text generation quality, suggesting explicit reasoning enhances internal representations for driving decisions. These findings highlight the importance of transparent decision processes in safety-critical domains and offer a promising direction for developing more interpretable autonomous driving systems.
Leveraging LLMs for Enhanced Open-Vocabulary 3D Scene Understanding in Autonomous Driving
Aug 07, 2024



This paper introduces a novel method for open-vocabulary 3D scene understanding in autonomous driving by combining Language Embedded 3D Gaussians with Large Language Models (LLMs) for enhanced inference. We propose utilizing LLMs to generate contextually relevant canonical phrases for segmentation and scene interpretation. Our method leverages the contextual and semantic capabilities of LLMs to produce a set of canonical phrases, which are then compared with the language features embedded in the 3D Gaussians. This LLM-guided approach significantly improves zero-shot scene understanding and detection of objects of interest, even in the most challenging or unfamiliar environments. Experimental results on the WayveScenes101 dataset demonstrate that our approach surpasses state-of-the-art methods in terms of accuracy and flexibility for open-vocabulary object detection and segmentation. This work represents a significant advancement towards more intelligent, context-aware autonomous driving systems, effectively bridging 3D scene representation with high-level semantic understanding.
Dynamic Adversarial Attacks on Autonomous Driving Systems
Dec 10, 2023This paper introduces an attacking mechanism to challenge the resilience of autonomous driving systems. Specifically, we manipulate the decision-making processes of an autonomous vehicle by dynamically displaying adversarial patches on a screen mounted on another moving vehicle. These patches are optimized to deceive the object detection models into misclassifying targeted objects, e.g., traffic signs. Such manipulation has significant implications for critical multi-vehicle interactions such as intersection crossing and lane changing, which are vital for safe and efficient autonomous driving systems. Particularly, we make four major contributions. First, we introduce a novel adversarial attack approach where the patch is not co-located with its target, enabling more versatile and stealthy attacks. Moreover, our method utilizes dynamic patches displayed on a screen, allowing for adaptive changes and movement, enhancing the flexibility and performance of the attack. To do so, we design a Screen Image Transformation Network (SIT-Net), which simulates environmental effects on the displayed images, narrowing the gap between simulated and real-world scenarios. Further, we integrate a positional loss term into the adversarial training process to increase the success rate of the dynamic attack. Finally, we shift the focus from merely attacking perceptual systems to influencing the decision-making algorithms of self-driving systems. Our experiments demonstrate the first successful implementation of such dynamic adversarial attacks in real-world autonomous driving scenarios, paving the way for advancements in the field of robust and secure autonomous driving.