 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking the Invisible Visible: Understanding the Mismatch Between Organizational Goals and Worker Experiences in AI Adoption
May 04, 2026While AI is often introduced into organizations to drive innovation and efficiency, many adoption efforts fail as workers resist and struggle to integrate these systems. These failures point to a deeper issue: workers, the very people expected to collaborate with AI, are often invisible in decisions about how AI is designed and used. Drawing on interviews with professionals who interact with AI systems daily in healthcare, finance, and management, we examine the disconnect between organizational expectations and worker experiences. We identify key barriers, including poor usability and interoperability, misaligned expectations, limited control, and insufficient communication. These challenges highlight a gap between how organizations implement AI and the evolving worker needs, tasks, and workflows that it fails to support. We argue that successful adoption requires recognizing workers as central to AI integration and propose adaptation strategies at the individual, task, and organizational levels to better align AI systems with real-world practices.
State Your Intention to Steer Your Attention: An AI Assistant for Intentional Digital Living
Oct 16, 2025When working on digital devices, people often face distractions that can lead to a decline in productivity and efficiency, as well as negative psychological and emotional impacts. To address this challenge, we introduce a novel Artificial Intelligence (AI) assistant that elicits a user's intention, assesses whether ongoing activities are in line with that intention, and provides gentle nudges when deviations occur. The system leverages a large language model to analyze screenshots, application titles, and URLs, issuing notifications when behavior diverges from the stated goal. Its detection accuracy is refined through initial clarification dialogues and continuous user feedback. In a three-week, within-subjects field deployment with 22 participants, we compared our assistant to both a rule-based intent reminder system and a passive baseline that only logged activity. Results indicate that our AI assistant effectively supports users in maintaining focus and aligning their digital behavior with their intentions. Our source code is publicly available at this url https://intentassistant.github.io
GuideLLM: Exploring LLM-Guided Conversation with Applications in Autobiography Interviewing
Feb 10, 2025



Although Large Language Models (LLMs) succeed in human-guided conversations such as instruction following and question answering, the potential of LLM-guided conversations-where LLMs direct the discourse and steer the conversation's objectives-remains under-explored. In this study, we first characterize LLM-guided conversation into three fundamental components: (i) Goal Navigation; (ii) Context Management; (iii) Empathetic Engagement, and propose GuideLLM as an installation. We then implement an interviewing environment for the evaluation of LLM-guided conversation. Specifically, various topics are involved in this environment for comprehensive interviewing evaluation, resulting in around 1.4k turns of utterances, 184k tokens, and over 200 events mentioned during the interviewing for each chatbot evaluation. We compare GuideLLM with 6 state-of-the-art LLMs such as GPT-4o and Llama-3-70b-Instruct, from the perspective of interviewing quality, and autobiography generation quality. For automatic evaluation, we derive user proxies from multiple autobiographies and employ LLM-as-a-judge to score LLM behaviors. We further conduct a human-involved experiment by employing 45 human participants to chat with GuideLLM and baselines. We then collect human feedback, preferences, and ratings regarding the qualities of conversation and autobiography. Experimental results indicate that GuideLLM significantly outperforms baseline LLMs in automatic evaluation and achieves consistent leading performances in human ratings.
The AI-DEC: A Card-based Design Method for User-centered AI Explanations
May 26, 2024



Increasing evidence suggests that many deployed AI systems do not sufficiently support end-user interaction and information needs. Engaging end-users in the design of these systems can reveal user needs and expectations, yet effective ways of engaging end-users in the AI explanation design remain under-explored. To address this gap, we developed a design method, called AI-DEC, that defines four dimensions of AI explanations that are critical for the integration of AI systems -- communication content, modality, frequency, and direction -- and offers design examples for end-users to design AI explanations that meet their needs. We evaluated this method through co-design sessions with workers in healthcare, finance, and management industries who regularly use AI systems in their daily work. Findings indicate that the AI-DEC effectively supported workers in designing explanations that accommodated diverse levels of performance and autonomy needs, which varied depending on the AI system's workplace role and worker values. We discuss the implications of using the AI-DEC for the user-centered design of AI explanations in real-world systems.
Human-centered NLP Fact-checking: Co-Designing with Fact-checkers using Matchmaking for AI
Aug 14, 2023



A key challenge in professional fact-checking is its limited scalability in relation to the magnitude of false information. While many Natural Language Processing (NLP) tools have been proposed to enhance fact-checking efficiency and scalability, both academic research and fact-checking organizations report limited adoption of such tooling due to insufficient alignment with fact-checker practices, values, and needs. To address this gap, we investigate a co-design method, Matchmaking for AI, which facilitates fact-checkers, designers, and NLP researchers to collaboratively discover what fact-checker needs should be addressed by technology and how. Our co-design sessions with 22 professional fact-checkers yielded a set of 11 novel design ideas. They assist in information searching, processing, and writing tasks for efficient and personalized fact-checking; help fact-checkers proactively prepare for future misinformation; monitor their potential biases; and support internal organization collaboration. Our work offers implications for human-centered fact-checking research and practice and AI co-design research.
Learning Complementary Policies for Human-AI Teams
Feb 06, 2023

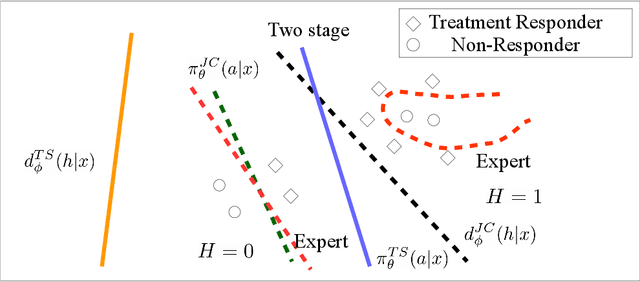
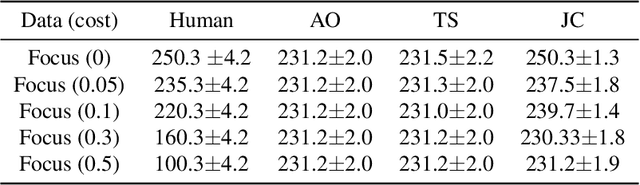
Human-AI complementarity is important when neither the algorithm nor the human yields dominant performance across all instances in a given context. Recent work that explored human-AI collaboration has considered decisions that correspond to classification tasks. However, in many important contexts where humans can benefit from AI complementarity, humans undertake course of action. In this paper, we propose a framework for a novel human-AI collaboration for selecting advantageous course of action, which we refer to as Learning Complementary Policy for Human-AI teams (\textsc{lcp-hai}). Our solution aims to exploit the human-AI complementarity to maximize decision rewards by learning both an algorithmic policy that aims to complement humans by a routing model that defers decisions to either a human or the AI to leverage the resulting complementarity. We then extend our approach to leverage opportunities and mitigate risks that arise in important contexts in practice: 1) when a team is composed of multiple humans with differential and potentially complementary abilities, 2) when the observational data includes consistent deterministic actions, and 3) when the covariate distribution of future decisions differ from that in the historical data. We demonstrate the effectiveness of our proposed methods using data on real human responses and semi-synthetic, and find that our methods offer reliable and advantageous performance across setting, and that it is superior to when either the algorithm or the AI make decisions on their own. We also find that the extensions we propose effectively improve the robustness of the human-AI collaboration performance in the presence of different challenging settings.
Policy Optimization with Advantage Regularization for Long-Term Fairness in Decision Systems
Oct 22, 2022



Long-term fairness is an important factor of consideration in designing and deploying learning-based decision systems in high-stake decision-making contexts. Recent work has proposed the use of Markov Decision Processes (MDPs) to formulate decision-making with long-term fairness requirements in dynamically changing environments, and demonstrated major challenges in directly deploying heuristic and rule-based policies that worked well in static environments. We show that policy optimization methods from deep reinforcement learning can be used to find strictly better decision policies that can often achieve both higher overall utility and less violation of the fairness requirements, compared to previously-known strategies. In particular, we propose new methods for imposing fairness requirements in policy optimization by regularizing the advantage evaluation of different actions. Our proposed methods make it easy to impose fairness constraints without reward engineering or sacrificing training efficiency. We perform detailed analyses in three established case studies, including attention allocation in incident monitoring, bank loan approval, and vaccine distribution in population networks.