 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEEV: Synthesis with Efficient Exact Verification for ReLU Neural Barrier Functions
Oct 27, 2024



Neural Control Barrier Functions (NCBFs) have shown significant promise in enforcing safety constraints on nonlinear autonomous systems. State-of-the-art exact approaches to verifying safety of NCBF-based controllers exploit the piecewise-linear structure of ReLU neural networks, however, such approaches still rely on enumerating all of the activation regions of the network near the safety boundary, thus incurring high computation cost. In this paper, we propose a framework for Synthesis with Efficient Exact Verification (SEEV). Our framework consists of two components, namely (i) an NCBF synthesis algorithm that introduces a novel regularizer to reduce the number of activation regions at the safety boundary, and (ii) a verification algorithm that exploits tight over-approximations of the safety conditions to reduce the cost of verifying each piecewise-linear segment. Our simulations show that SEEV significantly improves verification efficiency while maintaining the CBF quality across various benchmark systems and neural network structures. Our code is available at https://github.com/HongchaoZhang-HZ/SEEV.
Sample-and-Bound for Non-Convex Optimization
Jan 13, 2024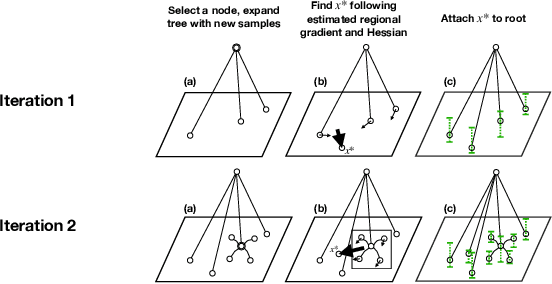
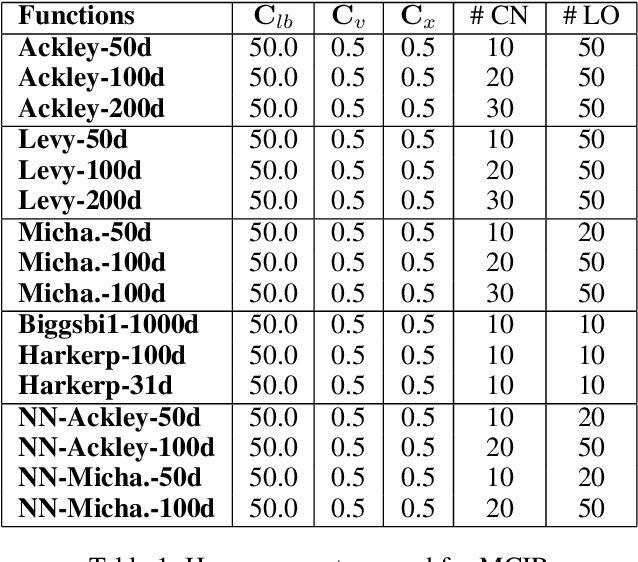
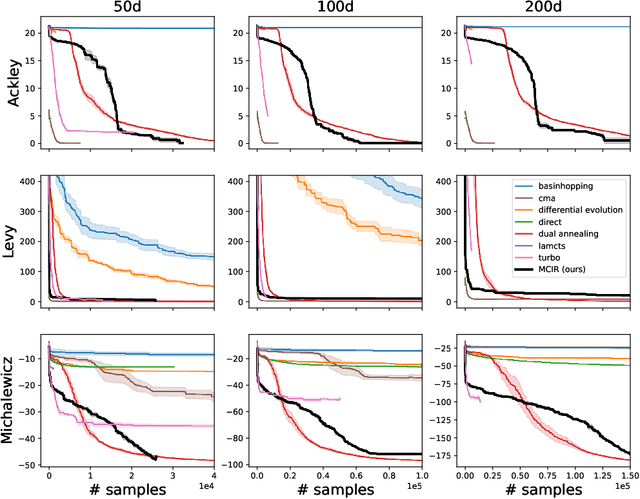
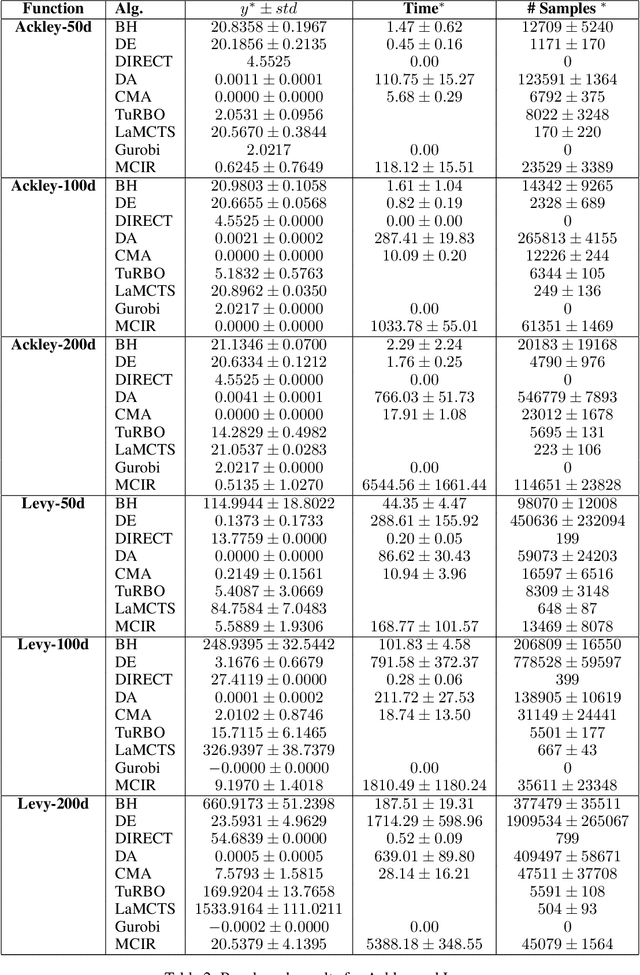
Standard approaches for global optimization of non-convex functions, such as branch-and-bound, maintain partition trees to systematically prune the domain. The tree size grows exponentially in the number of dimensions. We propose new sampling-based methods for non-convex optimization that adapts Monte Carlo Tree Search (MCTS) to improve efficiency. Instead of the standard use of visitation count in Upper Confidence Bounds, we utilize numerical overapproximations of the objective as an uncertainty metric, and also take into account of sampled estimates of first-order and second-order information. The Monte Carlo tree in our approach avoids the usual fixed combinatorial patterns in growing the tree, and aggressively zooms into the promising regions, while still balancing exploration and exploitation. We evaluate the proposed algorithms on high-dimensional non-convex optimization benchmarks against competitive baselines and analyze the effects of the hyper parameters.
Patching Neural Barrier Functions Using Hamilton-Jacobi Reachability
Apr 19, 2023



Learning-based control algorithms have led to major advances in robotics at the cost of decreased safety guarantees. Recently, neural networks have also been used to characterize safety through the use of barrier functions for complex nonlinear systems. Learned barrier functions approximately encode and enforce a desired safety constraint through a value function, but do not provide any formal guarantees. In this paper, we propose a local dynamic programming (DP) based approach to "patch" an almost-safe learned barrier at potentially unsafe points in the state space. This algorithm, HJ-Patch, obtains a novel barrier that provides formal safety guarantees, yet retains the global structure of the learned barrier. Our local DP based reachability algorithm, HJ-Patch, updates the barrier function "minimally" at points that both (a) neighbor the barrier safety boundary and (b) do not satisfy the safety condition. We view this as a key step to bridging the gap between learning-based barrier functions and Hamilton-Jacobi reachability analysis, providing a framework for further integration of these approaches. We demonstrate that for well-trained barriers we reduce the computational load by 2 orders of magnitude with respect to standard DP-based reachability, and demonstrate scalability to a 6-dimensional system, which is at the limit of standard DP-based reachability.
Policy Optimization with Advantage Regularization for Long-Term Fairness in Decision Systems
Oct 22, 2022Long-term fairness is an important factor of consideration in designing and deploying learning-based decision systems in high-stake decision-making contexts. Recent work has proposed the use of Markov Decision Processes (MDPs) to formulate decision-making with long-term fairness requirements in dynamically changing environments, and demonstrated major challenges in directly deploying heuristic and rule-based policies that worked well in static environments. We show that policy optimization methods from deep reinforcement learning can be used to find strictly better decision policies that can often achieve both higher overall utility and less violation of the fairness requirements, compared to previously-known strategies. In particular, we propose new methods for imposing fairness requirements in policy optimization by regularizing the advantage evaluation of different actions. Our proposed methods make it easy to impose fairness constraints without reward engineering or sacrificing training efficiency. We perform detailed analyses in three established case studies, including attention allocation in incident monitoring, bank loan approval, and vaccine distribution in population networks.
Quantifying Safety of Learning-based Self-Driving Control Using Almost-Barrier Functions
Aug 08, 2022

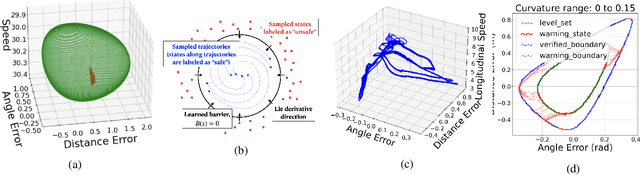
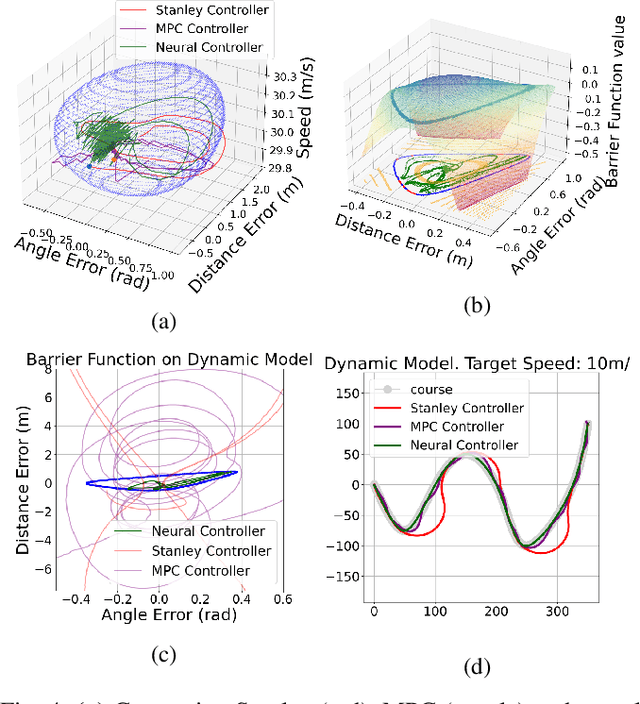
Path-tracking control of self-driving vehicles can benefit from deep learning for tackling longstanding challenges such as nonlinearity and uncertainty. However, deep neural controllers lack safety guarantees, restricting their practical use. We propose a new approach of learning almost-barrier functions, which approximately characterizes the forward invariant set for the system under neural controllers, to quantitatively analyze the safety of deep neural controllers for path-tracking. We design sampling-based learning procedures for constructing candidate neural barrier functions, and certification procedures that utilize robustness analysis for neural networks to identify regions where the barrier conditions are fully satisfied. We use an adversarial training loop between learning and certification to optimize the almost-barrier functions. The learned barrier can also be used to construct online safety monitors through reachability analysis. We demonstrate effectiveness of our methods in quantifying safety of neural controllers in various simulation environments, ranging from simple kinematic models to the TORCS simulator with high-fidelity vehicle dynamics simulation.