 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-centered NLP Fact-checking: Co-Designing with Fact-checkers using Matchmaking for AI
Aug 14, 2023



A key challenge in professional fact-checking is its limited scalability in relation to the magnitude of false information. While many Natural Language Processing (NLP) tools have been proposed to enhance fact-checking efficiency and scalability, both academic research and fact-checking organizations report limited adoption of such tooling due to insufficient alignment with fact-checker practices, values, and needs. To address this gap, we investigate a co-design method, Matchmaking for AI, which facilitates fact-checkers, designers, and NLP researchers to collaboratively discover what fact-checker needs should be addressed by technology and how. Our co-design sessions with 22 professional fact-checkers yielded a set of 11 novel design ideas. They assist in information searching, processing, and writing tasks for efficient and personalized fact-checking; help fact-checkers proactively prepare for future misinformation; monitor their potential biases; and support internal organization collaboration. Our work offers implications for human-centered fact-checking research and practice and AI co-design research.
The State of Human-centered NLP Technology for Fact-checking
Jan 08, 2023

Misinformation threatens modern society by promoting distrust in science, changing narratives in public health, heightening social polarization, and disrupting democratic elections and financial markets, among a myriad of other societal harms. To address this, a growing cadre of professional fact-checkers and journalists provide high-quality investigations into purported facts. However, these largely manual efforts have struggled to match the enormous scale of the problem. In response, a growing body of Natural Language Processing (NLP) technologies have been proposed for more scalable fact-checking. Despite tremendous growth in such research, however, practical adoption of NLP technologies for fact-checking still remains in its infancy today. In this work, we review the capabilities and limitations of the current NLP technologies for fact-checking. Our particular focus is to further chart the design space for how these technologies can be harnessed and refined in order to better meet the needs of human fact-checkers. To do so, we review key aspects of NLP-based fact-checking: task formulation, dataset construction, modeling, and human-centered strategies, such as explainable models and human-in-the-loop approaches. Next, we review the efficacy of applying NLP-based fact-checking tools to assist human fact-checkers. We recommend that future research include collaboration with fact-checker stakeholders early on in NLP research, as well as incorporation of human-centered design practices in model development, in order to further guide technology development for human use and practical adoption. Finally, we advocate for more research on benchmark development supporting extrinsic evaluation of human-centered fact-checking technologies.
* Published in Machine and Human Factors in Misinformation Management -- a special issue of Information Processing and Management
longhorns at DADC 2022: How many linguists does it take to fool a Question Answering model? A systematic approach to adversarial attacks
Jun 29, 2022



Developing methods to adversarially challenge NLP systems is a promising avenue for improving both model performance and interpretability. Here, we describe the approach of the team "longhorns" on Task 1 of the The First Workshop on Dynamic Adversarial Data Collection (DADC), which asked teams to manually fool a model on an Extractive Question Answering task. Our team finished first, with a model error rate of 62%. We advocate for a systematic, linguistically informed approach to formulating adversarial questions, and we describe the results of our pilot experiments, as well as our official submission.
ProtoTEx: Explaining Model Decisions with Prototype Tensors
Apr 11, 2022
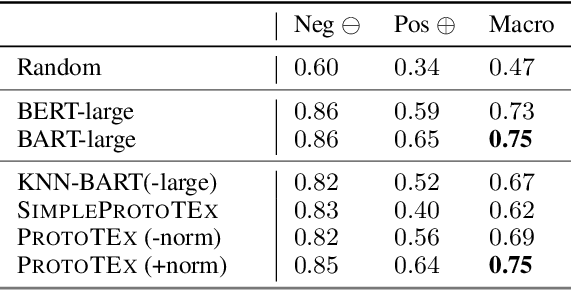


We present ProtoTEx, a novel white-box NLP classification architecture based on prototype networks. ProtoTEx faithfully explains model decisions based on prototype tensors that encode latent clusters of training examples. At inference time, classification decisions are based on the distances between the input text and the prototype tensors, explained via the training examples most similar to the most influential prototypes. We also describe a novel interleaved training algorithm that effectively handles classes characterized by the absence of indicative features. On a propaganda detection task, ProtoTEx accuracy matches BART-large and exceeds BERT-large with the added benefit of providing faithful explanations. A user study also shows that prototype-based explanations help non-experts to better recognize propaganda in online news.
The Effects of Interactive AI Design on User Behavior: An Eye-tracking Study of Fact-checking COVID-19 Claims
Feb 17, 2022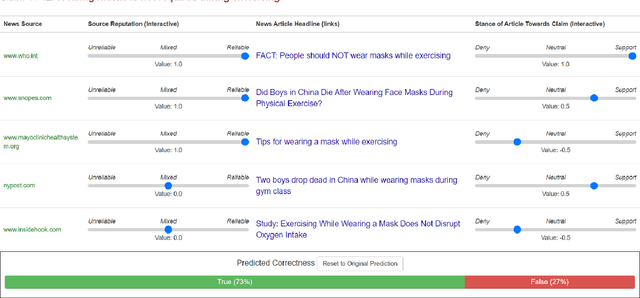
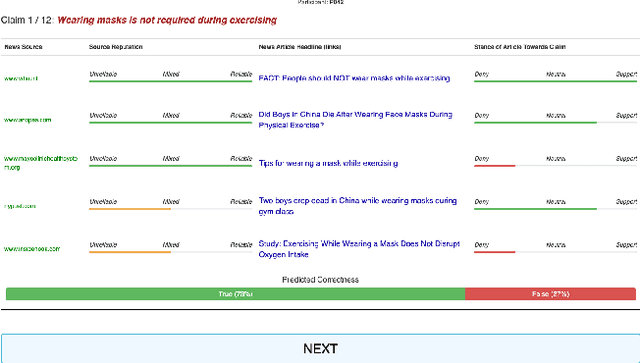
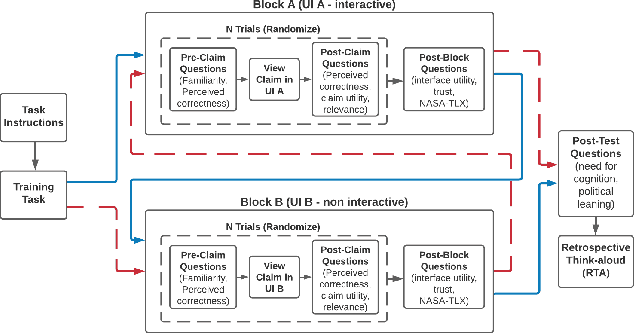
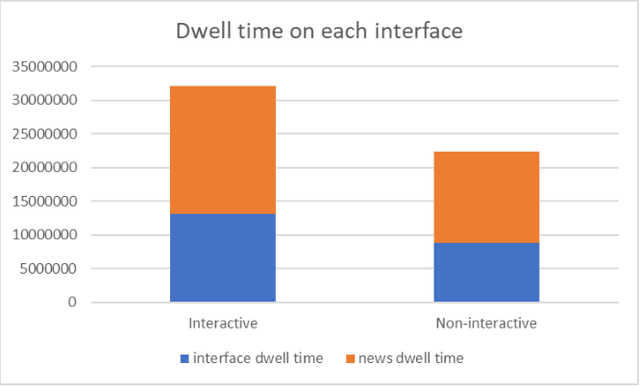
We conducted a lab-based eye-tracking study to investigate how the interactivity of an AI-powered fact-checking system affects user interactions, such as dwell time, attention, and mental resources involved in using the system. A within-subject experiment was conducted, where participants used an interactive and a non-interactive version of a mock AI fact-checking system and rated their perceived correctness of COVID-19 related claims. We collected web-page interactions, eye-tracking data, and mental workload using NASA-TLX. We found that the presence of the affordance of interactively manipulating the AI system's prediction parameters affected users' dwell times, and eye-fixations on AOIs, but not mental workload. In the interactive system, participants spent the most time evaluating claims' correctness, followed by reading news. This promising result shows a positive role of interactivity in a mixed-initiative AI-powered system.
The Case for Claim Difficulty Assessment in Automatic Fact Checking
Sep 20, 2021


Fact-checking is the process (human, automated, or hybrid) by which claims (i.e., purported facts) are evaluated for veracity. In this article, we raise an issue that has received little attention in prior work - that some claims are far more difficult to fact-check than others. We discuss the implications this has for both practical fact-checking and research on automated fact-checking, including task formulation and dataset design. We report a manual analysis undertaken to explore factors underlying varying claim difficulty and categorize several distinct types of difficulty. We argue that prediction of claim difficulty is a missing component of today's automated fact-checking architectures, and we describe how this difficulty prediction task might be split into a set of distinct subtasks.
Fairness and Discrimination in Information Access Systems
May 12, 2021

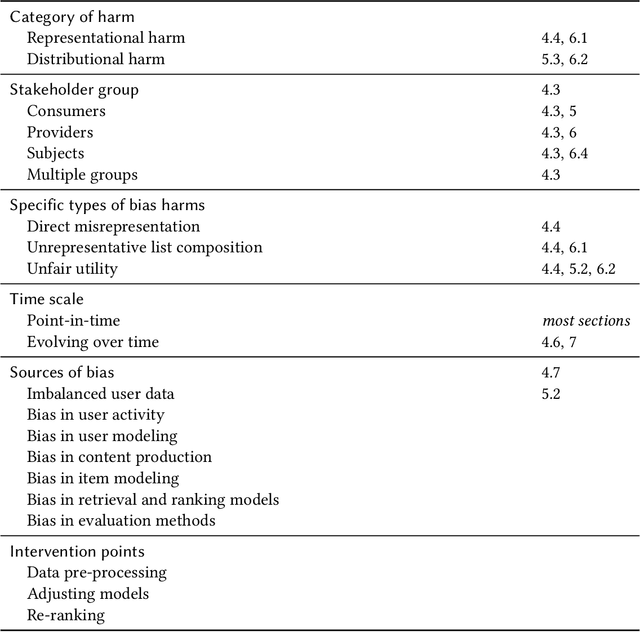
Recommendation, information retrieval, and other information access systems pose unique challenges for investigating and applying the fairness and non-discrimination concepts that have been developed for studying other machine learning systems. While fair information access shares many commonalities with fair classification, the multistakeholder nature of information access applications, the rank-based problem setting, the centrality of personalization in many cases, and the role of user response complicate the problem of identifying precisely what types and operationalizations of fairness may be relevant, let alone measuring or promoting them. In this monograph, we present a taxonomy of the various dimensions of fair information access and survey the literature to date on this new and rapidly-growing topic. We preface this with brief introductions to information access and algorithmic fairness, to facilitate use of this work by scholars with experience in one (or neither) of these fields who wish to learn about their intersection. We conclude with several open problems in fair information access, along with some suggestions for how to approach research in this space.