 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQuest-Coder-V1 Technical Report
Mar 17, 2026In this report, we introduce the IQuest-Coder-V1 series-(7B/14B/40B/40B-Loop), a new family of code large language models (LLMs). Moving beyond static code representations, we propose the code-flow multi-stage training paradigm, which captures the dynamic evolution of software logic through different phases of the pipeline. Our models are developed through the evolutionary pipeline, starting with the initial pre-training consisting of code facts, repository, and completion data. Following that, we implement a specialized mid-training stage that integrates reasoning and agentic trajectories in 32k-context and repository-scale in 128k-context to forge deep logical foundations. The models are then finalized with post-training of specialized coding capabilities, which is bifurcated into two specialized paths: the thinking path (utilizing reasoning-driven RL) and the instruct path (optimized for general assistance). IQuest-Coder-V1 achieves state-of-the-art performance among competitive models across critical dimensions of code intelligence: agentic software engineering, competitive programming, and complex tool use. To address deployment constraints, the IQuest-Coder-V1-Loop variant introduces a recurrent mechanism designed to optimize the trade-off between model capacity and deployment footprint, offering an architecturally enhanced path for efficacy-efficiency trade-off. We believe the release of the IQuest-Coder-V1 series, including the complete white-box chain of checkpoints from pre-training bases to the final thinking and instruction models, will advance research in autonomous code intelligence and real-world agentic systems.
IONext: Unlocking the Next Era of Inertial Odometry
Jul 23, 2025Researchers have increasingly adopted Transformer-based models for inertial odometry. While Transformers excel at modeling long-range dependencies, their limited sensitivity to local, fine-grained motion variations and lack of inherent inductive biases often hinder localization accuracy and generalization. Recent studies have shown that incorporating large-kernel convolutions and Transformer-inspired architectural designs into CNN can effectively expand the receptive field, thereby improving global motion perception. Motivated by these insights, we propose a novel CNN-based module called the Dual-wing Adaptive Dynamic Mixer (DADM), which adaptively captures both global motion patterns and local, fine-grained motion features from dynamic inputs. This module dynamically generates selective weights based on the input, enabling efficient multi-scale feature aggregation. To further improve temporal modeling, we introduce the Spatio-Temporal Gating Unit (STGU), which selectively extracts representative and task-relevant motion features in the temporal domain. This unit addresses the limitations of temporal modeling observed in existing CNN approaches. Built upon DADM and STGU, we present a new CNN-based inertial odometry backbone, named Next Era of Inertial Odometry (IONext). Extensive experiments on six public datasets demonstrate that IONext consistently outperforms state-of-the-art (SOTA) Transformer- and CNN-based methods. For instance, on the RNIN dataset, IONext reduces the average ATE by 10% and the average RTE by 12% compared to the representative model iMOT.
AutoAttacker: A Large Language Model Guided System to Implement Automatic Cyber-attacks
Mar 02, 2024



Large language models (LLMs) have demonstrated impressive results on natural language tasks, and security researchers are beginning to employ them in both offensive and defensive systems. In cyber-security, there have been multiple research efforts that utilize LLMs focusing on the pre-breach stage of attacks like phishing and malware generation. However, so far there lacks a comprehensive study regarding whether LLM-based systems can be leveraged to simulate the post-breach stage of attacks that are typically human-operated, or "hands-on-keyboard" attacks, under various attack techniques and environments. As LLMs inevitably advance, they may be able to automate both the pre- and post-breach attack stages. This shift may transform organizational attacks from rare, expert-led events to frequent, automated operations requiring no expertise and executed at automation speed and scale. This risks fundamentally changing global computer security and correspondingly causing substantial economic impacts, and a goal of this work is to better understand these risks now so we can better prepare for these inevitable ever-more-capable LLMs on the horizon. On the immediate impact side, this research serves three purposes. First, an automated LLM-based, post-breach exploitation framework can help analysts quickly test and continually improve their organization's network security posture against previously unseen attacks. Second, an LLM-based penetration test system can extend the effectiveness of red teams with a limited number of human analysts. Finally, this research can help defensive systems and teams learn to detect novel attack behaviors preemptively before their use in the wild....
Detection and Recovery Against Deep Neural Network Fault Injection Attacks Based on Contrastive Learning
Jan 30, 2024Deep Neural Network (DNN) models when implemented on executing devices as the inference engines are susceptible to Fault Injection Attacks (FIAs) that manipulate model parameters to disrupt inference execution with disastrous performance. This work introduces Contrastive Learning (CL) of visual representations i.e., a self-supervised learning approach into the deep learning training and inference pipeline to implement DNN inference engines with self-resilience under FIAs. Our proposed CL based FIA Detection and Recovery (CFDR) framework features (i) real-time detection with only a single batch of testing data and (ii) fast recovery effective even with only a small amount of unlabeled testing data. Evaluated with the CIFAR-10 dataset on multiple types of FIAs, our CFDR shows promising detection and recovery effectiveness.
EMShepherd: Detecting Adversarial Samples via Side-channel Leakage
Mar 27, 2023



Deep Neural Networks (DNN) are vulnerable to adversarial perturbations-small changes crafted deliberately on the input to mislead the model for wrong predictions. Adversarial attacks have disastrous consequences for deep learning-empowered critical applications. Existing defense and detection techniques both require extensive knowledge of the model, testing inputs, and even execution details. They are not viable for general deep learning implementations where the model internal is unknown, a common 'black-box' scenario for model users. Inspired by the fact that electromagnetic (EM) emanations of a model inference are dependent on both operations and data and may contain footprints of different input classes, we propose a framework, EMShepherd, to capture EM traces of model execution, perform processing on traces and exploit them for adversarial detection. Only benign samples and their EM traces are used to train the adversarial detector: a set of EM classifiers and class-specific unsupervised anomaly detectors. When the victim model system is under attack by an adversarial example, the model execution will be different from executions for the known classes, and the EM trace will be different. We demonstrate that our air-gapped EMShepherd can effectively detect different adversarial attacks on a commonly used FPGA deep learning accelerator for both Fashion MNIST and CIFAR-10 datasets. It achieves a 100% detection rate on most types of adversarial samples, which is comparable to the state-of-the-art 'white-box' software-based detectors.
MEST: Accurate and Fast Memory-Economic Sparse Training Framework on the Edge
Oct 26, 2021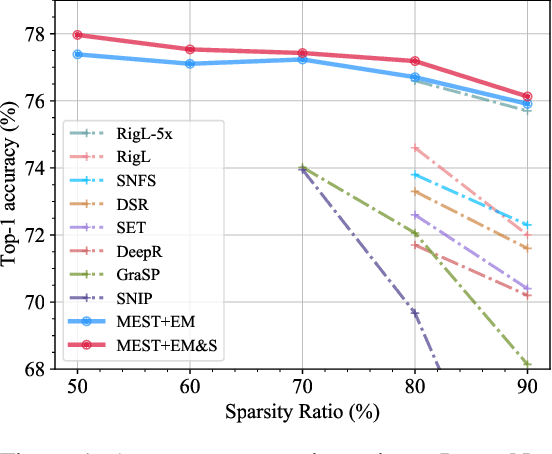
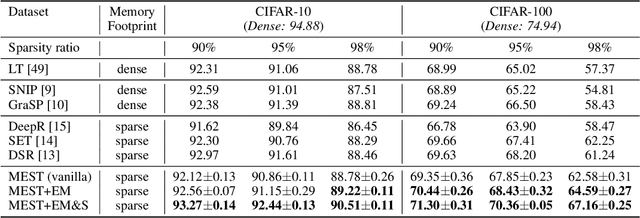
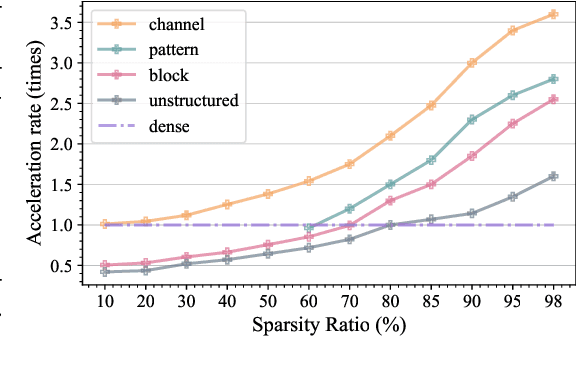
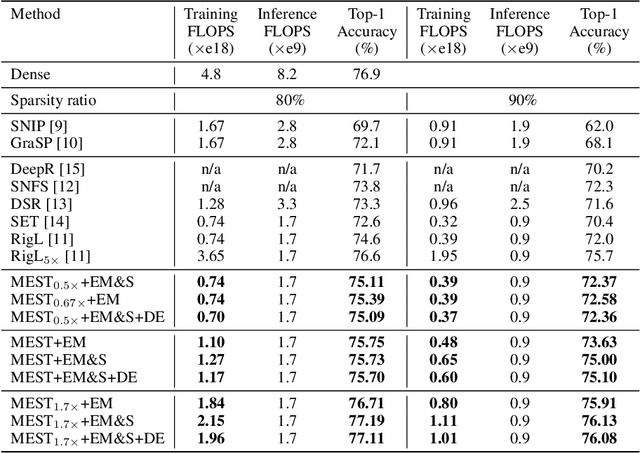
Recently, a new trend of exploring sparsity for accelerating neural network training has emerged, embracing the paradigm of training on the edge. This paper proposes a novel Memory-Economic Sparse Training (MEST) framework targeting for accurate and fast execution on edge devices. The proposed MEST framework consists of enhancements by Elastic Mutation (EM) and Soft Memory Bound (&S) that ensure superior accuracy at high sparsity ratios. Different from the existing works for sparse training, this current work reveals the importance of sparsity schemes on the performance of sparse training in terms of accuracy as well as training speed on real edge devices. On top of that, the paper proposes to employ data efficiency for further acceleration of sparse training. Our results suggest that unforgettable examples can be identified in-situ even during the dynamic exploration of sparsity masks in the sparse training process, and therefore can be removed for further training speedup on edge devices. Comparing with state-of-the-art (SOTA) works on accuracy, our MEST increases Top-1 accuracy significantly on ImageNet when using the same unstructured sparsity scheme. Systematical evaluation on accuracy, training speed, and memory footprint are conducted, where the proposed MEST framework consistently outperforms representative SOTA works. A reviewer strongly against our work based on his false assumptions and misunderstandings. On top of the previous submission, we employ data efficiency for further acceleration of sparse training. And we explore the impact of model sparsity, sparsity schemes, and sparse training algorithms on the number of removable training examples. Our codes are publicly available at: https://github.com/boone891214/MEST.
High-Robustness, Low-Transferability Fingerprinting of Neural Networks
May 14, 2021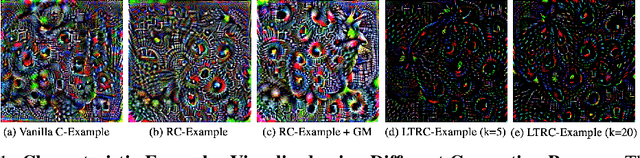
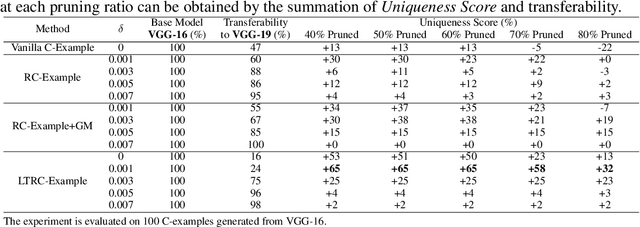
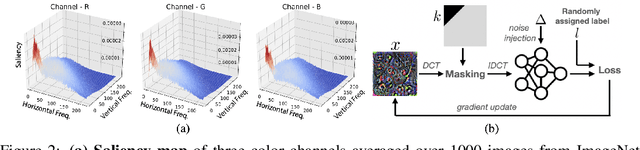
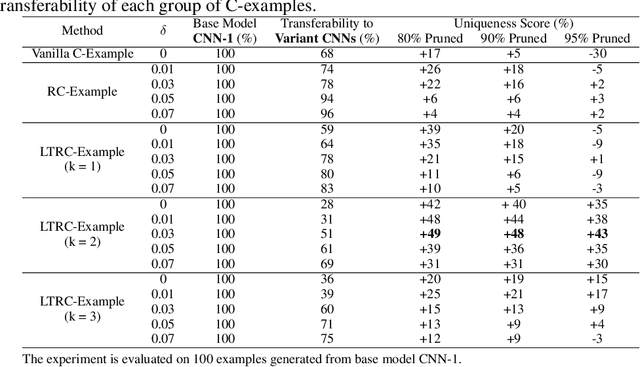
This paper proposes Characteristic Examples for effectively fingerprinting deep neural networks, featuring high-robustness to the base model against model pruning as well as low-transferability to unassociated models. This is the first work taking both robustness and transferability into consideration for generating realistic fingerprints, whereas current methods lack practical assumptions and may incur large false positive rates. To achieve better trade-off between robustness and transferability, we propose three kinds of characteristic examples: vanilla C-examples, RC-examples, and LTRC-example, to derive fingerprints from the original base model. To fairly characterize the trade-off between robustness and transferability, we propose Uniqueness Score, a comprehensive metric that measures the difference between robustness and transferability, which also serves as an indicator to the false alarm problem.
AdvMS: A Multi-source Multi-cost Defense Against Adversarial Attacks
Feb 19, 2020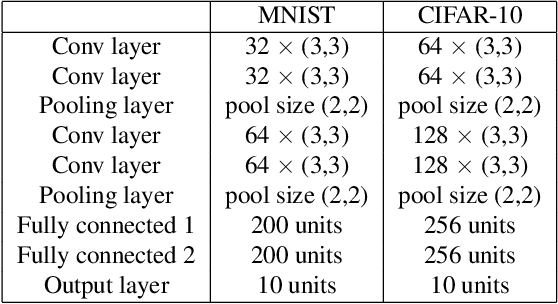
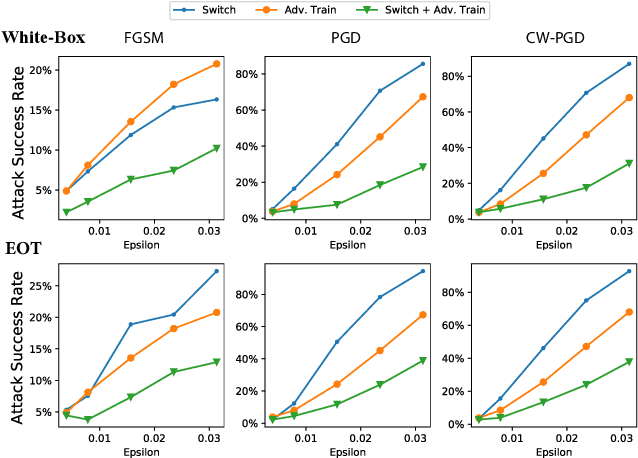
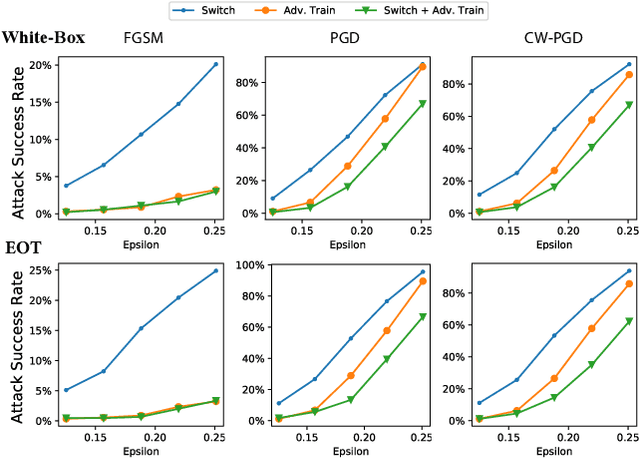
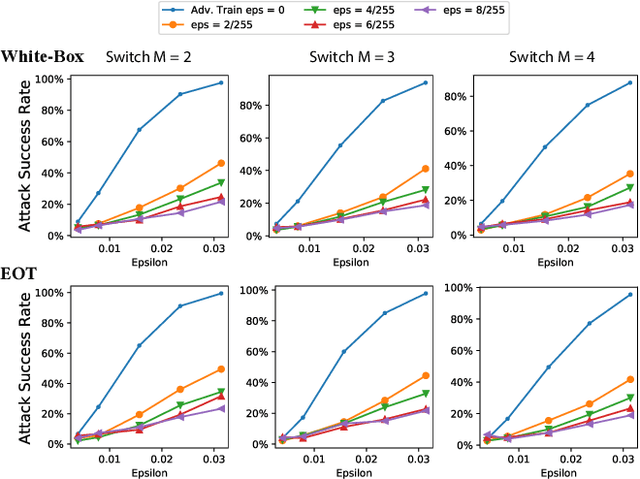
Designing effective defense against adversarial attacks is a crucial topic as deep neural networks have been proliferated rapidly in many security-critical domains such as malware detection and self-driving cars. Conventional defense methods, although shown to be promising, are largely limited by their single-source single-cost nature: The robustness promotion tends to plateau when the defenses are made increasingly stronger while the cost tends to amplify. In this paper, we study principles of designing multi-source and multi-cost schemes where defense performance is boosted from multiple defending components. Based on this motivation, we propose a multi-source and multi-cost defense scheme, Adversarially Trained Model Switching (AdvMS), that inherits advantages from two leading schemes: adversarial training and random model switching. We show that the multi-source nature of AdvMS mitigates the performance plateauing issue and the multi-cost nature enables improving robustness at a flexible and adjustable combination of costs over different factors which can better suit specific restrictions and needs in practice.
RTMobile: Beyond Real-Time Mobile Acceleration of RNNs for Speech Recognition
Feb 19, 2020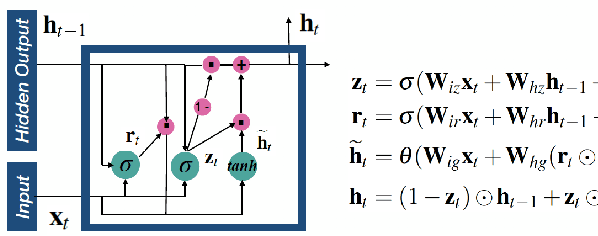
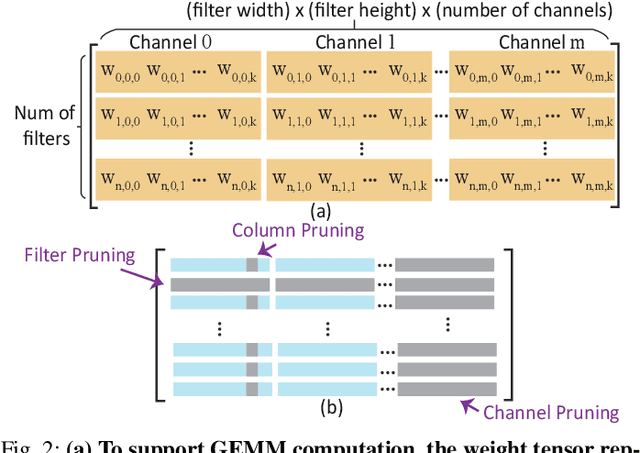
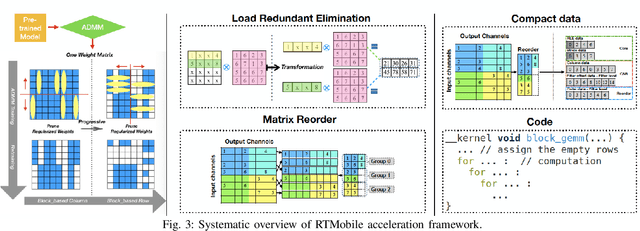
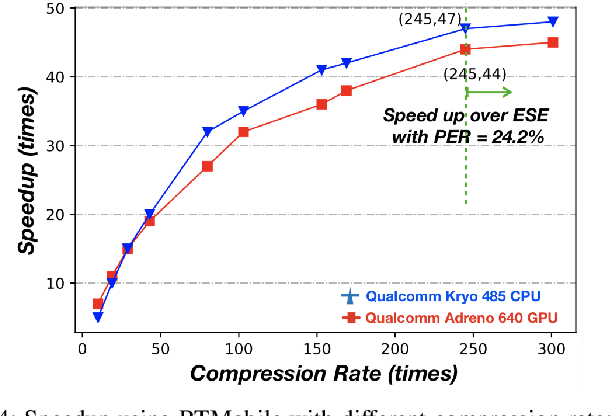
Recurrent neural networks (RNNs) based automatic speech recognition has nowadays become prevalent on mobile devices such as smart phones. However, previous RNN compression techniques either suffer from hardware performance overhead due to irregularity or significant accuracy loss due to the preserved regularity for hardware friendliness. In this work, we propose RTMobile that leverages both a novel block-based pruning approach and compiler optimizations to accelerate RNN inference on mobile devices. Our proposed RTMobile is the first work that can achieve real-time RNN inference on mobile platforms. Experimental results demonstrate that RTMobile can significantly outperform existing RNN hardware acceleration methods in terms of inference accuracy and time. Compared with prior work on FPGA, RTMobile using Adreno 640 embedded GPU on GRU can improve the energy-efficiency by about 40$\times$ while maintaining the same inference time.
Block Switching: A Stochastic Approach for Deep Learning Security
Feb 18, 2020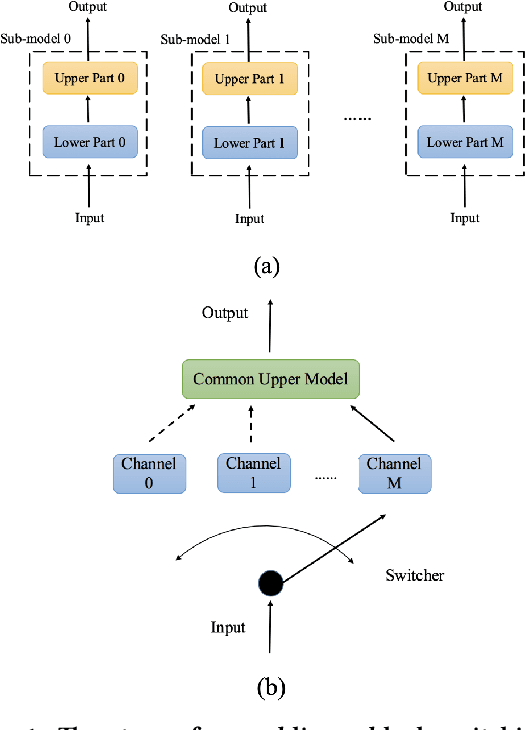
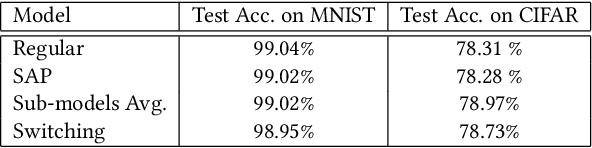
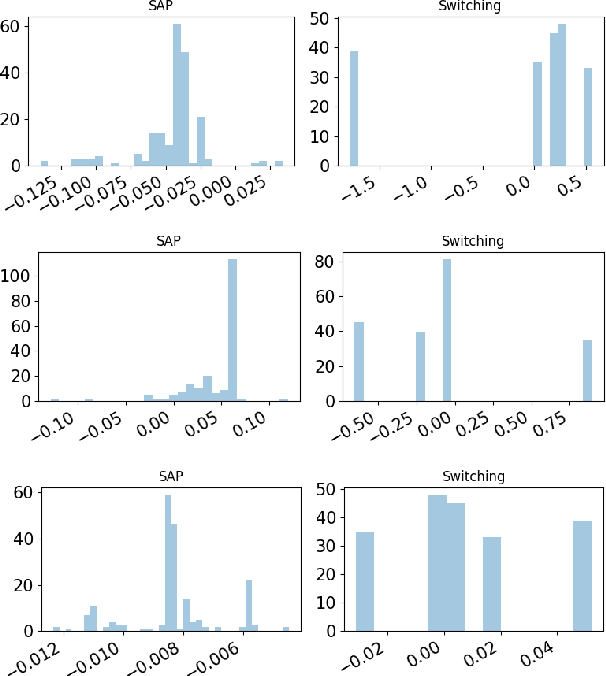
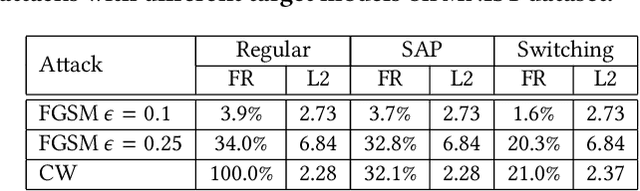
Recent study of adversarial attacks has revealed the vulnerability of modern deep learning models. That is, subtly crafted perturbations of the input can make a trained network with high accuracy produce arbitrary incorrect predictions, while maintain imperceptible to human vision system. In this paper, we introduce Block Switching (BS), a defense strategy against adversarial attacks based on stochasticity. BS replaces a block of model layers with multiple parallel channels, and the active channel is randomly assigned in the run time hence unpredictable to the adversary. We show empirically that BS leads to a more dispersed input gradient distribution and superior defense effectiveness compared with other stochastic defenses such as stochastic activation pruning (SAP). Compared to other defenses, BS is also characterized by the following features: (i) BS causes less test accuracy drop; (ii) BS is attack-independent and (iii) BS is compatible with other defenses and can be used jointly with others.