 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognition-Inspired Dual-Stream Semantic Enhancement for Vision-Based Dynamic Emotion Modeling
Apr 14, 2026The human brain constructs emotional percepts not by processing facial expressions in isolation, but through a dynamic, hierarchical integration of sensory input with semantic and contextual knowledge. However, existing vision-based dynamic emotion modeling approaches often neglect emotion perception and cognitive theories. To bridge this gap between machine and human emotion perception, we propose cognition-inspired Dual-stream Semantic Enhancement (DuSE). Our model instantiates a dual-stream cognitive architecture. The first stream, a Hierarchical Temporal Prompt Cluster (HTPC), operationalizes the cognitive priming effect. It simulates how linguistic cues pre-sensitize neural pathways, modulating the processing of incoming visual stimuli by aligning textual semantics with fine-grained temporal features of facial dynamics. The second stream, a Latent Semantic Emotion Aggregator (LSEA), computationally models the knowledge integration process, akin to the mechanism described by the Conceptual Act Theory. It aggregates sensory inputs and synthesizes them with learned conceptual knowledge, reflecting the role of the hippocampus and default mode network in constructing a coherent emotional experience. By explicitly modeling these neuro-cognitive mechanisms, DuSE provides a more neurally plausible and robust framework for dynamic facial expression recognition (DFER). Extensive experiments on challenging in-the-wild benchmarks validate our cognition-centric approach, demonstrating that emulating the brain's strategies for emotion processing yields state-of-the-art performance and enhances model interpretability.
ARGen: Affect-Reinforced Generative Augmentation towards Vision-based Dynamic Emotion Perception
Apr 14, 2026Dynamic facial expression recognition in the wild remains challenging due to data scarcity and long-tail distributions, which hinder models from effectively learning the temporal dynamics of scarce emotions. To address these limitations, we propose ARGen, an Affect-Reinforced Generative Augmentation Framework that enables data-adaptive dynamic expression generation for robust emotion perception. ARGen operates in two stages: Affective Semantic Injection (ASI) and Adaptive Reinforcement Diffusion (ARD). The ASI stage establishes affective knowledge alignment through facial Action Units and employs a retrieval-augmented prompt generation strategy to synthesize consistent and fine-grained affective descriptions via large-scale visual-language models, thereby injecting interpretable emotional priors into the generation process. The ARD stage integrates text-conditioned image-to-video diffusion with reinforcement learning, introducing inter-frame conditional guidance and a multi-objective reward function to jointly optimize expression naturalness, facial integrity, and generative efficiency. Extensive experiments on both generation and recognition tasks verify that ARGen substantially enhances synthesis fidelity and improves recognition performance, establishing an interpretable and generalizable generative augmentation paradigm for vision-based affective computing.
CREBench: Evaluating Large Language Models in Cryptographic Binary Reverse Engineering
Apr 04, 2026Reverse engineering (RE) is central to software security, particularly for cryptographic programs that handle sensitive data and are highly prone to vulnerabilities. It supports critical tasks such as vulnerability discovery and malware analysis. Despite its importance, RE remains labor-intensive and requires substantial expertise, making large language models (LLMs) a potential solution for automating the process. However, their capabilities for RE remain systematically underexplored. To address this gap, we study the cryptographic binary RE capabilities of LLMs and introduce \textbf{CREBench}, a benchmark comprising 432 challenges built from 48 standard cryptographic algorithms, 3 insecure crypto key usage scenarios, and 3 difficulty levels. Each challenge follows a Capture-the-Flag (CTF) RE challenge, requiring the model to analyze the underlying cryptographic logic and recover the correct input. We design an evaluation framework comprising four sub-tasks, from algorithm identification to correct flag recovery. We evaluate eight frontier LLMs on CREBench. GPT-5.4, the best-performing model, achieves 64.03 out of 100 and recovers the flag in 59\% of challenges. We also establish a strong human expert baseline of 92.19 points, showing that humans maintain an advantage in cryptographic RE tasks. Our code and dataset are available at https://github.com/wangyu-ovo/CREBench.
PRBench: End-to-end Paper Reproduction in Physics Research
Mar 29, 2026AI agents powered by large language models exhibit strong reasoning and problem-solving capabilities, enabling them to assist scientific research tasks such as formula derivation and code generation. However, whether these agents can reliably perform end-to-end reproduction from real scientific papers remains an open question. We introduce PRBench, a benchmark of 30 expert-curated tasks spanning 11 subfields of physics. Each task requires an agent to comprehend the methodology of a published paper, implement the corresponding algorithms from scratch, and produce quantitative results matching the original publication. Agents are provided only with the task instruction and paper content, and operate in a sandboxed execution environment. All tasks are contributed by domain experts from over 20 research groups at the School of Physics, Peking University, each grounded in a real published paper and validated through end-to-end reproduction with verified ground-truth results and detailed scoring rubrics. Using an agentified assessment pipeline, we evaluate a set of coding agents on PRBench and analyze their capabilities across key dimensions of scientific reasoning and execution. The best-performing agent, OpenAI Codex powered by GPT-5.3-Codex, achieves a mean overall score of 34%. All agents exhibit a zero end-to-end callback success rate, with particularly poor performance in data accuracy and code correctness. We further identify systematic failure modes, including errors in formula implementation, inability to debug numerical simulations, and fabrication of output data. Overall, PRBench provides a rigorous benchmark for evaluating progress toward autonomous scientific research.
Credibility Governance: A Social Mechanism for Collective Self-Correction under Weak Truth Signals
Mar 03, 2026Online platforms increasingly rely on opinion aggregation to allocate real-world attention and resources, yet common signals such as engagement votes or capital-weighted commitments are easy to amplify and often track visibility rather than reliability. This makes collective judgments brittle under weak truth signals, noisy or delayed feedback, early popularity surges, and strategic manipulation. We propose Credibility Governance (CG), a mechanism that reallocates influence by learning which agents and viewpoints consistently track evolving public evidence. CG maintains dynamic credibility scores for both agents and opinions, updates opinion influence via credibility-weighted endorsements, and updates agent credibility based on the long-run performance of the opinions they support, rewarding early and persistent alignment with emerging evidence while filtering short-lived noise. We evaluate CG in POLIS, a socio-physical simulation environment that models coupled belief dynamics and downstream feedback under uncertainty. Across settings with initial majority misalignment, observation noise and contamination, and misinformation shocks, CG outperforms vote-based, stake-weighted, and no-governance baselines, yielding faster recovery to the true state, reduced lock-in and path dependence, and improved robustness under adversarial pressure. Our implementation and experimental scripts are publicly available at https://github.com/Wanying-He/Credibility_Governance.
Commonality in Few: Few-Shot Multimodal Anomaly Detection via Hypergraph-Enhanced Memory
Nov 16, 2025
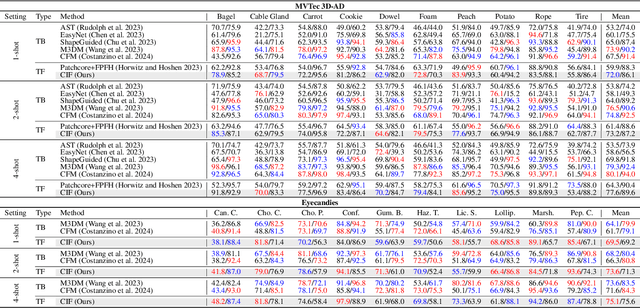
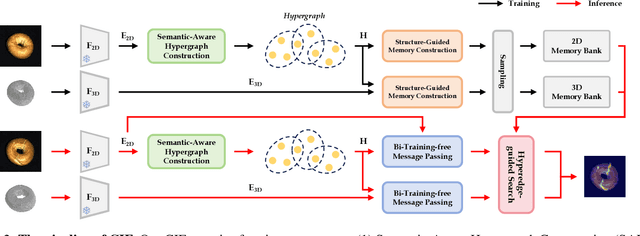

Few-shot multimodal industrial anomaly detection is a critical yet underexplored task, offering the ability to quickly adapt to complex industrial scenarios. In few-shot settings, insufficient training samples often fail to cover the diverse patterns present in test samples. This challenge can be mitigated by extracting structural commonality from a small number of training samples. In this paper, we propose a novel few-shot unsupervised multimodal industrial anomaly detection method based on structural commonality, CIF (Commonality In Few). To extract intra-class structural information, we employ hypergraphs, which are capable of modeling higher-order correlations, to capture the structural commonality within training samples, and use a memory bank to store this intra-class structural prior. Firstly, we design a semantic-aware hypergraph construction module tailored for single-semantic industrial images, from which we extract common structures to guide the construction of the memory bank. Secondly, we use a training-free hypergraph message passing module to update the visual features of test samples, reducing the distribution gap between test features and features in the memory bank. We further propose a hyperedge-guided memory search module, which utilizes structural information to assist the memory search process and reduce the false positive rate. Experimental results on the MVTec 3D-AD dataset and the Eyecandies dataset show that our method outperforms the state-of-the-art (SOTA) methods in few-shot settings. Code is available at https://github.com/Sunny5250/CIF.
CLASP: Cross-modal Salient Anchor-based Semantic Propagation for Weakly-supervised Dense Audio-Visual Event Localization
Aug 06, 2025The Dense Audio-Visual Event Localization (DAVEL) task aims to temporally localize events in untrimmed videos that occur simultaneously in both the audio and visual modalities. This paper explores DAVEL under a new and more challenging weakly-supervised setting (W-DAVEL task), where only video-level event labels are provided and the temporal boundaries of each event are unknown. We address W-DAVEL by exploiting \textit{cross-modal salient anchors}, which are defined as reliable timestamps that are well predicted under weak supervision and exhibit highly consistent event semantics across audio and visual modalities. Specifically, we propose a \textit{Mutual Event Agreement Evaluation} module, which generates an agreement score by measuring the discrepancy between the predicted audio and visual event classes. Then, the agreement score is utilized in a \textit{Cross-modal Salient Anchor Identification} module, which identifies the audio and visual anchor features through global-video and local temporal window identification mechanisms. The anchor features after multimodal integration are fed into an \textit{Anchor-based Temporal Propagation} module to enhance event semantic encoding in the original temporal audio and visual features, facilitating better temporal localization under weak supervision. We establish benchmarks for W-DAVEL on both the UnAV-100 and ActivityNet1.3 datasets. Extensive experiments demonstrate that our method achieves state-of-the-art performance.
IONext: Unlocking the Next Era of Inertial Odometry
Jul 23, 2025Researchers have increasingly adopted Transformer-based models for inertial odometry. While Transformers excel at modeling long-range dependencies, their limited sensitivity to local, fine-grained motion variations and lack of inherent inductive biases often hinder localization accuracy and generalization. Recent studies have shown that incorporating large-kernel convolutions and Transformer-inspired architectural designs into CNN can effectively expand the receptive field, thereby improving global motion perception. Motivated by these insights, we propose a novel CNN-based module called the Dual-wing Adaptive Dynamic Mixer (DADM), which adaptively captures both global motion patterns and local, fine-grained motion features from dynamic inputs. This module dynamically generates selective weights based on the input, enabling efficient multi-scale feature aggregation. To further improve temporal modeling, we introduce the Spatio-Temporal Gating Unit (STGU), which selectively extracts representative and task-relevant motion features in the temporal domain. This unit addresses the limitations of temporal modeling observed in existing CNN approaches. Built upon DADM and STGU, we present a new CNN-based inertial odometry backbone, named Next Era of Inertial Odometry (IONext). Extensive experiments on six public datasets demonstrate that IONext consistently outperforms state-of-the-art (SOTA) Transformer- and CNN-based methods. For instance, on the RNIN dataset, IONext reduces the average ATE by 10% and the average RTE by 12% compared to the representative model iMOT.
PHYBench: Holistic Evaluation of Physical Perception and Reasoning in Large Language Models
Apr 22, 2025



We introduce PHYBench, a novel, high-quality benchmark designed for evaluating reasoning capabilities of large language models (LLMs) in physical contexts. PHYBench consists of 500 meticulously curated physics problems based on real-world physical scenarios, designed to assess the ability of models to understand and reason about realistic physical processes. Covering mechanics, electromagnetism, thermodynamics, optics, modern physics, and advanced physics, the benchmark spans difficulty levels from high school exercises to undergraduate problems and Physics Olympiad challenges. Additionally, we propose the Expression Edit Distance (EED) Score, a novel evaluation metric based on the edit distance between mathematical expressions, which effectively captures differences in model reasoning processes and results beyond traditional binary scoring methods. We evaluate various LLMs on PHYBench and compare their performance with human experts. Our results reveal that even state-of-the-art reasoning models significantly lag behind human experts, highlighting their limitations and the need for improvement in complex physical reasoning scenarios. Our benchmark results and dataset are publicly available at https://phybench-official.github.io/phybench-demo/.
Dense Audio-Visual Event Localization under Cross-Modal Consistency and Multi-Temporal Granularity Collaboration
Dec 17, 2024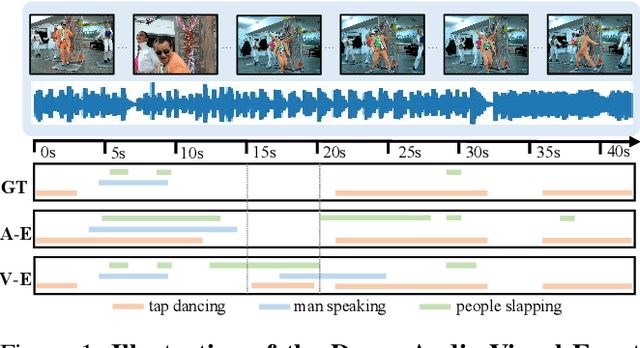
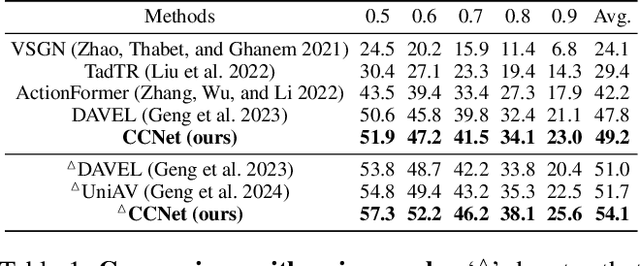
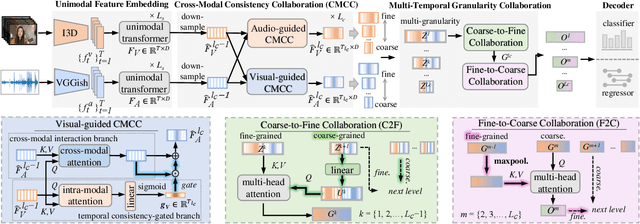
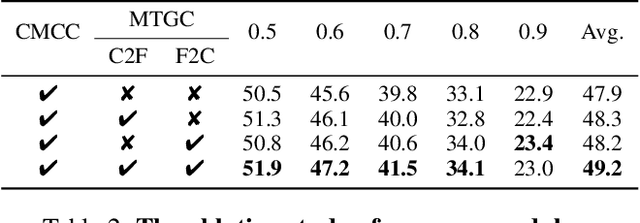
In the field of audio-visual learning, most research tasks focus exclusively on short videos. This paper focuses on the more practical Dense Audio-Visual Event Localization (DAVEL) task, advancing audio-visual scene understanding for longer, {untrimmed} videos. This task seeks to identify and temporally pinpoint all events simultaneously occurring in both audio and visual streams. Typically, each video encompasses dense events of multiple classes, which may overlap on the timeline, each exhibiting varied durations. Given these challenges, effectively exploiting the audio-visual relations and the temporal features encoded at various granularities becomes crucial. To address these challenges, we introduce a novel \ul{CC}Net, comprising two core modules: the Cross-Modal Consistency \ul{C}ollaboration (CMCC) and the Multi-Temporal Granularity \ul{C}ollaboration (MTGC). Specifically, the CMCC module contains two branches: a cross-modal interaction branch and a temporal consistency-gated branch. The former branch facilitates the aggregation of consistent event semantics across modalities through the encoding of audio-visual relations, while the latter branch guides one modality's focus to pivotal event-relevant temporal areas as discerned in the other modality. The MTGC module includes a coarse-to-fine collaboration block and a fine-to-coarse collaboration block, providing bidirectional support among coarse- and fine-grained temporal features. Extensive experiments on the UnAV-100 dataset validate our module design, resulting in a new state-of-the-art performance in dense audio-visual event localization. The code is available at \url{https://github.com/zzhhfut/CCNet-AAAI2025}.