 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuses: Designing, Composing, Generating Nonexistent Fantasy 3D Creatures without Training
Jan 06, 2026We present Muses, the first training-free method for fantastic 3D creature generation in a feed-forward paradigm. Previous methods, which rely on part-aware optimization, manual assembly, or 2D image generation, often produce unrealistic or incoherent 3D assets due to the challenges of intricate part-level manipulation and limited out-of-domain generation. In contrast, Muses leverages the 3D skeleton, a fundamental representation of biological forms, to explicitly and rationally compose diverse elements. This skeletal foundation formalizes 3D content creation as a structure-aware pipeline of design, composition, and generation. Muses begins by constructing a creatively composed 3D skeleton with coherent layout and scale through graph-constrained reasoning. This skeleton then guides a voxel-based assembly process within a structured latent space, integrating regions from different objects. Finally, image-guided appearance modeling under skeletal conditions is applied to generate a style-consistent and harmonious texture for the assembled shape. Extensive experiments establish Muses' state-of-the-art performance in terms of visual fidelity and alignment with textual descriptions, and potential on flexible 3D object editing. Project page: https://luhexiao.github.io/Muses.github.io/.
MorphAny3D: Unleashing the Power of Structured Latent in 3D Morphing
Jan 01, 20263D morphing remains challenging due to the difficulty of generating semantically consistent and temporally smooth deformations, especially across categories. We present MorphAny3D, a training-free framework that leverages Structured Latent (SLAT) representations for high-quality 3D morphing. Our key insight is that intelligently blending source and target SLAT features within the attention mechanisms of 3D generators naturally produces plausible morphing sequences. To this end, we introduce Morphing Cross-Attention (MCA), which fuses source and target information for structural coherence, and Temporal-Fused Self-Attention (TFSA), which enhances temporal consistency by incorporating features from preceding frames. An orientation correction strategy further mitigates the pose ambiguity within the morphing steps. Extensive experiments show that our method generates state-of-the-art morphing sequences, even for challenging cross-category cases. MorphAny3D further supports advanced applications such as decoupled morphing and 3D style transfer, and can be generalized to other SLAT-based generative models. Project page: https://xiaokunsun.github.io/MorphAny3D.github.io/.
MagicAnime: A Hierarchically Annotated, Multimodal and Multitasking Dataset with Benchmarks for Cartoon Animation Generation
Jul 27, 2025Generating high-quality cartoon animations multimodal control is challenging due to the complexity of non-human characters, stylistically diverse motions and fine-grained emotions. There is a huge domain gap between real-world videos and cartoon animation, as cartoon animation is usually abstract and has exaggerated motion. Meanwhile, public multimodal cartoon data are extremely scarce due to the difficulty of large-scale automatic annotation processes compared with real-life scenarios. To bridge this gap, We propose the MagicAnime dataset, a large-scale, hierarchically annotated, and multimodal dataset designed to support multiple video generation tasks, along with the benchmarks it includes. Containing 400k video clips for image-to-video generation, 50k pairs of video clips and keypoints for whole-body annotation, 12k pairs of video clips for video-to-video face animation, and 2.9k pairs of video and audio clips for audio-driven face animation. Meanwhile, we also build a set of multi-modal cartoon animation benchmarks, called MagicAnime-Bench, to support the comparisons of different methods in the tasks above. Comprehensive experiments on four tasks, including video-driven face animation, audio-driven face animation, image-to-video animation, and pose-driven character animation, validate its effectiveness in supporting high-fidelity, fine-grained, and controllable generation.
AssetDropper: Asset Extraction via Diffusion Models with Reward-Driven Optimization
Jun 06, 2025Recent research on generative models has primarily focused on creating product-ready visual outputs; however, designers often favor access to standardized asset libraries, a domain that has yet to be significantly enhanced by generative capabilities. Although open-world scenes provide ample raw materials for designers, efficiently extracting high-quality, standardized assets remains a challenge. To address this, we introduce AssetDropper, the first framework designed to extract assets from reference images, providing artists with an open-world asset palette. Our model adeptly extracts a front view of selected subjects from input images, effectively handling complex scenarios such as perspective distortion and subject occlusion. We establish a synthetic dataset of more than 200,000 image-subject pairs and a real-world benchmark with thousands more for evaluation, facilitating the exploration of future research in downstream tasks. Furthermore, to ensure precise asset extraction that aligns well with the image prompts, we employ a pre-trained reward model to fulfill a closed-loop with feedback. We design the reward model to perform an inverse task that pastes the extracted assets back into the reference sources, which assists training with additional consistency and mitigates hallucination. Extensive experiments show that, with the aid of reward-driven optimization, AssetDropper achieves the state-of-the-art results in asset extraction. Project page: AssetDropper.github.io.
PHYBench: Holistic Evaluation of Physical Perception and Reasoning in Large Language Models
Apr 22, 2025



We introduce PHYBench, a novel, high-quality benchmark designed for evaluating reasoning capabilities of large language models (LLMs) in physical contexts. PHYBench consists of 500 meticulously curated physics problems based on real-world physical scenarios, designed to assess the ability of models to understand and reason about realistic physical processes. Covering mechanics, electromagnetism, thermodynamics, optics, modern physics, and advanced physics, the benchmark spans difficulty levels from high school exercises to undergraduate problems and Physics Olympiad challenges. Additionally, we propose the Expression Edit Distance (EED) Score, a novel evaluation metric based on the edit distance between mathematical expressions, which effectively captures differences in model reasoning processes and results beyond traditional binary scoring methods. We evaluate various LLMs on PHYBench and compare their performance with human experts. Our results reveal that even state-of-the-art reasoning models significantly lag behind human experts, highlighting their limitations and the need for improvement in complex physical reasoning scenarios. Our benchmark results and dataset are publicly available at https://phybench-official.github.io/phybench-demo/.
ETCH: Generalizing Body Fitting to Clothed Humans via Equivariant Tightness
Mar 13, 2025Fitting a body to a 3D clothed human point cloud is a common yet challenging task. Traditional optimization-based approaches use multi-stage pipelines that are sensitive to pose initialization, while recent learning-based methods often struggle with generalization across diverse poses and garment types. We propose Equivariant Tightness Fitting for Clothed Humans, or ETCH, a novel pipeline that estimates cloth-to-body surface mapping through locally approximate SE(3) equivariance, encoding tightness as displacement vectors from the cloth surface to the underlying body. Following this mapping, pose-invariant body features regress sparse body markers, simplifying clothed human fitting into an inner-body marker fitting task. Extensive experiments on CAPE and 4D-Dress show that ETCH significantly outperforms state-of-the-art methods -- both tightness-agnostic and tightness-aware -- in body fitting accuracy on loose clothing (16.7% ~ 69.5%) and shape accuracy (average 49.9%). Our equivariant tightness design can even reduce directional errors by (67.2% ~ 89.8%) in one-shot (or out-of-distribution) settings. Qualitative results demonstrate strong generalization of ETCH, regardless of challenging poses, unseen shapes, loose clothing, and non-rigid dynamics. We will release the code and models soon for research purposes at https://boqian-li.github.io/ETCH/.
Deformable Gaussian Splatting for Efficient and High-Fidelity Reconstruction of Surgical Scenes
Jan 02, 2025



Efficient and high-fidelity reconstruction of deformable surgical scenes is a critical yet challenging task. Building on recent advancements in 3D Gaussian splatting, current methods have seen significant improvements in both reconstruction quality and rendering speed. However, two major limitations remain: (1) difficulty in handling irreversible dynamic changes, such as tissue shearing, which are common in surgical scenes; and (2) the lack of hierarchical modeling for surgical scene deformation, which reduces rendering speed. To address these challenges, we introduce EH-SurGS, an efficient and high-fidelity reconstruction algorithm for deformable surgical scenes. We propose a deformation modeling approach that incorporates the life cycle of 3D Gaussians, effectively capturing both regular and irreversible deformations, thus enhancing reconstruction quality. Additionally, we present an adaptive motion hierarchy strategy that distinguishes between static and deformable regions within the surgical scene. This strategy reduces the number of 3D Gaussians passing through the deformation field, thereby improving rendering speed. Extensive experiments demonstrate that our method surpasses existing state-of-the-art approaches in both reconstruction quality and rendering speed. Ablation studies further validate the effectiveness and necessity of our proposed components. We will open-source our code upon acceptance of the paper.
StrandHead: Text to Strand-Disentangled 3D Head Avatars Using Hair Geometric Priors
Dec 16, 2024
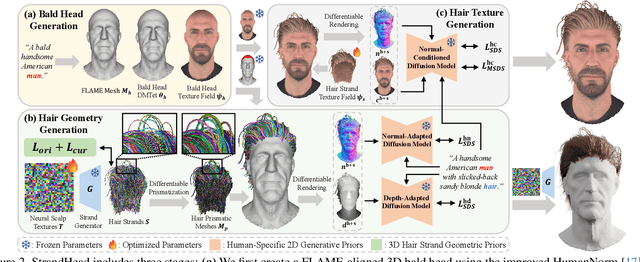
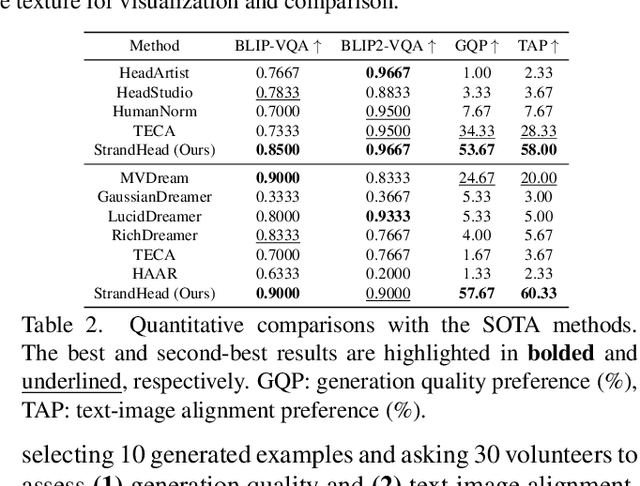
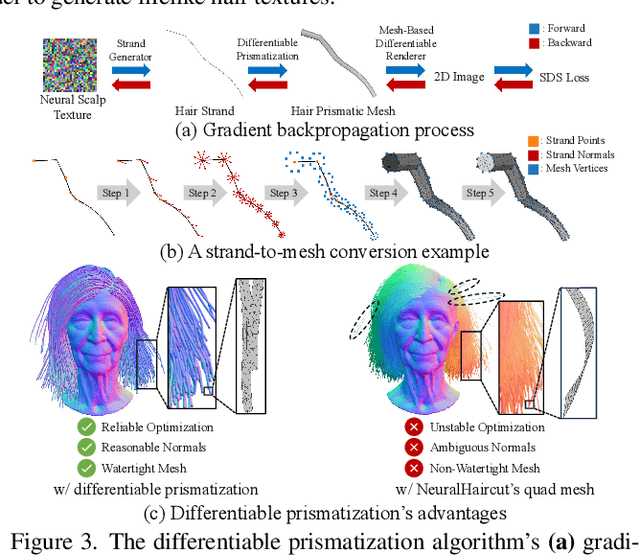
While haircut indicates distinct personality, existing avatar generation methods fail to model practical hair due to the general or entangled representation. We propose StrandHead, a novel text to 3D head avatar generation method capable of generating disentangled 3D hair with strand representation. Without using 3D data for supervision, we demonstrate that realistic hair strands can be generated from prompts by distilling 2D generative diffusion models. To this end, we propose a series of reliable priors on shape initialization, geometric primitives, and statistical haircut features, leading to a stable optimization and text-aligned performance. Extensive experiments show that StrandHead achieves the state-of-the-art reality and diversity of generated 3D head and hair. The generated 3D hair can also be easily implemented in the Unreal Engine for physical simulation and other applications. The code will be available at https://xiaokunsun.github.io/StrandHead.github.io.
DreamMapping: High-Fidelity Text-to-3D Generation via Variational Distribution Mapping
Sep 11, 2024



Score Distillation Sampling (SDS) has emerged as a prevalent technique for text-to-3D generation, enabling 3D content creation by distilling view-dependent information from text-to-2D guidance. However, they frequently exhibit shortcomings such as over-saturated color and excess smoothness. In this paper, we conduct a thorough analysis of SDS and refine its formulation, finding that the core design is to model the distribution of rendered images. Following this insight, we introduce a novel strategy called Variational Distribution Mapping (VDM), which expedites the distribution modeling process by regarding the rendered images as instances of degradation from diffusion-based generation. This special design enables the efficient training of variational distribution by skipping the calculations of the Jacobians in the diffusion U-Net. We also introduce timestep-dependent Distribution Coefficient Annealing (DCA) to further improve distilling precision. Leveraging VDM and DCA, we use Gaussian Splatting as the 3D representation and build a text-to-3D generation framework. Extensive experiments and evaluations demonstrate the capability of VDM and DCA to generate high-fidelity and realistic assets with optimization efficiency.
DEGAS: Detailed Expressions on Full-Body Gaussian Avatars
Aug 20, 2024



Although neural rendering has made significant advancements in creating lifelike, animatable full-body and head avatars, incorporating detailed expressions into full-body avatars remains largely unexplored. We present DEGAS, the first 3D Gaussian Splatting (3DGS)-based modeling method for full-body avatars with rich facial expressions. Trained on multiview videos of a given subject, our method learns a conditional variational autoencoder that takes both the body motion and facial expression as driving signals to generate Gaussian maps in the UV layout. To drive the facial expressions, instead of the commonly used 3D Morphable Models (3DMMs) in 3D head avatars, we propose to adopt the expression latent space trained solely on 2D portrait images, bridging the gap between 2D talking faces and 3D avatars. Leveraging the rendering capability of 3DGS and the rich expressiveness of the expression latent space, the learned avatars can be reenacted to reproduce photorealistic rendering images with subtle and accurate facial expressions. Experiments on an existing dataset and our newly proposed dataset of full-body talking avatars demonstrate the efficacy of our method. We also propose an audio-driven extension of our method with the help of 2D talking faces, opening new possibilities to interactive AI agents.