 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Thinking Hurts: Mitigating Visual Forgetting in Video Reasoning via Frame Repetition
Mar 17, 2026Recently, Multimodal Large Language Models (MLLMs) have demonstrated significant potential in complex visual tasks through the integration of Chain-of-Thought (CoT) reasoning. However, in Video Question Answering, extended thinking processes do not consistently yield performance gains and may even lead to degradation due to ``visual anchor drifting'', where models increasingly rely on self-generated text, sidelining visual inputs and causing hallucinations. While existing mitigations typically introduce specific mechanisms for the model to re-attend to visual inputs during inference, these approaches often incur prohibitive training costs and suffer from poor generalizability across different architectures. To address this, we propose FrameRepeat, an automated enhancement framework which features a lightweight repeat scoring module that enables Video-LLMs to autonomously identify which frames should be reinforced. We introduce a novel training strategy, Add-One-In (AOI), that uses MLLM output probabilities to generate supervision signals representing repeat gain. This can be used to train a frame scoring network, which guides the frame repetition behavior. Experimental results across multiple models and datasets demonstrate that FrameRepeat is both effective and generalizable in strengthening important visual cues during the reasoning process.
MVP: Enhancing Video Large Language Models via Self-supervised Masked Video Prediction
Jan 07, 2026Reinforcement learning based post-training paradigms for Video Large Language Models (VideoLLMs) have achieved significant success by optimizing for visual-semantic tasks such as captioning or VideoQA. However, while these approaches effectively enhance perception abilities, they primarily target holistic content understanding, often lacking explicit supervision for intrinsic temporal coherence and inter-frame correlations. This tendency limits the models' ability to capture intricate dynamics and fine-grained visual causality. To explicitly bridge this gap, we propose a novel post-training objective: Masked Video Prediction (MVP). By requiring the model to reconstruct a masked continuous segment from a set of challenging distractors, MVP forces the model to attend to the sequential logic and temporal context of events. To support scalable training, we introduce a scalable data synthesis pipeline capable of transforming arbitrary video corpora into MVP training samples, and further employ Group Relative Policy Optimization (GRPO) with a fine-grained reward function to enhance the model's understanding of video context and temporal properties. Comprehensive evaluations demonstrate that MVP enhances video reasoning capabilities by directly reinforcing temporal reasoning and causal understanding.
Muses: Designing, Composing, Generating Nonexistent Fantasy 3D Creatures without Training
Jan 06, 2026We present Muses, the first training-free method for fantastic 3D creature generation in a feed-forward paradigm. Previous methods, which rely on part-aware optimization, manual assembly, or 2D image generation, often produce unrealistic or incoherent 3D assets due to the challenges of intricate part-level manipulation and limited out-of-domain generation. In contrast, Muses leverages the 3D skeleton, a fundamental representation of biological forms, to explicitly and rationally compose diverse elements. This skeletal foundation formalizes 3D content creation as a structure-aware pipeline of design, composition, and generation. Muses begins by constructing a creatively composed 3D skeleton with coherent layout and scale through graph-constrained reasoning. This skeleton then guides a voxel-based assembly process within a structured latent space, integrating regions from different objects. Finally, image-guided appearance modeling under skeletal conditions is applied to generate a style-consistent and harmonious texture for the assembled shape. Extensive experiments establish Muses' state-of-the-art performance in terms of visual fidelity and alignment with textual descriptions, and potential on flexible 3D object editing. Project page: https://luhexiao.github.io/Muses.github.io/.
MorphAny3D: Unleashing the Power of Structured Latent in 3D Morphing
Jan 01, 20263D morphing remains challenging due to the difficulty of generating semantically consistent and temporally smooth deformations, especially across categories. We present MorphAny3D, a training-free framework that leverages Structured Latent (SLAT) representations for high-quality 3D morphing. Our key insight is that intelligently blending source and target SLAT features within the attention mechanisms of 3D generators naturally produces plausible morphing sequences. To this end, we introduce Morphing Cross-Attention (MCA), which fuses source and target information for structural coherence, and Temporal-Fused Self-Attention (TFSA), which enhances temporal consistency by incorporating features from preceding frames. An orientation correction strategy further mitigates the pose ambiguity within the morphing steps. Extensive experiments show that our method generates state-of-the-art morphing sequences, even for challenging cross-category cases. MorphAny3D further supports advanced applications such as decoupled morphing and 3D style transfer, and can be generalized to other SLAT-based generative models. Project page: https://xiaokunsun.github.io/MorphAny3D.github.io/.
StrandHead: Text to Strand-Disentangled 3D Head Avatars Using Hair Geometric Priors
Dec 16, 2024
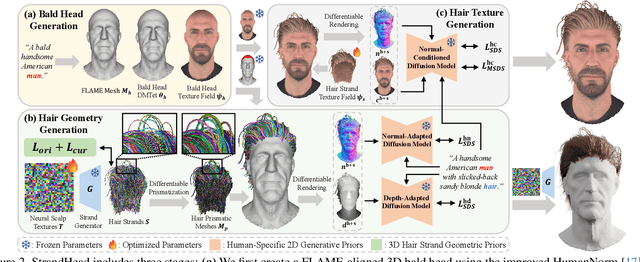
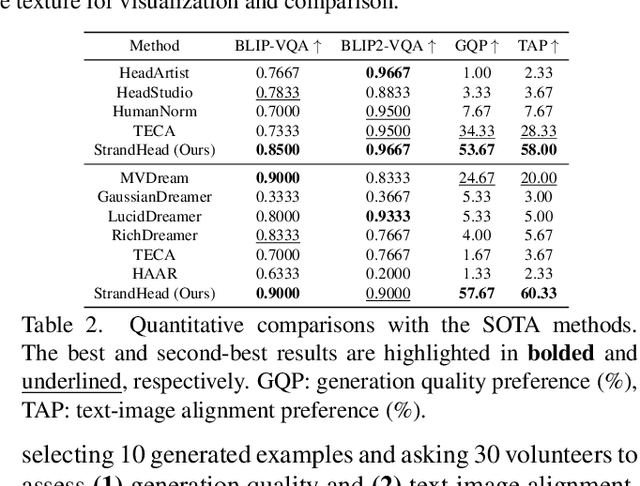
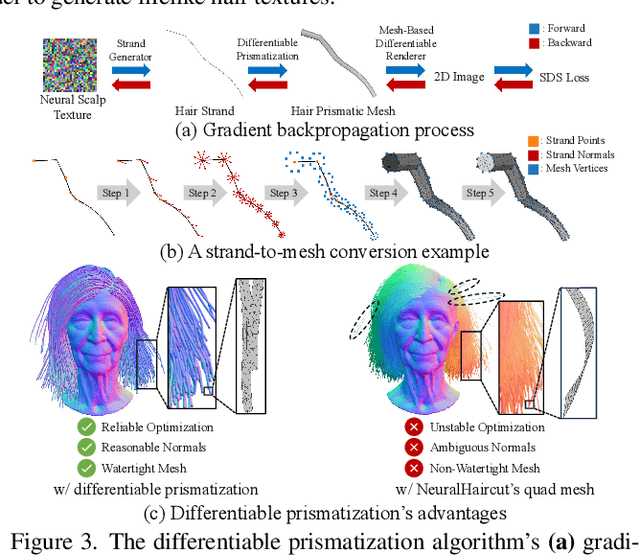
While haircut indicates distinct personality, existing avatar generation methods fail to model practical hair due to the general or entangled representation. We propose StrandHead, a novel text to 3D head avatar generation method capable of generating disentangled 3D hair with strand representation. Without using 3D data for supervision, we demonstrate that realistic hair strands can be generated from prompts by distilling 2D generative diffusion models. To this end, we propose a series of reliable priors on shape initialization, geometric primitives, and statistical haircut features, leading to a stable optimization and text-aligned performance. Extensive experiments show that StrandHead achieves the state-of-the-art reality and diversity of generated 3D head and hair. The generated 3D hair can also be easily implemented in the Unreal Engine for physical simulation and other applications. The code will be available at https://xiaokunsun.github.io/StrandHead.github.io.
Barbie: Text to Barbie-Style 3D Avatars
Aug 17, 2024
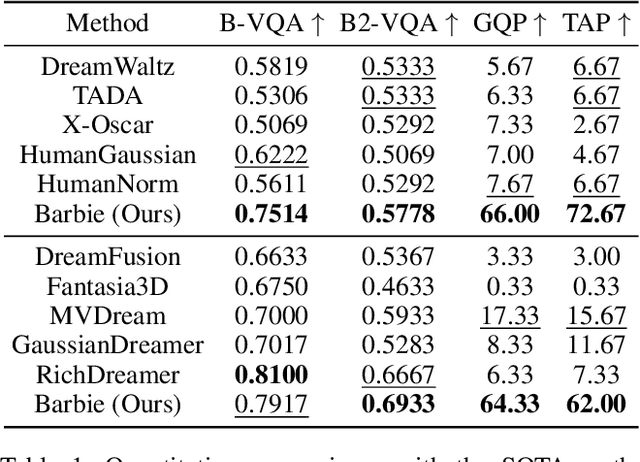

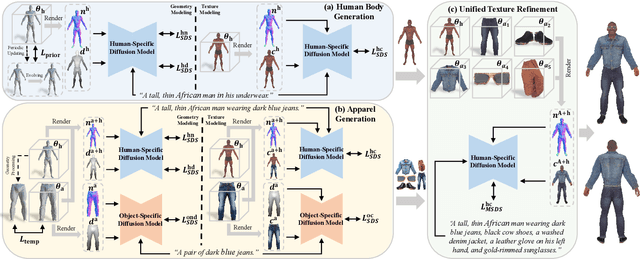
Recent advances in text-guided 3D avatar generation have made substantial progress by distilling knowledge from diffusion models. Despite the plausible generated appearance, existing methods cannot achieve fine-grained disentanglement or high-fidelity modeling between inner body and outfit. In this paper, we propose Barbie, a novel framework for generating 3D avatars that can be dressed in diverse and high-quality Barbie-like garments and accessories. Instead of relying on a holistic model, Barbie achieves fine-grained disentanglement on avatars by semantic-aligned separated models for human body and outfits. These disentangled 3D representations are then optimized by different expert models to guarantee the domain-specific fidelity. To balance geometry diversity and reasonableness, we propose a series of losses for template-preserving and human-prior evolving. The final avatar is enhanced by unified texture refinement for superior texture consistency. Extensive experiments demonstrate that Barbie outperforms existing methods in both dressed human and outfit generation, supporting flexible apparel combination and animation. The code will be released for research purposes. Our project page is: https://2017211801.github.io/barbie.github.io/.