 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent RL Scaling Law: Agent RL with Spontaneous Code Execution for Mathematical Problem Solving
May 14, 2025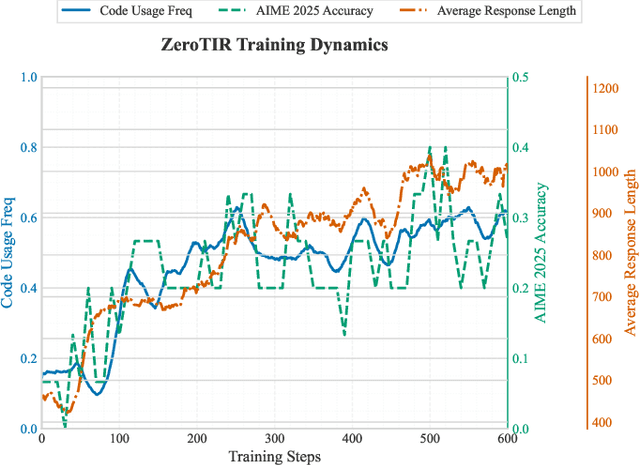
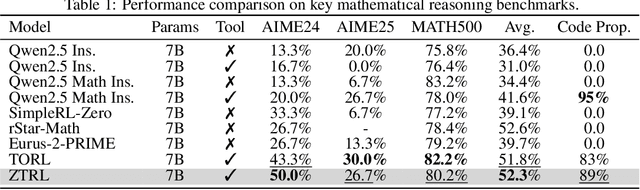

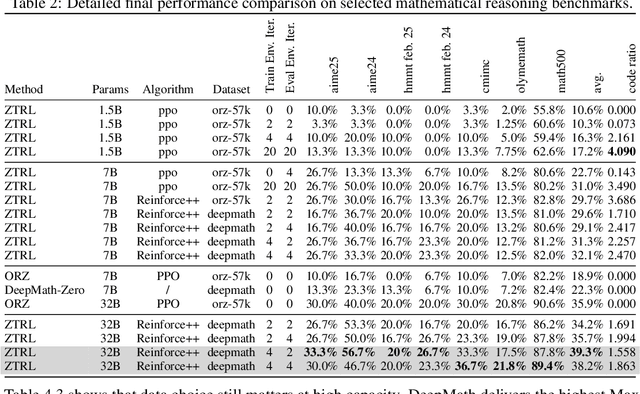
Large Language Models (LLMs) often struggle with mathematical reasoning tasks requiring precise, verifiable computation. While Reinforcement Learning (RL) from outcome-based rewards enhances text-based reasoning, understanding how agents autonomously learn to leverage external tools like code execution remains crucial. We investigate RL from outcome-based rewards for Tool-Integrated Reasoning, ZeroTIR, training base LLMs to spontaneously generate and execute Python code for mathematical problems without supervised tool-use examples. Our central contribution is we demonstrate that as RL training progresses, key metrics scale predictably. Specifically, we observe strong positive correlations where increased training steps lead to increases in the spontaneous code execution frequency, the average response length, and, critically, the final task accuracy. This suggests a quantifiable relationship between computational effort invested in training and the emergence of effective, tool-augmented reasoning strategies. We implement a robust framework featuring a decoupled code execution environment and validate our findings across standard RL algorithms and frameworks. Experiments show ZeroTIR significantly surpasses non-tool ZeroRL baselines on challenging math benchmarks. Our findings provide a foundational understanding of how autonomous tool use is acquired and scales within Agent RL, offering a reproducible benchmark for future studies. Code is released at \href{https://github.com/yyht/openrlhf_async_pipline}{https://github.com/yyht/openrlhf\_async\_pipline}.
Component-aware Unsupervised Logical Anomaly Generation for Industrial Anomaly Detection
Feb 17, 2025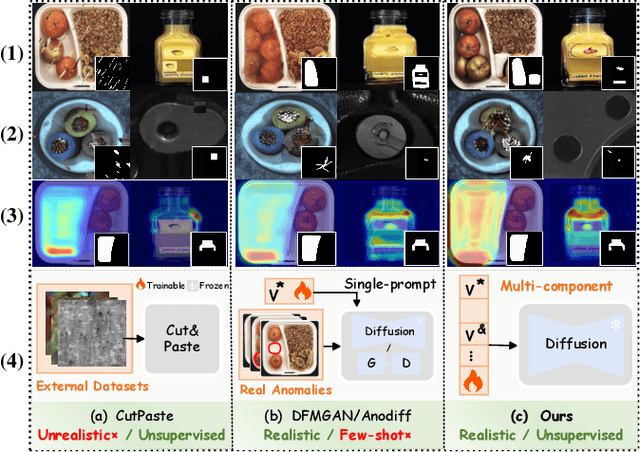
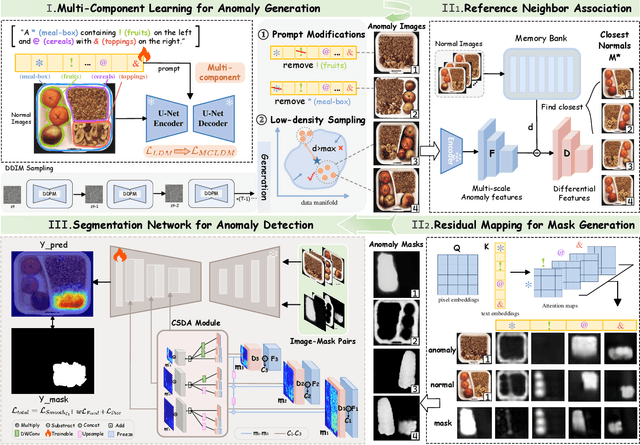
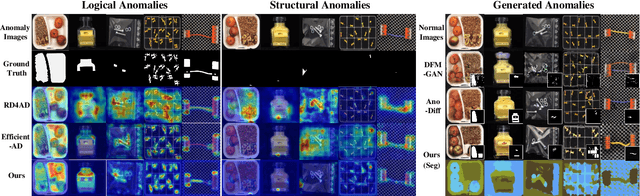

Anomaly detection is critical in industrial manufacturing for ensuring product quality and improving efficiency in automated processes. The scarcity of anomalous samples limits traditional detection methods, making anomaly generation essential for expanding the data repository. However, recent generative models often produce unrealistic anomalies increasing false positives, or require real-world anomaly samples for training. In this work, we treat anomaly generation as a compositional problem and propose ComGEN, a component-aware and unsupervised framework that addresses the gap in logical anomaly generation. Our method comprises a multi-component learning strategy to disentangle visual components, followed by subsequent generation editing procedures. Disentangled text-to-component pairs, revealing intrinsic logical constraints, conduct attention-guided residual mapping and model training with iteratively matched references across multiple scales. Experiments on the MVTecLOCO dataset confirm the efficacy of ComGEN, achieving the best AUROC score of 91.2%. Additional experiments on the real-world scenario of Diesel Engine and widely-used MVTecAD dataset demonstrate significant performance improvements when integrating simulated anomalies generated by ComGEN into automated production workflows.
A Survey on Facial Expression Recognition of Static and Dynamic Emotions
Aug 28, 2024



Facial expression recognition (FER) aims to analyze emotional states from static images and dynamic sequences, which is pivotal in enhancing anthropomorphic communication among humans, robots, and digital avatars by leveraging AI technologies. As the FER field evolves from controlled laboratory environments to more complex in-the-wild scenarios, advanced methods have been rapidly developed and new challenges and apporaches are encounted, which are not well addressed in existing reviews of FER. This paper offers a comprehensive survey of both image-based static FER (SFER) and video-based dynamic FER (DFER) methods, analyzing from model-oriented development to challenge-focused categorization. We begin with a critical comparison of recent reviews, an introduction to common datasets and evaluation criteria, and an in-depth workflow on FER to establish a robust research foundation. We then systematically review representative approaches addressing eight main challenges in SFER (such as expression disturbance, uncertainties, compound emotions, and cross-domain inconsistency) as well as seven main challenges in DFER (such as key frame sampling, expression intensity variations, and cross-modal alignment). Additionally, we analyze recent advancements, benchmark performances, major applications, and ethical considerations. Finally, we propose five promising future directions and development trends to guide ongoing research. The project page for this paper can be found at https://github.com/wangyanckxx/SurveyFER.
Hi-EF: Benchmarking Emotion Forecasting in Human-interaction
Jul 23, 2024



Affective Forecasting, a research direction in psychology that predicts individuals future emotions, is often constrained by numerous external factors like social influence and temporal distance. To address this, we transform Affective Forecasting into a Deep Learning problem by designing an Emotion Forecasting paradigm based on two-party interactions. We propose a novel Emotion Forecasting (EF) task grounded in the theory that an individuals emotions are easily influenced by the emotions or other information conveyed during interactions with another person. To tackle this task, we have developed a specialized dataset, Human-interaction-based Emotion Forecasting (Hi-EF), which contains 3069 two-party Multilayered-Contextual Interaction Samples (MCIS) with abundant affective-relevant labels and three modalities. Hi-EF not only demonstrates the feasibility of the EF task but also highlights its potential. Additionally, we propose a methodology that establishes a foundational and referential baseline model for the EF task and extensive experiments are provided. The dataset and code is available at https://github.com/Anonymize-Author/Hi-EF.
All rivers run into the sea: Unified Modality Brain-like Emotional Central Mechanism
Jul 22, 2024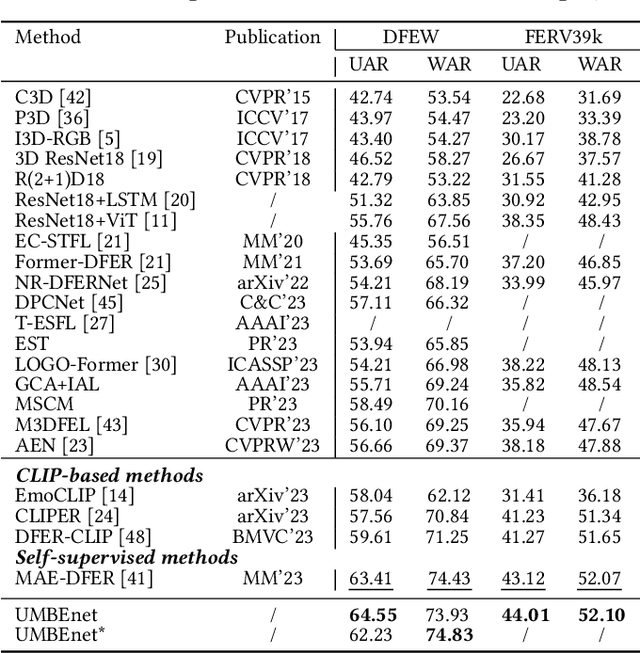


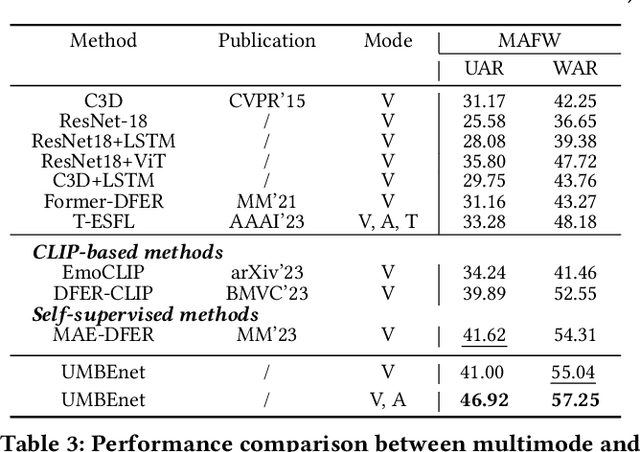
In the field of affective computing, fully leveraging information from a variety of sensory modalities is essential for the comprehensive understanding and processing of human emotions. Inspired by the process through which the human brain handles emotions and the theory of cross-modal plasticity, we propose UMBEnet, a brain-like unified modal affective processing network. The primary design of UMBEnet includes a Dual-Stream (DS) structure that fuses inherent prompts with a Prompt Pool and a Sparse Feature Fusion (SFF) module. The design of the Prompt Pool is aimed at integrating information from different modalities, while inherent prompts are intended to enhance the system's predictive guidance capabilities and effectively manage knowledge related to emotion classification. Moreover, considering the sparsity of effective information across different modalities, the SSF module aims to make full use of all available sensory data through the sparse integration of modality fusion prompts and inherent prompts, maintaining high adaptability and sensitivity to complex emotional states. Extensive experiments on the largest benchmark datasets in the Dynamic Facial Expression Recognition (DFER) field, including DFEW, FERV39k, and MAFW, have proven that UMBEnet consistently outperforms the current state-of-the-art methods. Notably, in scenarios of Modality Missingness and multimodal contexts, UMBEnet significantly surpasses the leading current methods, demonstrating outstanding performance and adaptability in tasks that involve complex emotional understanding with rich multimodal information.
From Efficient Multimodal Models to World Models: A Survey
Jun 27, 2024
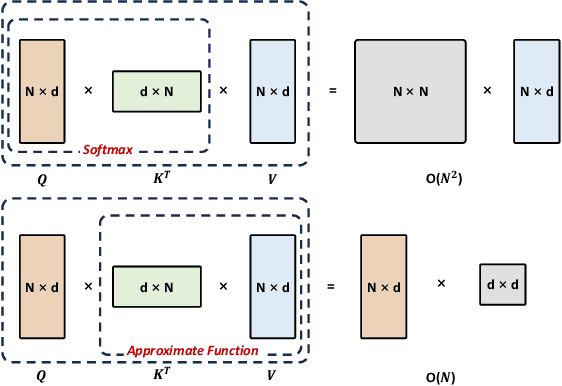
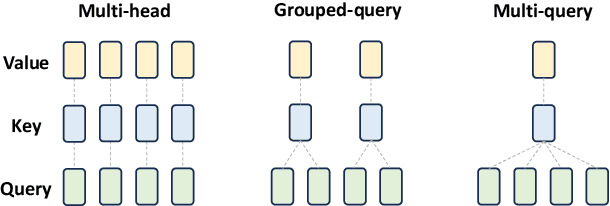

Multimodal Large Models (MLMs) are becoming a significant research focus, combining powerful large language models with multimodal learning to perform complex tasks across different data modalities. This review explores the latest developments and challenges in MLMs, emphasizing their potential in achieving artificial general intelligence and as a pathway to world models. We provide an overview of key techniques such as Multimodal Chain of Thought (M-COT), Multimodal Instruction Tuning (M-IT), and Multimodal In-Context Learning (M-ICL). Additionally, we discuss both the fundamental and specific technologies of multimodal models, highlighting their applications, input/output modalities, and design characteristics. Despite significant advancements, the development of a unified multimodal model remains elusive. We discuss the integration of 3D generation and embodied intelligence to enhance world simulation capabilities and propose incorporating external rule systems for improved reasoning and decision-making. Finally, we outline future research directions to address these challenges and advance the field.
Suppressing Uncertainties in Degradation Estimation for Blind Super-Resolution
Jun 24, 2024



The problem of blind image super-resolution aims to recover high-resolution (HR) images from low-resolution (LR) images with unknown degradation modes. Most existing methods model the image degradation process using blur kernels. However, this explicit modeling approach struggles to cover the complex and varied degradation processes encountered in the real world, such as high-order combinations of JPEG compression, blur, and noise. Implicit modeling for the degradation process can effectively overcome this issue, but a key challenge of implicit modeling is the lack of accurate ground truth labels for the degradation process to conduct supervised training. To overcome this limitations inherent in implicit modeling, we propose an \textbf{U}ncertainty-based degradation representation for blind \textbf{S}uper-\textbf{R}esolution framework (\textbf{USR}). By suppressing the uncertainty of local degradation representations in images, USR facilitated self-supervised learning of degradation representations. The USR consists of two components: Adaptive Uncertainty-Aware Degradation Extraction (AUDE) and a feature extraction network composed of Variable Depth Dynamic Convolution (VDDC) blocks. To extract Uncertainty-based Degradation Representation from LR images, the AUDE utilizes the Self-supervised Uncertainty Contrast module with Uncertainty Suppression Loss to suppress the inherent model uncertainty of the Degradation Extractor. Furthermore, VDDC block integrates degradation information through dynamic convolution. Rhe VDDC also employs an Adaptive Intensity Scaling operation that adaptively adjusts the degradation representation according to the network hierarchy, thereby facilitating the effective integration of degradation information. Quantitative and qualitative experiments affirm the superiority of our approach.
Seeking Certainty In Uncertainty: Dual-Stage Unified Framework Solving Uncertainty in Dynamic Facial Expression Recognition
Jun 24, 2024



The contemporary state-of-the-art of Dynamic Facial Expression Recognition (DFER) technology facilitates remarkable progress by deriving emotional mappings of facial expressions from video content, underpinned by training on voluminous datasets. Yet, the DFER datasets encompass a substantial volume of noise data. Noise arises from low-quality captures that defy logical labeling, and instances that suffer from mislabeling due to annotation bias, engendering two principal types of uncertainty: the uncertainty regarding data usability and the uncertainty concerning label reliability. Addressing the two types of uncertainty, we have meticulously crafted a two-stage framework aiming at \textbf{S}eeking \textbf{C}ertain data \textbf{I}n extensive \textbf{U}ncertain data (SCIU). This initiative aims to purge the DFER datasets of these uncertainties, thereby ensuring that only clean, verified data is employed in training processes. To mitigate the issue of low-quality samples, we introduce the Coarse-Grained Pruning (CGP) stage, which assesses sample weights and prunes those deemed unusable due to their low weight. For samples with incorrect annotations, the Fine-Grained Correction (FGC) stage evaluates prediction stability to rectify mislabeled data. Moreover, SCIU is conceived as a universally compatible, plug-and-play framework, tailored to integrate seamlessly with prevailing DFER methodologies. Rigorous experiments across prevalent DFER datasets and against numerous benchmark methods substantiates SCIU's capacity to markedly elevate performance metrics.
OUS: Scene-Guided Dynamic Facial Expression Recognition
May 29, 2024



Dynamic Facial Expression Recognition (DFER) is crucial for affective computing but often overlooks the impact of scene context. We have identified a significant issue in current DFER tasks: human annotators typically integrate emotions from various angles, including environmental cues and body language, whereas existing DFER methods tend to consider the scene as noise that needs to be filtered out, focusing solely on facial information. We refer to this as the Rigid Cognitive Problem. The Rigid Cognitive Problem can lead to discrepancies between the cognition of annotators and models in some samples. To align more closely with the human cognitive paradigm of emotions, we propose an Overall Understanding of the Scene DFER method (OUS). OUS effectively integrates scene and facial features, combining scene-specific emotional knowledge for DFER. Extensive experiments on the two largest datasets in the DFER field, DFEW and FERV39k, demonstrate that OUS significantly outperforms existing methods. By analyzing the Rigid Cognitive Problem, OUS successfully understands the complex relationship between scene context and emotional expression, closely aligning with human emotional understanding in real-world scenarios.
Adaptive Multi-modal Fusion of Spatially Variant Kernel Refinement with Diffusion Model for Blind Image Super-Resolution
Mar 09, 2024Pre-trained diffusion models utilized for image generation encapsulate a substantial reservoir of a priori knowledge pertaining to intricate textures. Harnessing the potential of leveraging this a priori knowledge in the context of image super-resolution presents a compelling avenue. Nonetheless, prevailing diffusion-based methodologies presently overlook the constraints imposed by degradation information on the diffusion process. Furthermore, these methods fail to consider the spatial variability inherent in the estimated blur kernel, stemming from factors such as motion jitter and out-of-focus elements in open-environment scenarios. This oversight results in a notable deviation of the image super-resolution effect from fundamental realities. To address these concerns, we introduce a framework known as Adaptive Multi-modal Fusion of \textbf{S}patially Variant Kernel Refinement with Diffusion Model for Blind Image \textbf{S}uper-\textbf{R}esolution (SSR). Within the SSR framework, we propose a Spatially Variant Kernel Refinement (SVKR) module. SVKR estimates a Depth-Informed Kernel, which takes the depth information into account and is spatially variant. Additionally, SVKR enhance the accuracy of depth information acquired from LR images, allowing for mutual enhancement between the depth map and blur kernel estimates. Finally, we introduce the Adaptive Multi-Modal Fusion (AMF) module to align the information from three modalities: low-resolution images, depth maps, and blur kernels. This alignment can constrain the diffusion model to generate more authentic SR results. Quantitative and qualitative experiments affirm the superiority of our approach, while ablation experiments corroborate the effectiveness of the modules we have proposed.