 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
Commonality in Few: Few-Shot Multimodal Anomaly Detection via Hypergraph-Enhanced Memory
Nov 16, 2025
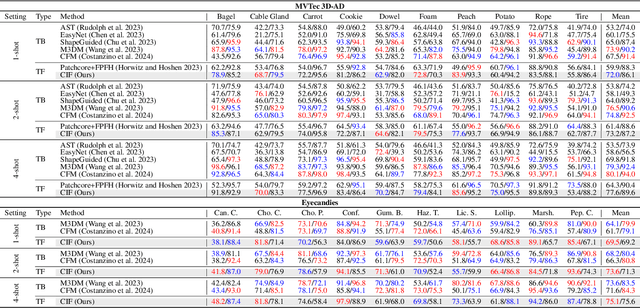
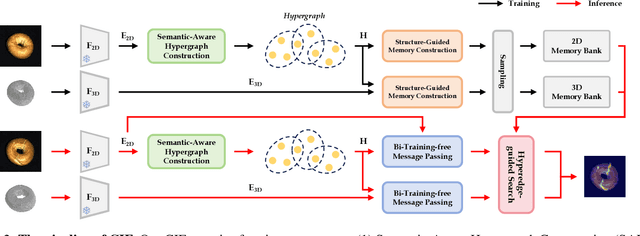

Few-shot multimodal industrial anomaly detection is a critical yet underexplored task, offering the ability to quickly adapt to complex industrial scenarios. In few-shot settings, insufficient training samples often fail to cover the diverse patterns present in test samples. This challenge can be mitigated by extracting structural commonality from a small number of training samples. In this paper, we propose a novel few-shot unsupervised multimodal industrial anomaly detection method based on structural commonality, CIF (Commonality In Few). To extract intra-class structural information, we employ hypergraphs, which are capable of modeling higher-order correlations, to capture the structural commonality within training samples, and use a memory bank to store this intra-class structural prior. Firstly, we design a semantic-aware hypergraph construction module tailored for single-semantic industrial images, from which we extract common structures to guide the construction of the memory bank. Secondly, we use a training-free hypergraph message passing module to update the visual features of test samples, reducing the distribution gap between test features and features in the memory bank. We further propose a hyperedge-guided memory search module, which utilizes structural information to assist the memory search process and reduce the false positive rate. Experimental results on the MVTec 3D-AD dataset and the Eyecandies dataset show that our method outperforms the state-of-the-art (SOTA) methods in few-shot settings. Code is available at https://github.com/Sunny5250/CIF.
Zero-P-to-3: Zero-Shot Partial-View Images to 3D Object
May 29, 2025



Generative 3D reconstruction shows strong potential in incomplete observations. While sparse-view and single-image reconstruction are well-researched, partial observation remains underexplored. In this context, dense views are accessible only from a specific angular range, with other perspectives remaining inaccessible. This task presents two main challenges: (i) limited View Range: observations confined to a narrow angular scope prevent effective traditional interpolation techniques that require evenly distributed perspectives. (ii) inconsistent Generation: views created for invisible regions often lack coherence with both visible regions and each other, compromising reconstruction consistency. To address these challenges, we propose \method, a novel training-free approach that integrates the local dense observations and multi-source priors for reconstruction. Our method introduces a fusion-based strategy to effectively align these priors in DDIM sampling, thereby generating multi-view consistent images to supervise invisible views. We further design an iterative refinement strategy, which uses the geometric structures of the object to enhance reconstruction quality. Extensive experiments on multiple datasets show the superiority of our method over SOTAs, especially in invisible regions.
Component-aware Unsupervised Logical Anomaly Generation for Industrial Anomaly Detection
Feb 17, 2025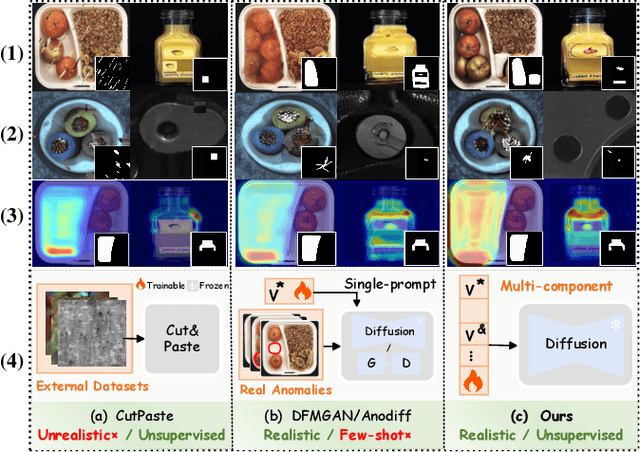
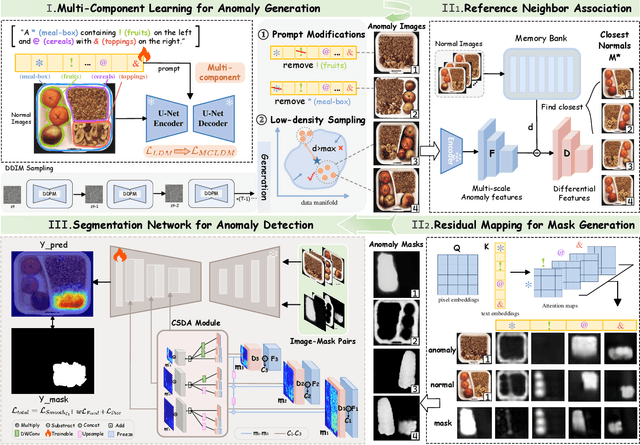
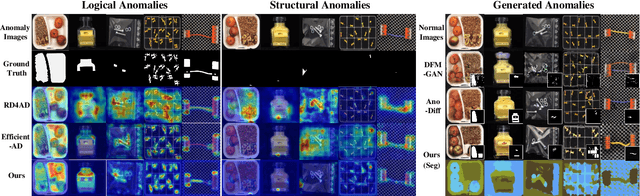

Anomaly detection is critical in industrial manufacturing for ensuring product quality and improving efficiency in automated processes. The scarcity of anomalous samples limits traditional detection methods, making anomaly generation essential for expanding the data repository. However, recent generative models often produce unrealistic anomalies increasing false positives, or require real-world anomaly samples for training. In this work, we treat anomaly generation as a compositional problem and propose ComGEN, a component-aware and unsupervised framework that addresses the gap in logical anomaly generation. Our method comprises a multi-component learning strategy to disentangle visual components, followed by subsequent generation editing procedures. Disentangled text-to-component pairs, revealing intrinsic logical constraints, conduct attention-guided residual mapping and model training with iteratively matched references across multiple scales. Experiments on the MVTecLOCO dataset confirm the efficacy of ComGEN, achieving the best AUROC score of 91.2%. Additional experiments on the real-world scenario of Diesel Engine and widely-used MVTecAD dataset demonstrate significant performance improvements when integrating simulated anomalies generated by ComGEN into automated production workflows.
A Survey on RGB, 3D, and Multimodal Approaches for Unsupervised Industrial Anomaly Detection
Oct 29, 2024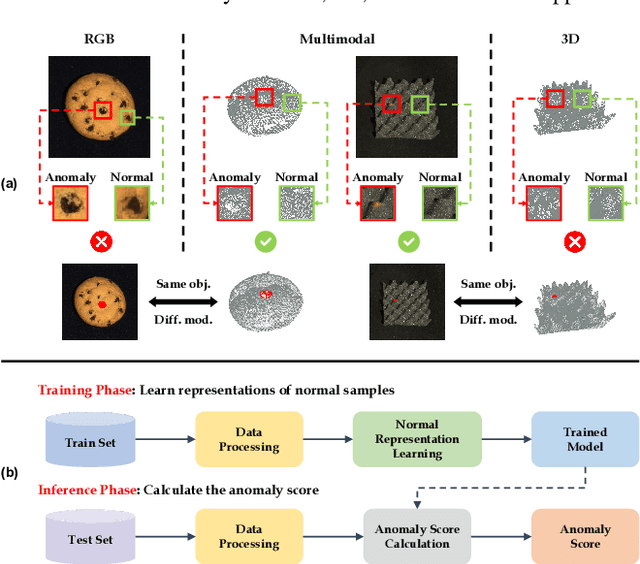
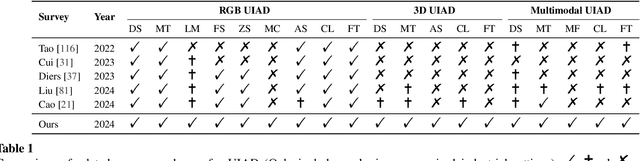
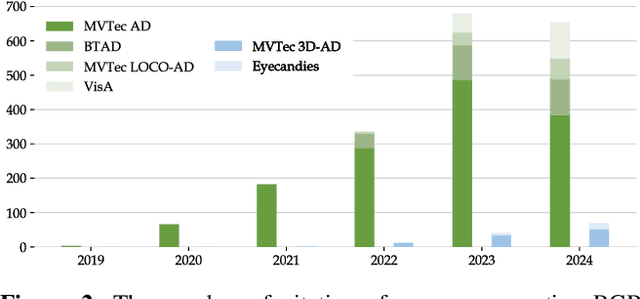
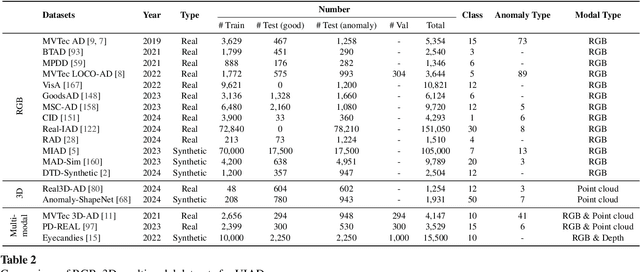
In the advancement of industrial informatization, Unsupervised Industrial Anomaly Detection (UIAD) technology effectively overcomes the scarcity of abnormal samples and significantly enhances the automation and reliability of smart manufacturing. While RGB, 3D, and multimodal anomaly detection have demonstrated comprehensive and robust capabilities within the industrial informatization sector, existing reviews on industrial anomaly detection have not sufficiently classified and discussed methods in 3D and multimodal settings. We focus on 3D UIAD and multimodal UIAD, providing a comprehensive summary of unsupervised industrial anomaly detection in three modal settings. Firstly, we compare our surveys with recent works, introducing commonly used datasets, evaluation metrics, and the definitions of anomaly detection problems. Secondly, we summarize five research paradigms in RGB, 3D and multimodal UIAD and three emerging industrial manufacturing optimization directions in RGB UIAD, and review three multimodal feature fusion strategies in multimodal settings. Finally, we outline the primary challenges currently faced by UIAD in three modal settings, and offer insights into future development directions, aiming to provide researchers with a thorough reference and offer new perspectives for the advancement of industrial informatization. Corresponding resources are available at https://github.com/Sunny5250/Awesome-Multi-Setting-UIAD.
Suppressing Uncertainties in Degradation Estimation for Blind Super-Resolution
Jun 24, 2024



The problem of blind image super-resolution aims to recover high-resolution (HR) images from low-resolution (LR) images with unknown degradation modes. Most existing methods model the image degradation process using blur kernels. However, this explicit modeling approach struggles to cover the complex and varied degradation processes encountered in the real world, such as high-order combinations of JPEG compression, blur, and noise. Implicit modeling for the degradation process can effectively overcome this issue, but a key challenge of implicit modeling is the lack of accurate ground truth labels for the degradation process to conduct supervised training. To overcome this limitations inherent in implicit modeling, we propose an \textbf{U}ncertainty-based degradation representation for blind \textbf{S}uper-\textbf{R}esolution framework (\textbf{USR}). By suppressing the uncertainty of local degradation representations in images, USR facilitated self-supervised learning of degradation representations. The USR consists of two components: Adaptive Uncertainty-Aware Degradation Extraction (AUDE) and a feature extraction network composed of Variable Depth Dynamic Convolution (VDDC) blocks. To extract Uncertainty-based Degradation Representation from LR images, the AUDE utilizes the Self-supervised Uncertainty Contrast module with Uncertainty Suppression Loss to suppress the inherent model uncertainty of the Degradation Extractor. Furthermore, VDDC block integrates degradation information through dynamic convolution. Rhe VDDC also employs an Adaptive Intensity Scaling operation that adaptively adjusts the degradation representation according to the network hierarchy, thereby facilitating the effective integration of degradation information. Quantitative and qualitative experiments affirm the superiority of our approach.
Adaptive Multi-modal Fusion of Spatially Variant Kernel Refinement with Diffusion Model for Blind Image Super-Resolution
Mar 09, 2024Pre-trained diffusion models utilized for image generation encapsulate a substantial reservoir of a priori knowledge pertaining to intricate textures. Harnessing the potential of leveraging this a priori knowledge in the context of image super-resolution presents a compelling avenue. Nonetheless, prevailing diffusion-based methodologies presently overlook the constraints imposed by degradation information on the diffusion process. Furthermore, these methods fail to consider the spatial variability inherent in the estimated blur kernel, stemming from factors such as motion jitter and out-of-focus elements in open-environment scenarios. This oversight results in a notable deviation of the image super-resolution effect from fundamental realities. To address these concerns, we introduce a framework known as Adaptive Multi-modal Fusion of \textbf{S}patially Variant Kernel Refinement with Diffusion Model for Blind Image \textbf{S}uper-\textbf{R}esolution (SSR). Within the SSR framework, we propose a Spatially Variant Kernel Refinement (SVKR) module. SVKR estimates a Depth-Informed Kernel, which takes the depth information into account and is spatially variant. Additionally, SVKR enhance the accuracy of depth information acquired from LR images, allowing for mutual enhancement between the depth map and blur kernel estimates. Finally, we introduce the Adaptive Multi-Modal Fusion (AMF) module to align the information from three modalities: low-resolution images, depth maps, and blur kernels. This alignment can constrain the diffusion model to generate more authentic SR results. Quantitative and qualitative experiments affirm the superiority of our approach, while ablation experiments corroborate the effectiveness of the modules we have proposed.