 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Learning-Based Motion Planning: Toward a Data-Driven Optimal Control Approach
Dec 12, 2025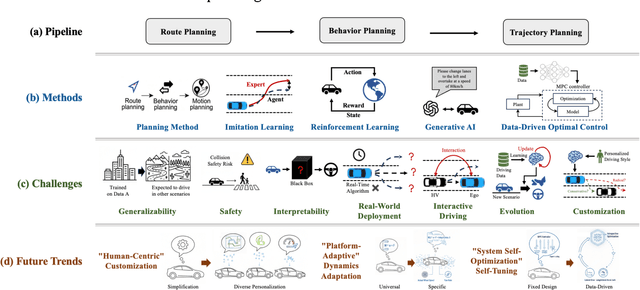
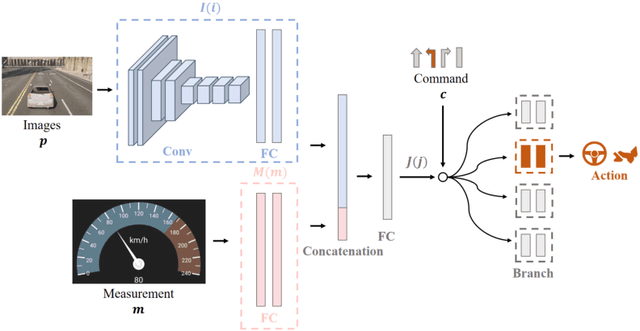
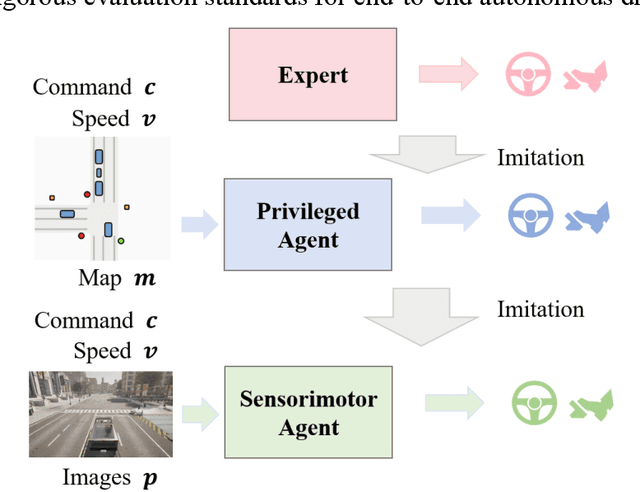
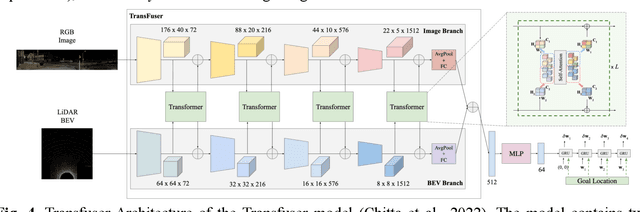
Motion planning for high-level autonomous driving is constrained by a fundamental trade-off between the transparent, yet brittle, nature of pipeline methods and the adaptive, yet opaque, "black-box" characteristics of modern learning-based systems. This paper critically synthesizes the evolution of the field -- from pipeline methods through imitation learning, reinforcement learning, and generative AI -- to demonstrate how this persistent dilemma has hindered the development of truly trustworthy systems. To resolve this impasse, we conduct a comprehensive review of learning-based motion planning methods. Based on this review, we outline a data-driven optimal control paradigm as a unifying framework that synergistically integrates the verifiable structure of classical control with the adaptive capacity of machine learning, leveraging real-world data to continuously refine key components such as system dynamics, cost functions, and safety constraints. We explore this framework's potential to enable three critical next-generation capabilities: "Human-Centric" customization, "Platform-Adaptive" dynamics adaptation, and "System Self-Optimization" via self-tuning. We conclude by proposing future research directions based on this paradigm, aimed at developing intelligent transportation systems that are simultaneously safe, interpretable, and capable of human-like autonomy.
Commonality in Few: Few-Shot Multimodal Anomaly Detection via Hypergraph-Enhanced Memory
Nov 16, 2025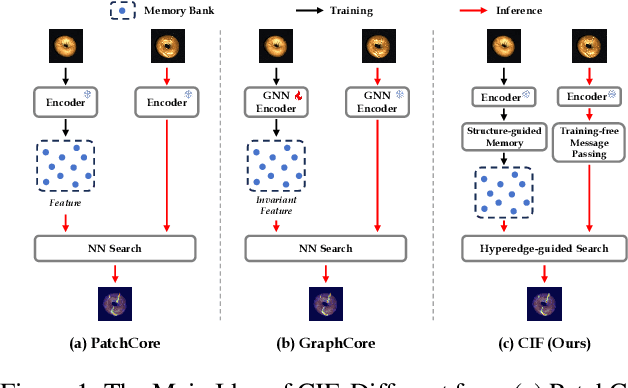
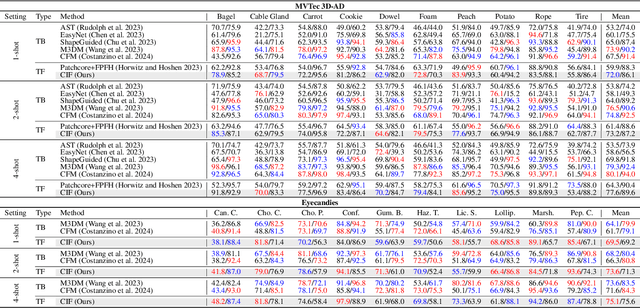
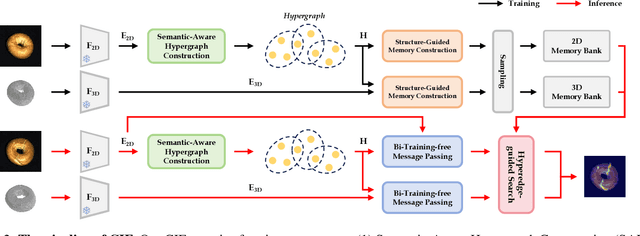

Few-shot multimodal industrial anomaly detection is a critical yet underexplored task, offering the ability to quickly adapt to complex industrial scenarios. In few-shot settings, insufficient training samples often fail to cover the diverse patterns present in test samples. This challenge can be mitigated by extracting structural commonality from a small number of training samples. In this paper, we propose a novel few-shot unsupervised multimodal industrial anomaly detection method based on structural commonality, CIF (Commonality In Few). To extract intra-class structural information, we employ hypergraphs, which are capable of modeling higher-order correlations, to capture the structural commonality within training samples, and use a memory bank to store this intra-class structural prior. Firstly, we design a semantic-aware hypergraph construction module tailored for single-semantic industrial images, from which we extract common structures to guide the construction of the memory bank. Secondly, we use a training-free hypergraph message passing module to update the visual features of test samples, reducing the distribution gap between test features and features in the memory bank. We further propose a hyperedge-guided memory search module, which utilizes structural information to assist the memory search process and reduce the false positive rate. Experimental results on the MVTec 3D-AD dataset and the Eyecandies dataset show that our method outperforms the state-of-the-art (SOTA) methods in few-shot settings. Code is available at https://github.com/Sunny5250/CIF.
Component-aware Unsupervised Logical Anomaly Generation for Industrial Anomaly Detection
Feb 17, 2025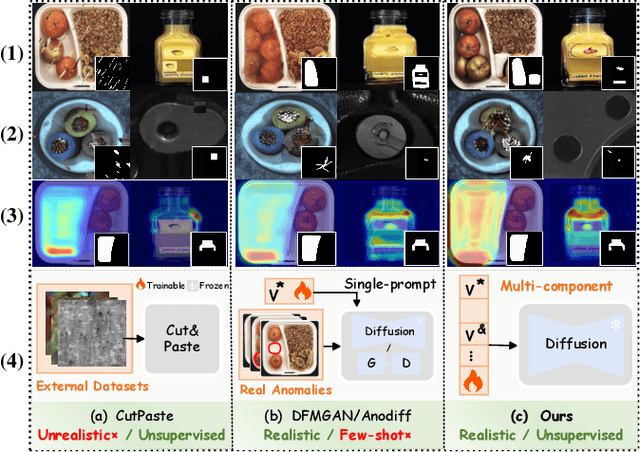
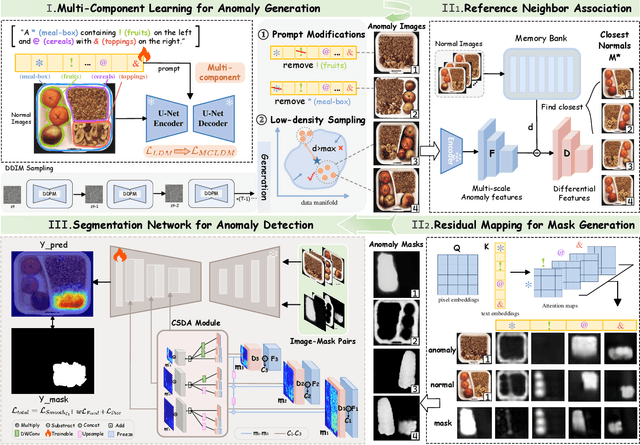
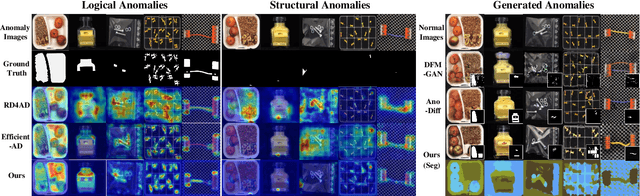

Anomaly detection is critical in industrial manufacturing for ensuring product quality and improving efficiency in automated processes. The scarcity of anomalous samples limits traditional detection methods, making anomaly generation essential for expanding the data repository. However, recent generative models often produce unrealistic anomalies increasing false positives, or require real-world anomaly samples for training. In this work, we treat anomaly generation as a compositional problem and propose ComGEN, a component-aware and unsupervised framework that addresses the gap in logical anomaly generation. Our method comprises a multi-component learning strategy to disentangle visual components, followed by subsequent generation editing procedures. Disentangled text-to-component pairs, revealing intrinsic logical constraints, conduct attention-guided residual mapping and model training with iteratively matched references across multiple scales. Experiments on the MVTecLOCO dataset confirm the efficacy of ComGEN, achieving the best AUROC score of 91.2%. Additional experiments on the real-world scenario of Diesel Engine and widely-used MVTecAD dataset demonstrate significant performance improvements when integrating simulated anomalies generated by ComGEN into automated production workflows.
A Survey on RGB, 3D, and Multimodal Approaches for Unsupervised Industrial Anomaly Detection
Oct 29, 2024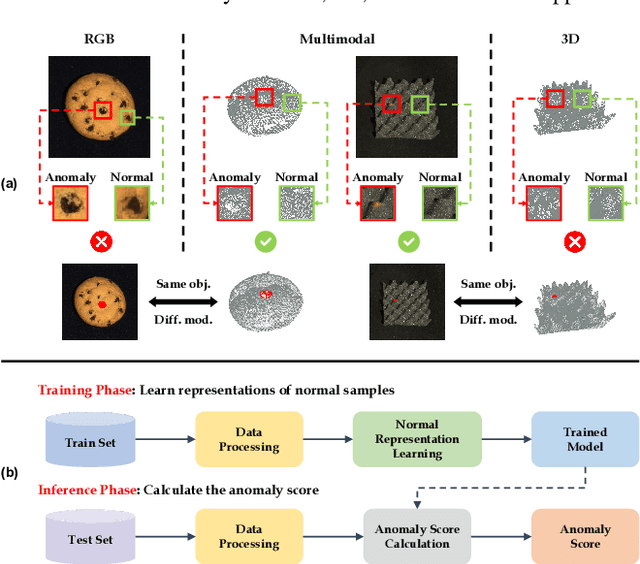
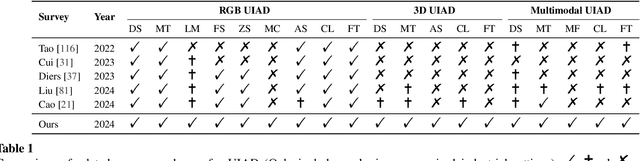
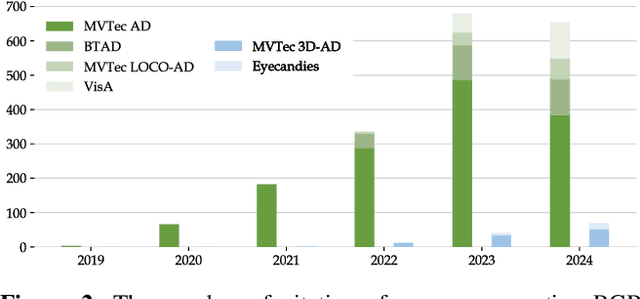
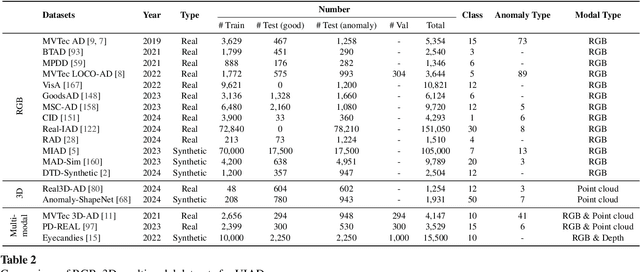
In the advancement of industrial informatization, Unsupervised Industrial Anomaly Detection (UIAD) technology effectively overcomes the scarcity of abnormal samples and significantly enhances the automation and reliability of smart manufacturing. While RGB, 3D, and multimodal anomaly detection have demonstrated comprehensive and robust capabilities within the industrial informatization sector, existing reviews on industrial anomaly detection have not sufficiently classified and discussed methods in 3D and multimodal settings. We focus on 3D UIAD and multimodal UIAD, providing a comprehensive summary of unsupervised industrial anomaly detection in three modal settings. Firstly, we compare our surveys with recent works, introducing commonly used datasets, evaluation metrics, and the definitions of anomaly detection problems. Secondly, we summarize five research paradigms in RGB, 3D and multimodal UIAD and three emerging industrial manufacturing optimization directions in RGB UIAD, and review three multimodal feature fusion strategies in multimodal settings. Finally, we outline the primary challenges currently faced by UIAD in three modal settings, and offer insights into future development directions, aiming to provide researchers with a thorough reference and offer new perspectives for the advancement of industrial informatization. Corresponding resources are available at https://github.com/Sunny5250/Awesome-Multi-Setting-UIAD.
A Survey on Facial Expression Recognition of Static and Dynamic Emotions
Aug 28, 2024



Facial expression recognition (FER) aims to analyze emotional states from static images and dynamic sequences, which is pivotal in enhancing anthropomorphic communication among humans, robots, and digital avatars by leveraging AI technologies. As the FER field evolves from controlled laboratory environments to more complex in-the-wild scenarios, advanced methods have been rapidly developed and new challenges and apporaches are encounted, which are not well addressed in existing reviews of FER. This paper offers a comprehensive survey of both image-based static FER (SFER) and video-based dynamic FER (DFER) methods, analyzing from model-oriented development to challenge-focused categorization. We begin with a critical comparison of recent reviews, an introduction to common datasets and evaluation criteria, and an in-depth workflow on FER to establish a robust research foundation. We then systematically review representative approaches addressing eight main challenges in SFER (such as expression disturbance, uncertainties, compound emotions, and cross-domain inconsistency) as well as seven main challenges in DFER (such as key frame sampling, expression intensity variations, and cross-modal alignment). Additionally, we analyze recent advancements, benchmark performances, major applications, and ethical considerations. Finally, we propose five promising future directions and development trends to guide ongoing research. The project page for this paper can be found at https://github.com/wangyanckxx/SurveyFER.
From Efficient Multimodal Models to World Models: A Survey
Jun 27, 2024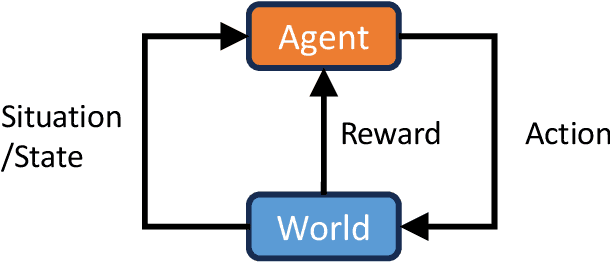
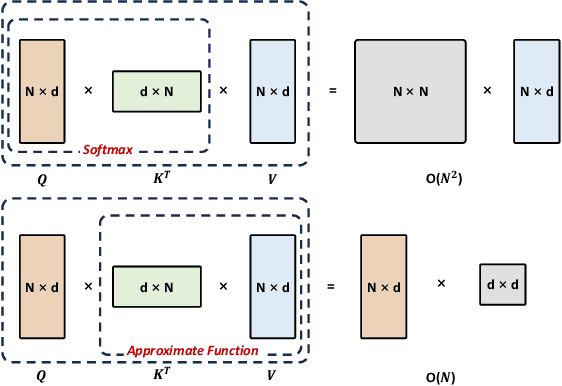

Multimodal Large Models (MLMs) are becoming a significant research focus, combining powerful large language models with multimodal learning to perform complex tasks across different data modalities. This review explores the latest developments and challenges in MLMs, emphasizing their potential in achieving artificial general intelligence and as a pathway to world models. We provide an overview of key techniques such as Multimodal Chain of Thought (M-COT), Multimodal Instruction Tuning (M-IT), and Multimodal In-Context Learning (M-ICL). Additionally, we discuss both the fundamental and specific technologies of multimodal models, highlighting their applications, input/output modalities, and design characteristics. Despite significant advancements, the development of a unified multimodal model remains elusive. We discuss the integration of 3D generation and embodied intelligence to enhance world simulation capabilities and propose incorporating external rule systems for improved reasoning and decision-making. Finally, we outline future research directions to address these challenges and advance the field.