 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Efficient Multimodal Models to World Models: A Survey
Paper and Code
Jun 27, 2024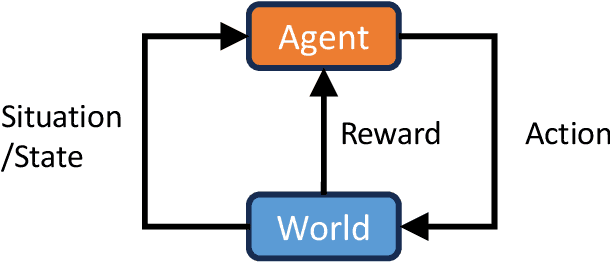
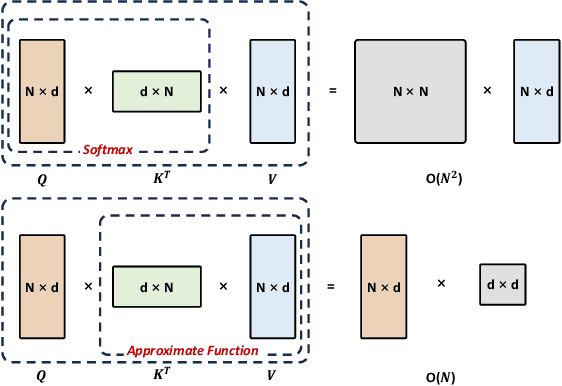
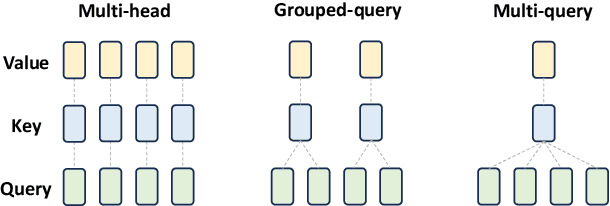

Multimodal Large Models (MLMs) are becoming a significant research focus, combining powerful large language models with multimodal learning to perform complex tasks across different data modalities. This review explores the latest developments and challenges in MLMs, emphasizing their potential in achieving artificial general intelligence and as a pathway to world models. We provide an overview of key techniques such as Multimodal Chain of Thought (M-COT), Multimodal Instruction Tuning (M-IT), and Multimodal In-Context Learning (M-ICL). Additionally, we discuss both the fundamental and specific technologies of multimodal models, highlighting their applications, input/output modalities, and design characteristics. Despite significant advancements, the development of a unified multimodal model remains elusive. We discuss the integration of 3D generation and embodied intelligence to enhance world simulation capabilities and propose incorporating external rule systems for improved reasoning and decision-making. Finally, we outline future research directions to address these challenges and advance the field.