 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Inference of Hospitalization ElectronicHealth Records Using Probabilistic Models
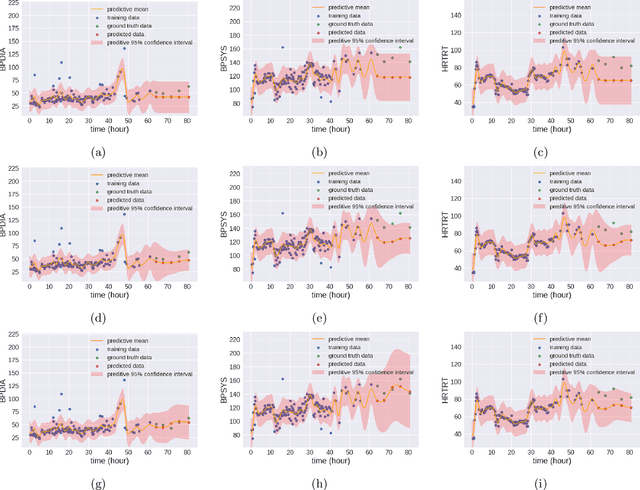
Mar 27, 2024In the dynamic hospital setting, decision support can be a valuable tool for improving patient outcomes. Data-driven inference of future outcomes is challenging in this dynamic setting, where long sequences such as laboratory tests and medications are updated frequently. This is due in part to heterogeneity of data types and mixed-sequence types contained in variable length sequences. In this work we design a probabilistic unsupervised model for multiple arbitrary-length sequences contained in hospitalization Electronic Health Record (EHR) data. The model uses a latent variable structure and captures complex relationships between medications, diagnoses, laboratory tests, neurological assessments, and medications. It can be trained on original data, without requiring any lossy transformations or time binning. Inference algorithms are derived that use partial data to infer properties of the complete sequences, including their length and presence of specific values. We train this model on data from subjects receiving medical care in the Kaiser Permanente Northern California integrated healthcare delivery system. The results are evaluated against held-out data for predicting the length of sequences and presence of Intensive Care Unit (ICU) in hospitalization bed sequences. Our method outperforms a baseline approach, showing that in these experiments the trained model captures information in the sequences that is informative of their future values.
Unsupervised Probabilistic Models for Sequential Electronic Health Records
Apr 15, 2022
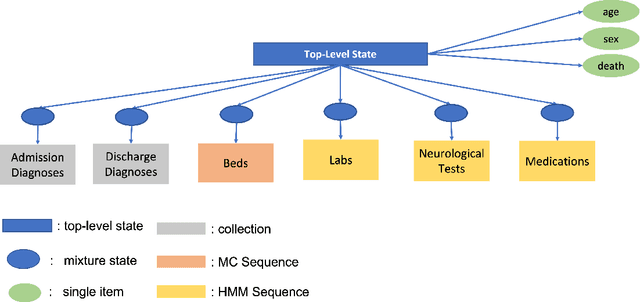
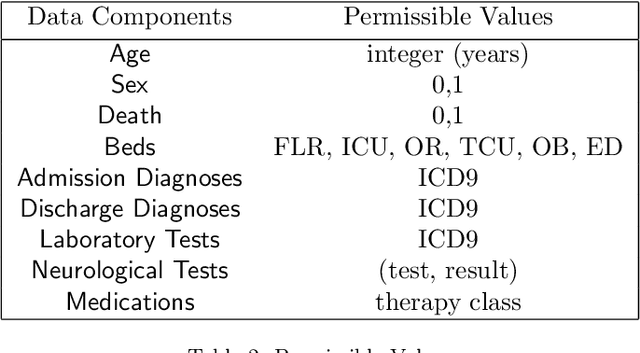
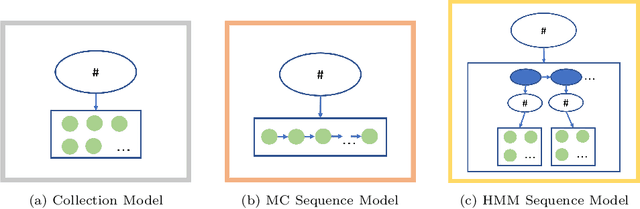
We develop an unsupervised probabilistic model for heterogeneous Electronic Health Record (EHR) data. Utilizing a mixture model formulation, our approach directly models sequences of arbitrary length, such as medications and laboratory results. This allows for subgrouping and incorporation of the dynamics underlying heterogeneous data types. The model consists of a layered set of latent variables that encode underlying structure in the data. These variables represent subject subgroups at the top layer, and unobserved states for sequences in the second layer. We train this model on episodic data from subjects receiving medical care in the Kaiser Permanente Northern California integrated healthcare delivery system. The resulting properties of the trained model generate novel insight from these complex and multifaceted data. In addition, we show how the model can be used to analyze sequences that contribute to assessment of mortality likelihood.
Nonstationary Multivariate Gaussian Processes for Electronic Health Records
Oct 13, 2019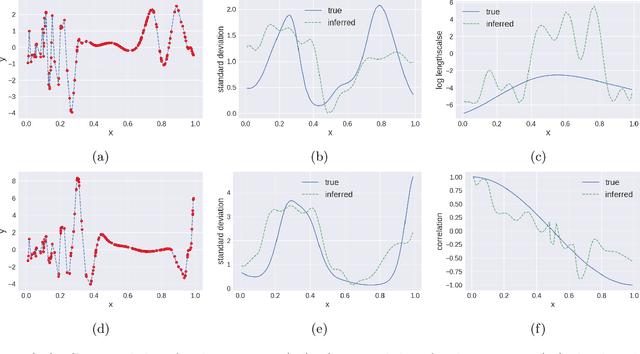

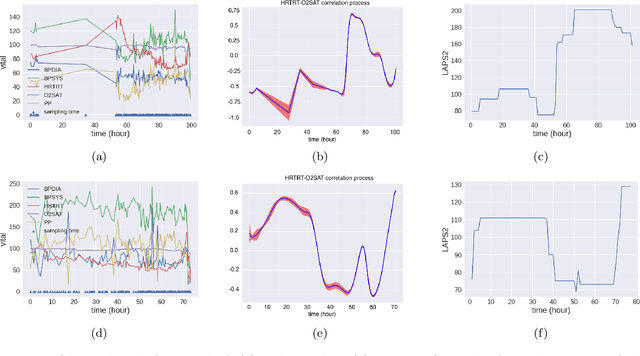
We propose multivariate nonstationary Gaussian processes for jointly modeling multiple clinical variables, where the key parameters, length-scales, standard deviations and the correlations between the observed output, are all time dependent. We perform posterior inference via Hamiltonian Monte Carlo (HMC). We also provide methods for obtaining computationally efficient gradient-based maximum a posteriori (MAP) estimates. We validate our model on synthetic data as well as on electronic health records (EHR) data from Kaiser Permanente (KP). We show that the proposed model provides better predictive performance over a stationary model as well as uncovers interesting latent correlation processes across vitals which are potentially predictive of patient risk.
Modeling sepsis progression using hidden Markov models
Jan 09, 2018
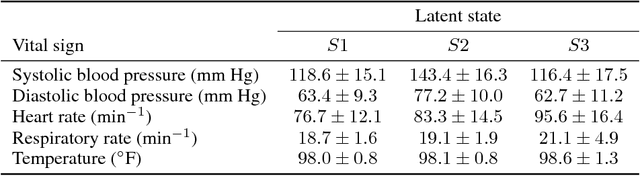
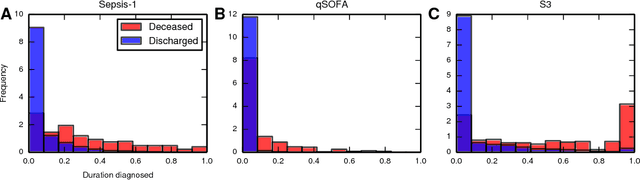
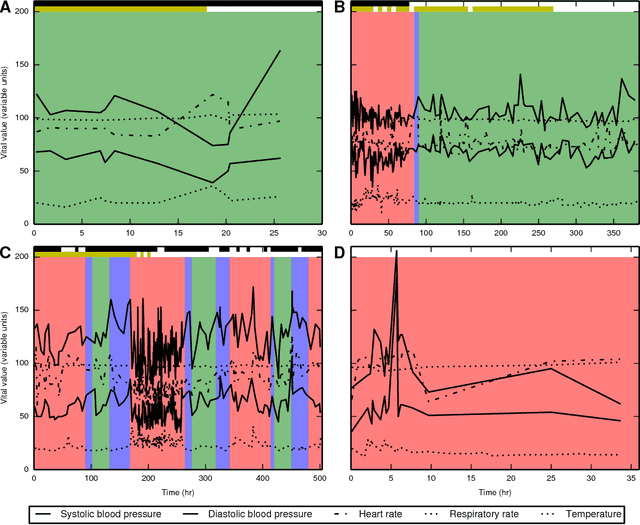
Characterizing a patient's progression through stages of sepsis is critical for enabling risk stratification and adaptive, personalized treatment. However, commonly used sepsis diagnostic criteria fail to account for significant underlying heterogeneity, both between patients as well as over time in a single patient. We introduce a hidden Markov model of sepsis progression that explicitly accounts for patient heterogeneity. Benchmarked against two sepsis diagnostic criteria, the model provides a useful tool to uncover a patient's latent sepsis trajectory and to identify high-risk patients in whom more aggressive therapy may be indicated.