 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovisVQ: A Streaming Convolutional Neural Network for No-Reference Opinion-Unaware Frame Quality Assessment
Nov 06, 2025Video quality assessment (VQA) is vital for computer vision tasks, but existing approaches face major limitations: full-reference (FR) metrics require clean reference videos, and most no-reference (NR) models depend on training on costly human opinion labels. Moreover, most opinion-unaware NR methods are image-based, ignoring temporal context critical for video object detection. In this work, we present a scalable, streaming-based VQA model that is both no-reference and opinion-unaware. Our model leverages synthetic degradations of the DAVIS dataset, training a temporal-aware convolutional architecture to predict FR metrics (LPIPS , PSNR, SSIM) directly from degraded video, without references at inference. We show that our streaming approach outperforms our own image-based baseline by generalizing across diverse degradations, underscoring the value of temporal modeling for scalable VQA in real-world vision systems. Additionally, we demonstrate that our model achieves higher correlation with full-reference metrics compared to BRISQUE, a widely-used opinion-aware image quality assessment baseline, validating the effectiveness of our temporal, opinion-unaware approach.
Addressing Issues with Working Memory in Video Object Segmentation
Oct 29, 2024Contemporary state-of-the-art video object segmentation (VOS) models compare incoming unannotated images to a history of image-mask relations via affinity or cross-attention to predict object masks. We refer to the internal memory state of the initial image-mask pair and past image-masks as a working memory buffer. While the current state of the art models perform very well on clean video data, their reliance on a working memory of previous frames leaves room for error. Affinity-based algorithms include the inductive bias that there is temporal continuity between consecutive frames. To account for inconsistent camera views of the desired object, working memory models need an algorithmic modification that regulates the memory updates and avoid writing irrelevant frames into working memory. A simple algorithmic change is proposed that can be applied to any existing working memory-based VOS model to improve performance on inconsistent views, such as sudden camera cuts, frame interjections, and extreme context changes. The resulting model performances show significant improvement on video data with these frame interjections over the same model without the algorithmic addition. Our contribution is a simple decision function that determines whether working memory should be updated based on the detection of sudden, extreme changes and the assumption that the object is no longer in frame. By implementing algorithmic changes, such as this, we can increase the real-world applicability of current VOS models.
Seeing Objects in a Cluttered World: Computational Objectness from Motion in Video
Feb 02, 2024Perception of the visually disjoint surfaces of our cluttered world as whole objects, physically distinct from those overlapping them, is a cognitive phenomenon called objectness that forms the basis of our visual perception. Shared by all vertebrates and present at birth in humans, it enables object-centric representation and reasoning about the visual world. We present a computational approach to objectness that leverages motion cues and spatio-temporal attention using a pair of supervised spatio-temporal R(2+1)U-Nets. The first network detects motion boundaries and classifies the pixels at those boundaries in terms of their local foreground-background sense. This motion boundary sense (MBS) information is passed, along with a spatio-temporal object attention cue, to an attentional surface perception (ASP) module which infers the form of the attended object over a sequence of frames and classifies its 'pixels' as visible or obscured. The spatial form of the attention cue is flexible, but it must loosely track the attended object which need not be visible. We demonstrate the ability of this simple but novel approach to infer objectness from phenomenology without object models, and show that it delivers robust perception of individual attended objects in cluttered scenes, even with blur and camera shake. We show that our data diversity and augmentation minimizes bias and facilitates transfer to real video. Finally, we describe how this computational objectness capability can grow in sophistication and anchor a robust modular video object perception framework.
Scientific Computing Algorithms to Learn Enhanced Scalable Surrogates for Mesh Physics
Apr 01, 2023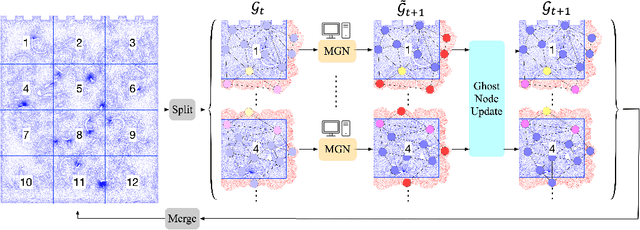

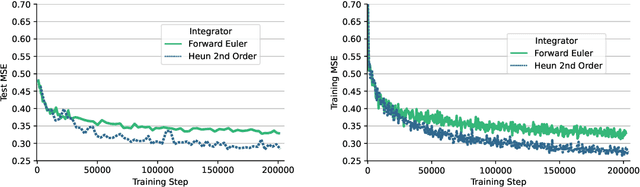
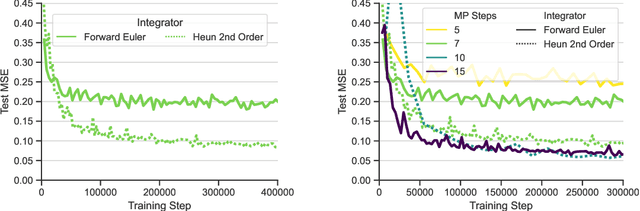
Data-driven modeling approaches can produce fast surrogates to study large-scale physics problems. Among them, graph neural networks (GNNs) that operate on mesh-based data are desirable because they possess inductive biases that promote physical faithfulness, but hardware limitations have precluded their application to large computational domains. We show that it is \textit{possible} to train a class of GNN surrogates on 3D meshes. We scale MeshGraphNets (MGN), a subclass of GNNs for mesh-based physics modeling, via our domain decomposition approach to facilitate training that is mathematically equivalent to training on the whole domain under certain conditions. With this, we were able to train MGN on meshes with \textit{millions} of nodes to generate computational fluid dynamics (CFD) simulations. Furthermore, we show how to enhance MGN via higher-order numerical integration, which can reduce MGN's error and training time. We validated our methods on an accompanying dataset of 3D $\text{CO}_2$-capture CFD simulations on a 3.1M-node mesh. This work presents a practical path to scaling MGN for real-world applications.
Detect, Retrieve, Comprehend: A Flexible Framework for Zero-Shot Document-Level Question Answering
Oct 04, 2022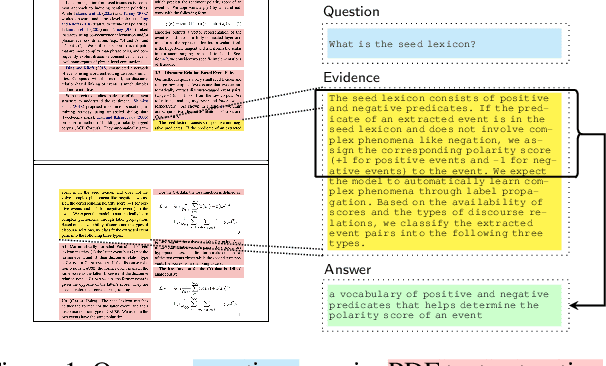
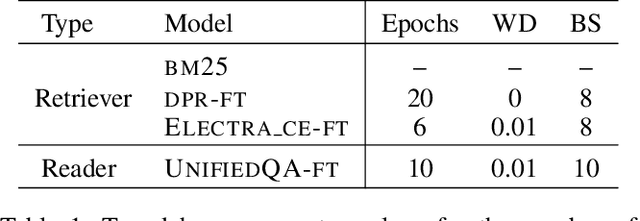
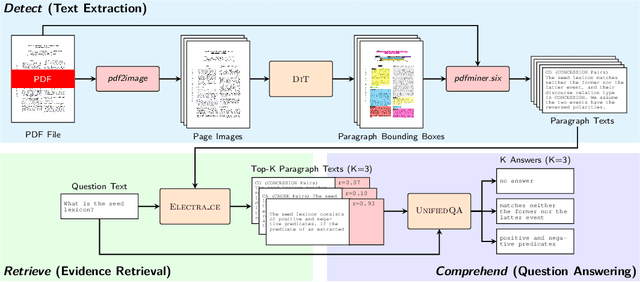

Businesses generate thousands of documents that communicate their strategic vision and provide details of key products, services, entities, and processes. Knowledge workers then face the laborious task of reading these documents to identify, extract, and synthesize information relevant to their organizational goals. To automate information gathering, question answering (QA) offers a flexible framework where human-posed questions can be adapted to extract diverse knowledge. Finetuning QA systems requires access to labeled data (tuples of context, question, and answer). However, data curation for document QA is uniquely challenging because the context (i.e., answer evidence passage) needs to be retrieved from potentially long, ill-formatted documents. Existing QA datasets sidestep this challenge by providing short, well-defined contexts that are unrealistic in real-world applications. We present a three-stage document QA approach: (1) text extraction from PDF; (2) evidence retrieval from extracted texts to form well-posed contexts; (3) QA to extract knowledge from contexts to return high-quality answers - extractive, abstractive, or Boolean. Using QASPER as a surrogate to our proprietary data, our detect-retrieve-comprehend (DRC) system achieves a +6.25 improvement in Answer-F1 over existing baselines while delivering superior context selection. Our results demonstrate that DRC holds tremendous promise as a flexible framework for practical document QA.
PrivateJobMatch: A Privacy-Oriented Deferred Multi-Match Recommender System for Stable Employment
May 11, 2019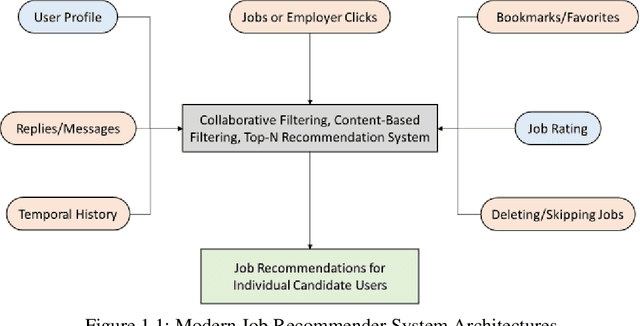


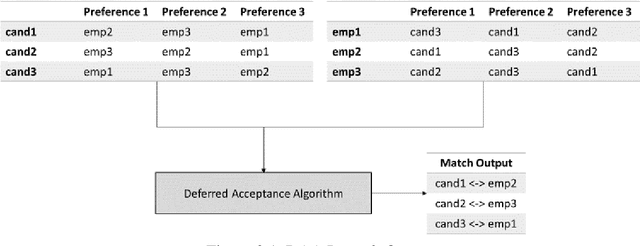
Coordination failure reduces match quality among employers and candidates in the job market, resulting in a large number of unfilled positions and/or unstable, short-term employment. Centralized job search engines provide a platform that connects directly employers with job-seekers. However, they require users to disclose a significant amount of personal data, i.e., build a user profile, in order to provide meaningful recommendations. In this paper, we present PrivateJobMatch -- a privacy-oriented deferred multi-match recommender system -- which generates stable pairings while requiring users to provide only a partial ranking of their preferences. PrivateJobMatch explores a series of adaptations of the game-theoretic Gale-Shapley deferred-acceptance algorithm which combine the flexibility of decentralized markets with the intelligence of centralized matching. We identify the shortcomings of the original algorithm when applied to a job market and propose novel solutions that rely on machine learning techniques. Experimental results on real and synthetic data confirm the benefits of the proposed algorithms across several quality measures. Over the past year, we have implemented a PrivateJobMatch prototype and deployed it in an active job market economy. Using the gathered real-user preference data, we find that the match-recommendations are superior to a typical decentralized job market---while requiring only a partial ranking of the user preferences.