 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Medical Image Analysis with Concept-based Similarity Reasoning
Mar 11, 2025The ability to interpret and intervene model decisions is important for the adoption of computer-aided diagnosis methods in clinical workflows. Recent concept-based methods link the model predictions with interpretable concepts and modify their activation scores to interact with the model. However, these concepts are at the image level, which hinders the model from pinpointing the exact patches the concepts are activated. Alternatively, prototype-based methods learn representations from training image patches and compare these with test image patches, using the similarity scores for final class prediction. However, interpreting the underlying concepts of these patches can be challenging and often necessitates post-hoc guesswork. To address this issue, this paper introduces the novel Concept-based Similarity Reasoning network (CSR), which offers (i) patch-level prototype with intrinsic concept interpretation, and (ii) spatial interactivity. First, the proposed CSR provides localized explanation by grounding prototypes of each concept on image regions. Second, our model introduces novel spatial-level interaction, allowing doctors to engage directly with specific image areas, making it an intuitive and transparent tool for medical imaging. CSR improves upon prior state-of-the-art interpretable methods by up to 4.5\% across three biomedical datasets. Our code is released at https://github.com/tadeephuy/InteractCSR.
* Accepted CVPR2025
Scientific Computing Algorithms to Learn Enhanced Scalable Surrogates for Mesh Physics
Apr 01, 2023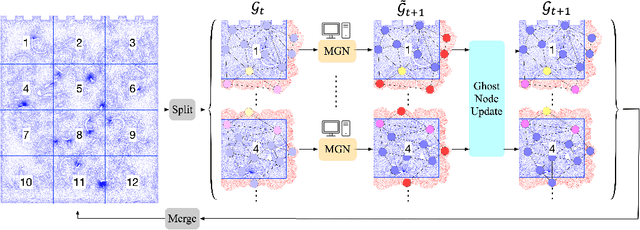

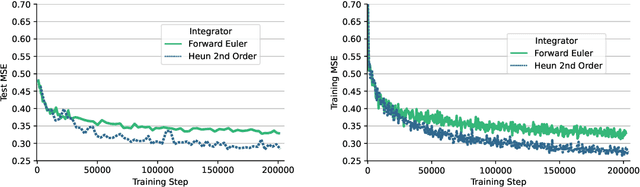
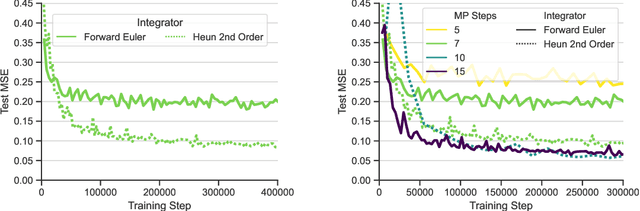
Data-driven modeling approaches can produce fast surrogates to study large-scale physics problems. Among them, graph neural networks (GNNs) that operate on mesh-based data are desirable because they possess inductive biases that promote physical faithfulness, but hardware limitations have precluded their application to large computational domains. We show that it is \textit{possible} to train a class of GNN surrogates on 3D meshes. We scale MeshGraphNets (MGN), a subclass of GNNs for mesh-based physics modeling, via our domain decomposition approach to facilitate training that is mathematically equivalent to training on the whole domain under certain conditions. With this, we were able to train MGN on meshes with \textit{millions} of nodes to generate computational fluid dynamics (CFD) simulations. Furthermore, we show how to enhance MGN via higher-order numerical integration, which can reduce MGN's error and training time. We validated our methods on an accompanying dataset of 3D $\text{CO}_2$-capture CFD simulations on a 3.1M-node mesh. This work presents a practical path to scaling MGN for real-world applications.
Detect, Retrieve, Comprehend: A Flexible Framework for Zero-Shot Document-Level Question Answering
Oct 04, 2022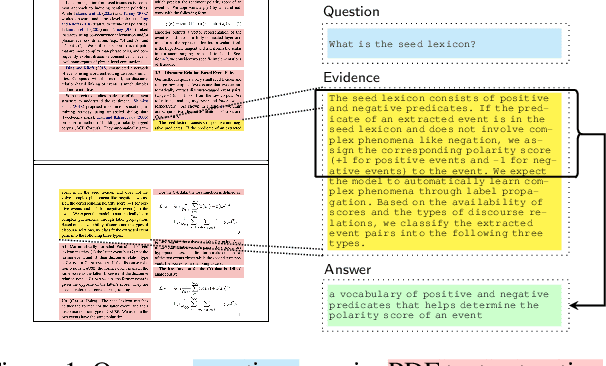
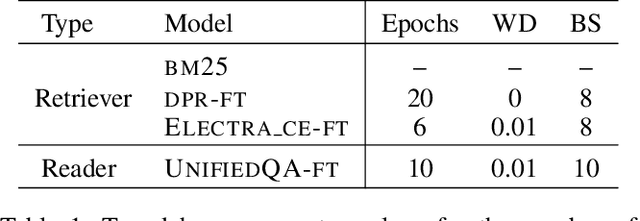
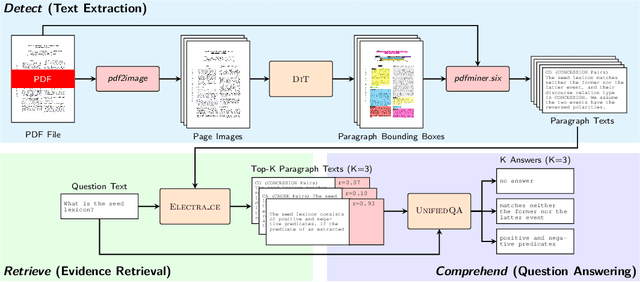

Businesses generate thousands of documents that communicate their strategic vision and provide details of key products, services, entities, and processes. Knowledge workers then face the laborious task of reading these documents to identify, extract, and synthesize information relevant to their organizational goals. To automate information gathering, question answering (QA) offers a flexible framework where human-posed questions can be adapted to extract diverse knowledge. Finetuning QA systems requires access to labeled data (tuples of context, question, and answer). However, data curation for document QA is uniquely challenging because the context (i.e., answer evidence passage) needs to be retrieved from potentially long, ill-formatted documents. Existing QA datasets sidestep this challenge by providing short, well-defined contexts that are unrealistic in real-world applications. We present a three-stage document QA approach: (1) text extraction from PDF; (2) evidence retrieval from extracted texts to form well-posed contexts; (3) QA to extract knowledge from contexts to return high-quality answers - extractive, abstractive, or Boolean. Using QASPER as a surrogate to our proprietary data, our detect-retrieve-comprehend (DRC) system achieves a +6.25 improvement in Answer-F1 over existing baselines while delivering superior context selection. Our results demonstrate that DRC holds tremendous promise as a flexible framework for practical document QA.