 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiltered Approximate Nearest Neighbor Search in Vector Databases: System Design and Performance Analysis
Feb 11, 2026Retrieval-Augmented Generation (RAG) applications increasingly rely on Filtered Approximate Nearest Neighbor Search (FANNS) to combine semantic retrieval with metadata constraints. While algorithmic innovations for FANNS have been proposed, there remains a lack of understanding regarding how generic filtering strategies perform within Vector Databases. In this work, we systematize the taxonomy of filtering strategies and evaluate their integration into FAISS, Milvus, and pgvector. To provide a robust benchmarking framework, we introduce a new relational dataset, \textit{MoReVec}, consisting of two tables, featuring 768-dimensional text embeddings and a rich schema of metadata attributes. We further propose the \textit{Global-Local Selectivity (GLS)} correlation metric to quantify the relationship between filters and query vectors. Our experiments reveal that algorithmic adaptations within the engine often override raw index performance. Specifically, we find that: (1) \textit{Milvus} achieves superior recall stability through hybrid approximate/exact execution; (2) \textit{pgvector}'s cost-based query optimizer frequently selects suboptimal execution plans, favoring approximate index scans even when exact sequential scans would yield perfect recall at comparable latency; and (3) partition-based indexes (IVFFlat) outperform graph-based indexes (HNSW) for low-selectivity queries. To facilitate this analysis, we extend the widely-used \textit{ANN-Benchmarks} to support filtered vector search and make it available online. Finally, we synthesize our findings into a set of practical guidelines for selecting index types and configuring query optimizers for hybrid search workloads.
Detect, Retrieve, Comprehend: A Flexible Framework for Zero-Shot Document-Level Question Answering
Oct 04, 2022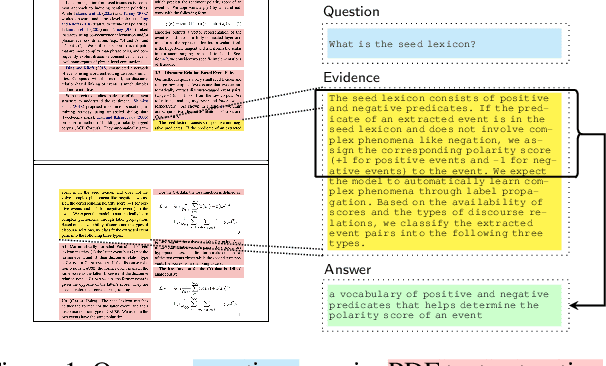
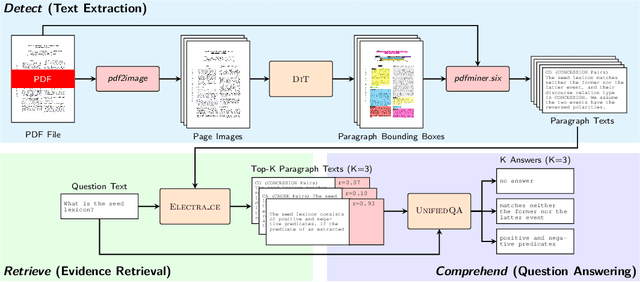

Businesses generate thousands of documents that communicate their strategic vision and provide details of key products, services, entities, and processes. Knowledge workers then face the laborious task of reading these documents to identify, extract, and synthesize information relevant to their organizational goals. To automate information gathering, question answering (QA) offers a flexible framework where human-posed questions can be adapted to extract diverse knowledge. Finetuning QA systems requires access to labeled data (tuples of context, question, and answer). However, data curation for document QA is uniquely challenging because the context (i.e., answer evidence passage) needs to be retrieved from potentially long, ill-formatted documents. Existing QA datasets sidestep this challenge by providing short, well-defined contexts that are unrealistic in real-world applications. We present a three-stage document QA approach: (1) text extraction from PDF; (2) evidence retrieval from extracted texts to form well-posed contexts; (3) QA to extract knowledge from contexts to return high-quality answers - extractive, abstractive, or Boolean. Using QASPER as a surrogate to our proprietary data, our detect-retrieve-comprehend (DRC) system achieves a +6.25 improvement in Answer-F1 over existing baselines while delivering superior context selection. Our results demonstrate that DRC holds tremendous promise as a flexible framework for practical document QA.
DJEnsemble: On the Selection of a Disjoint Ensemble of Deep Learning Black-Box Spatio-temporal Models
May 25, 2020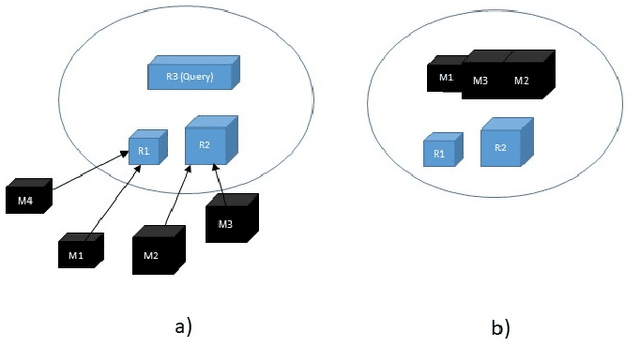
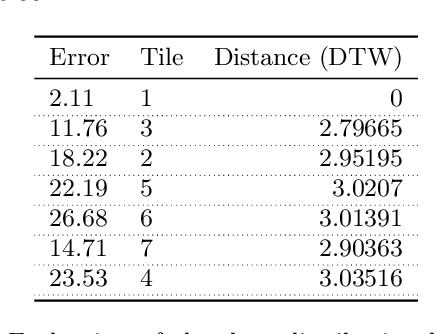
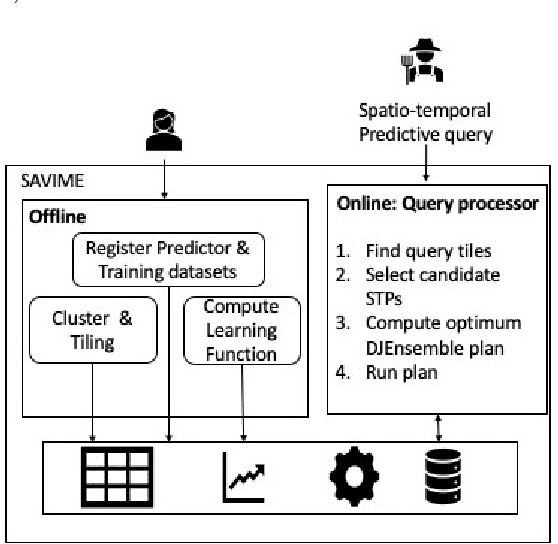
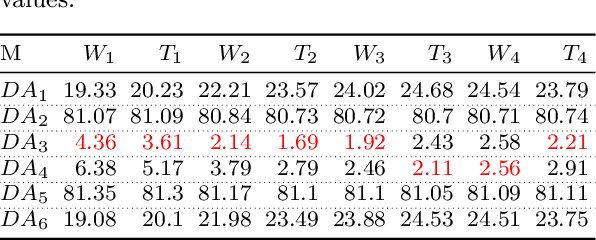
In this paper, we present a cost-based approach for the automatic selection and allocation of a disjoint ensemble of black-box predictors to answer predictive spatio-temporal queries. Our approach is divided into two parts -- offline and online. During the offline part, we preprocess the predictive domain data -- transforming it into a regular grid -- and the black-box models -- computing their spatio-temporal learning function. In the online part, we compute a DJEnsemble plan which minimizes a multivariate cost function based on estimates for the prediction error and the execution cost -- producing a model spatial allocation matrix -- and run the optimal ensemble plan. We conduct a set of extensive experiments that evaluate the DJEnsemble approach and highlight its efficiency. We show that our cost model produces plans with performance close to the actual best plan. When compared against the traditional ensemble approach, DJEnsemble achieves up to $4X$ improvement in execution time and almost $9X$ improvement in prediction accuracy. To the best of our knowledge, this is the first work to solve the problem of optimizing the allocation of black-box models to answer predictive spatio-temporal queries.