 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatroids Hitting Sets and Unsupervised Dependency Grammar Induction
Jul 15, 2017



This paper formulates a novel problem on graphs: find the minimal subset of edges in a fully connected graph, such that the resulting graph contains all spanning trees for a set of specifed sub-graphs. This formulation is motivated by an un-supervised grammar induction problem from computational linguistics. We present a reduction to some known problems and algorithms from graph theory, provide computational complexity results, and describe an approximation algorithm.
Learning to Cooperate via Policy Search
Aug 07, 2014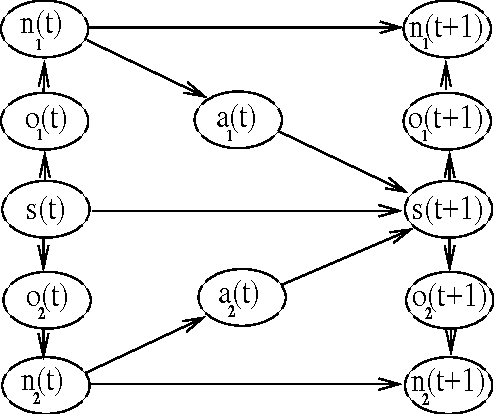
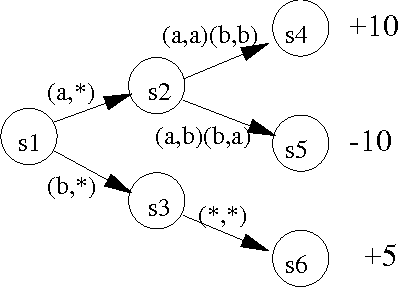
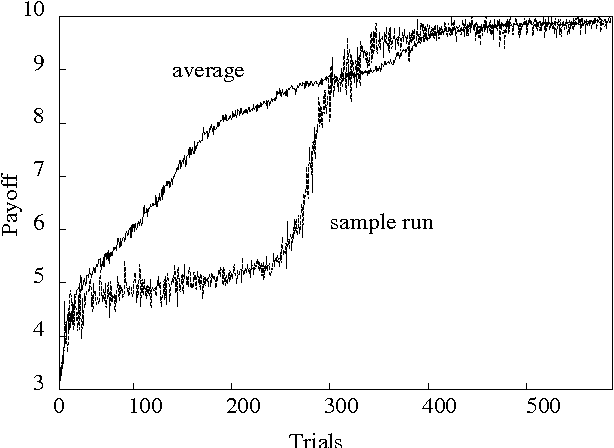
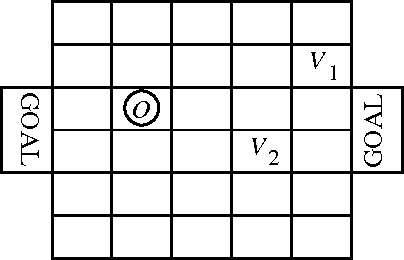
Cooperative games are those in which both agents share the same payoff structure. Value-based reinforcement-learning algorithms, such as variants of Q-learning, have been applied to learning cooperative games, but they only apply when the game state is completely observable to both agents. Policy search methods are a reasonable alternative to value-based methods for partially observable environments. In this paper, we provide a gradient-based distributed policy-search method for cooperative games and compare the notion of local optimum to that of Nash equilibrium. We demonstrate the effectiveness of this method experimentally in a small, partially observable simulated soccer domain.
Learning Finite-State Controllers for Partially Observable Environments
Jan 23, 2013

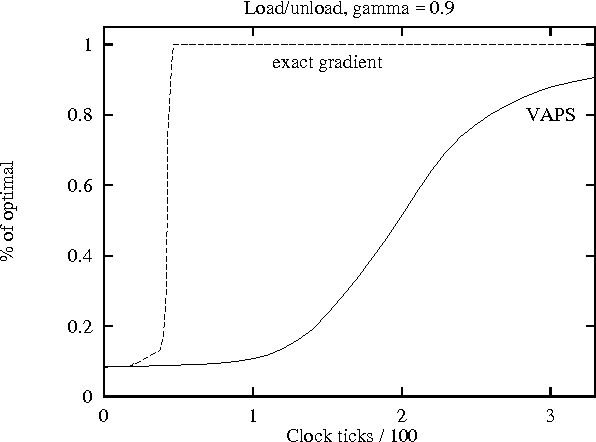
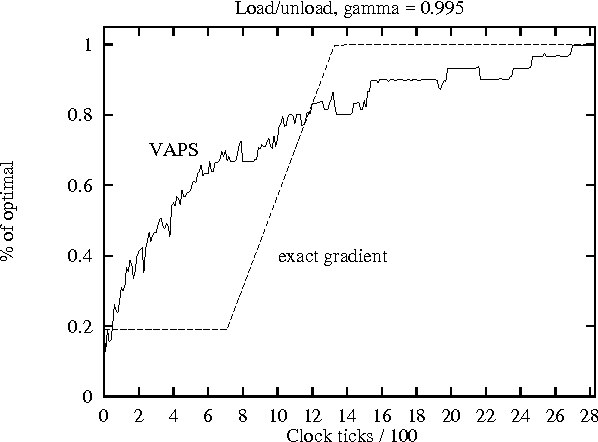
Reactive (memoryless) policies are sufficient in completely observable Markov decision processes (MDPs), but some kind of memory is usually necessary for optimal control of a partially observable MDP. Policies with finite memory can be represented as finite-state automata. In this paper, we extend Baird and Moore's VAPS algorithm to the problem of learning general finite-state automata. Because it performs stochastic gradient descent, this algorithm can be shown to converge to a locally optimal finite-state controller. We provide the details of the algorithm and then consider the question of under what conditions stochastic gradient descent will outperform exact gradient descent. We conclude with empirical results comparing the performance of stochastic and exact gradient descent, and showing the ability of our algorithm to extract the useful information contained in the sequence of past observations to compensate for the lack of observability at each time-step.
Factored Particles for Scalable Monitoring
Dec 12, 2012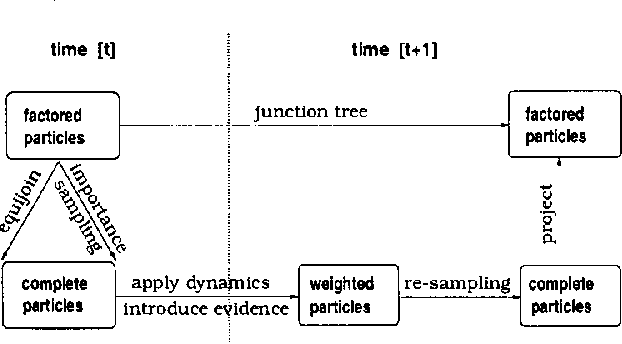
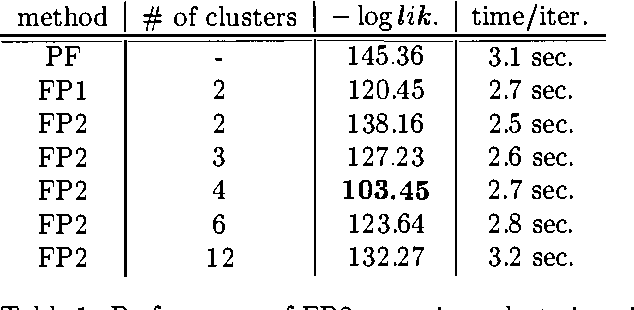

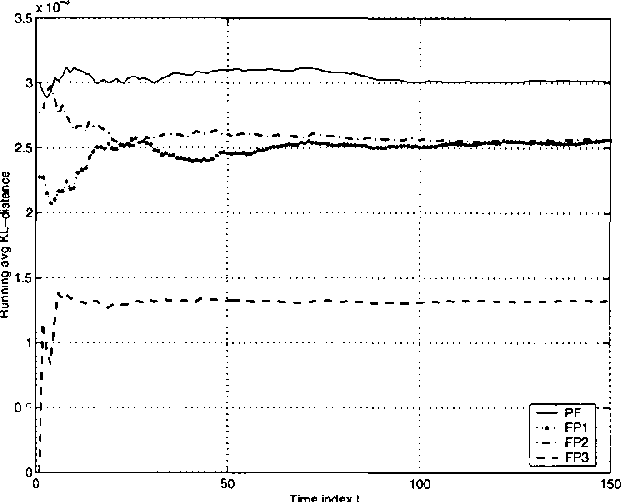
Exact monitoring in dynamic Bayesian networks is intractable, so approximate algorithms are necessary. This paper presents a new family of approximate monitoring algorithms that combine the best qualities of the particle filtering and Boyen-Koller methods. Our algorithms maintain an approximate representation the belief state in the form of sets of factored particles, that correspond to samples of clusters of state variables. Empirical results show that our algorithms outperform both ordinary particle filtering and the Boyen-Koller algorithm on large systems.
Reinforcement Learning for Adaptive Routing
Mar 28, 2007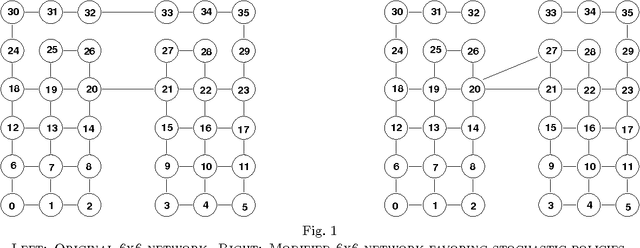

Reinforcement learning means learning a policy--a mapping of observations into actions--based on feedback from the environment. The learning can be viewed as browsing a set of policies while evaluating them by trial through interaction with the environment. We present an application of gradient ascent algorithm for reinforcement learning to a complex domain of packet routing in network communication and compare the performance of this algorithm to other routing methods on a benchmark problem.
Dependency Parsing with Dynamic Bayesian Network
Mar 27, 2007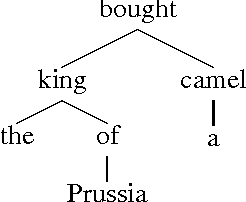
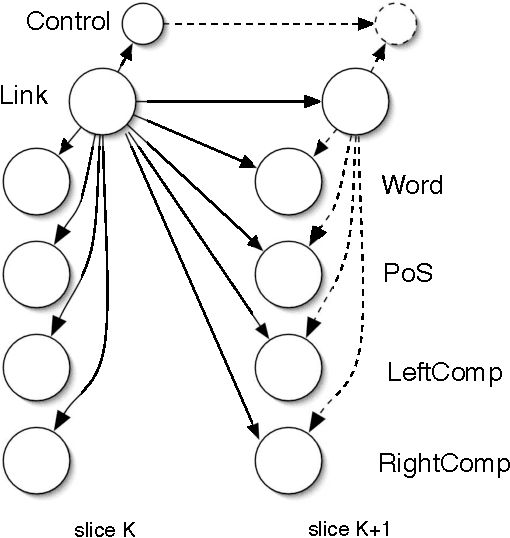


Exact parsing with finite state automata is deemed inappropriate because of the unbounded non-locality languages overwhelmingly exhibit. We propose a way to structure the parsing task in order to make it amenable to local classification methods. This allows us to build a Dynamic Bayesian Network which uncovers the syntactic dependency structure of English sentences. Experiments with the Wall Street Journal demonstrate that the model successfully learns from labeled data.
* 6 pages
Structure induction by lossless graph compression
Mar 27, 2007

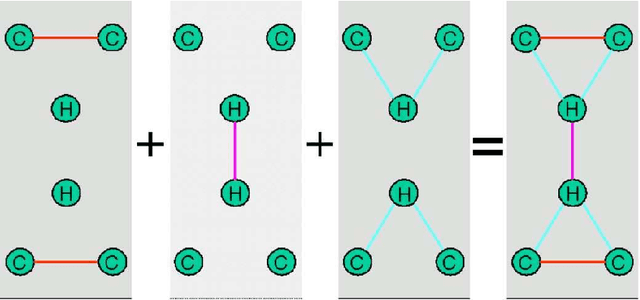
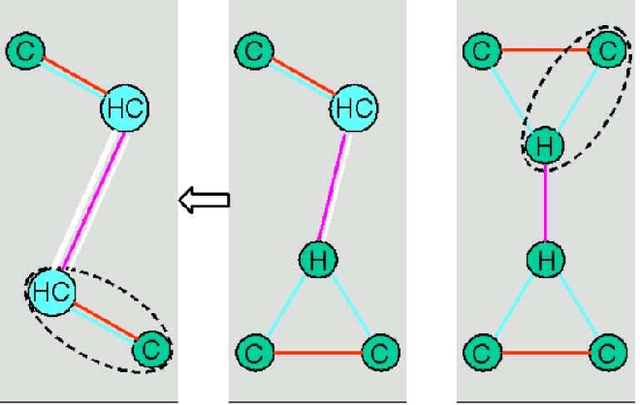
This work is motivated by the necessity to automate the discovery of structure in vast and evergrowing collection of relational data commonly represented as graphs, for example genomic networks. A novel algorithm, dubbed Graphitour, for structure induction by lossless graph compression is presented and illustrated by a clear and broadly known case of nested structure in a DNA molecule. This work extends to graphs some well established approaches to grammatical inference previously applied only to strings. The bottom-up graph compression problem is related to the maximum cardinality (non-bipartite) maximum cardinality matching problem. The algorithm accepts a variety of graph types including directed graphs and graphs with labeled nodes and arcs. The resulting structure could be used for representation and classification of graphs.
* 10 pages, 7 figures, 2 tables published in Proceedings of the Data Compression Conference, 2007
Part-of-Speech Tagging with Minimal Lexicalization
Dec 27, 2003



We use a Dynamic Bayesian Network to represent compactly a variety of sublexical and contextual features relevant to Part-of-Speech (PoS) tagging. The outcome is a flexible tagger (LegoTag) with state-of-the-art performance (3.6% error on a benchmark corpus). We explore the effect of eliminating redundancy and radically reducing the size of feature vocabularies. We find that a small but linguistically motivated set of suffixes results in improved cross-corpora generalization. We also show that a minimal lexicon limited to function words is sufficient to ensure reasonable performance.
Bayesian Information Extraction Network
Jun 10, 2003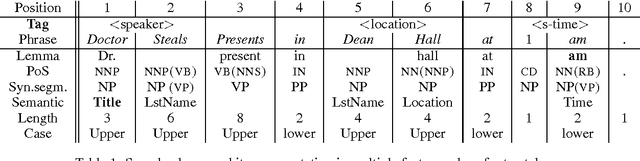
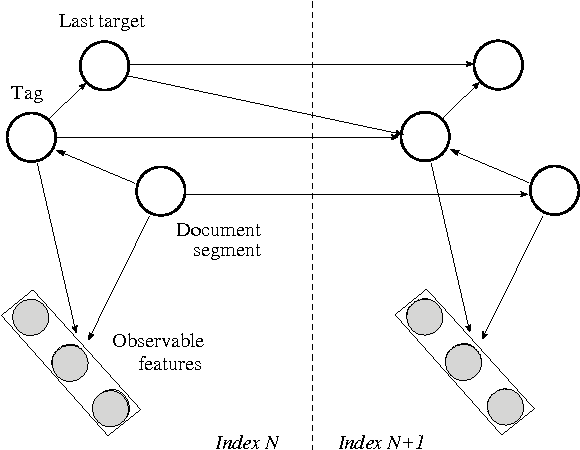
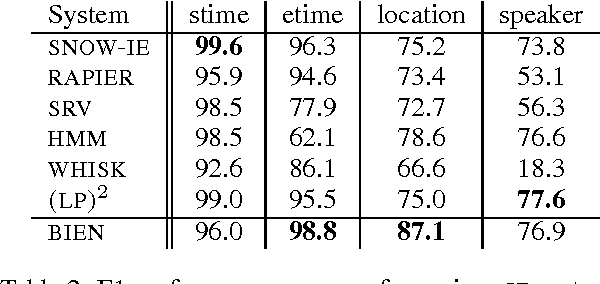

Dynamic Bayesian networks (DBNs) offer an elegant way to integrate various aspects of language in one model. Many existing algorithms developed for learning and inference in DBNs are applicable to probabilistic language modeling. To demonstrate the potential of DBNs for natural language processing, we employ a DBN in an information extraction task. We show how to assemble wealth of emerging linguistic instruments for shallow parsing, syntactic and semantic tagging, morphological decomposition, named entity recognition etc. in order to incrementally build a robust information extraction system. Our method outperforms previously published results on an established benchmark domain.
* 6 pages
Learning from Scarce Experience
Apr 20, 2002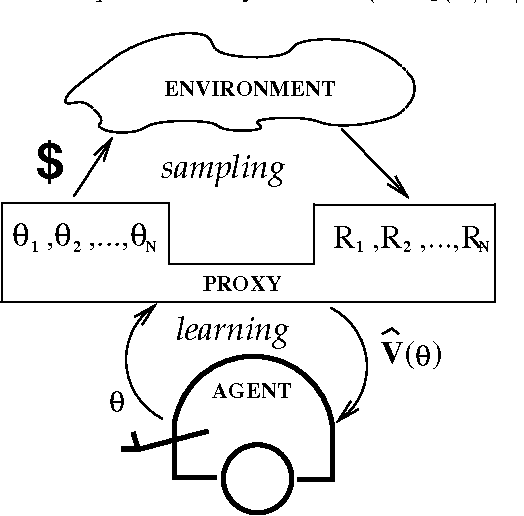


Searching the space of policies directly for the optimal policy has been one popular method for solving partially observable reinforcement learning problems. Typically, with each change of the target policy, its value is estimated from the results of following that very policy. This requires a large number of interactions with the environment as different polices are considered. We present a family of algorithms based on likelihood ratio estimation that use data gathered when executing one policy (or collection of policies) to estimate the value of a different policy. The algorithms combine estimation and optimization stages. The former utilizes experience to build a non-parametric representation of an optimized function. The latter performs optimization on this estimate. We show positive empirical results and provide the sample complexity bound.