 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Scarce Experience
Paper and Code
Apr 20, 2002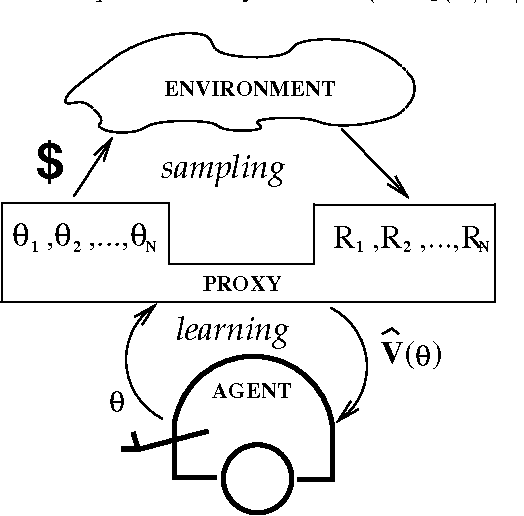


Searching the space of policies directly for the optimal policy has been one popular method for solving partially observable reinforcement learning problems. Typically, with each change of the target policy, its value is estimated from the results of following that very policy. This requires a large number of interactions with the environment as different polices are considered. We present a family of algorithms based on likelihood ratio estimation that use data gathered when executing one policy (or collection of policies) to estimate the value of a different policy. The algorithms combine estimation and optimization stages. The former utilizes experience to build a non-parametric representation of an optimized function. The latter performs optimization on this estimate. We show positive empirical results and provide the sample complexity bound.