Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Cooperate via Policy Search
Paper and Code
Aug 07, 2014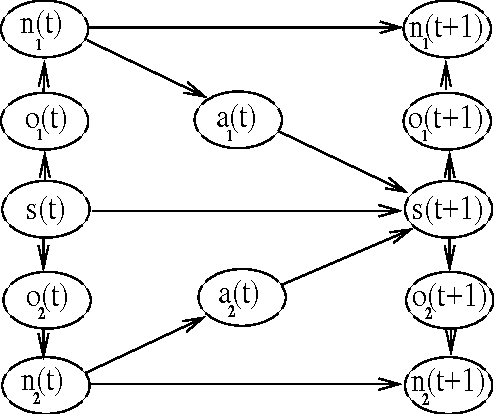
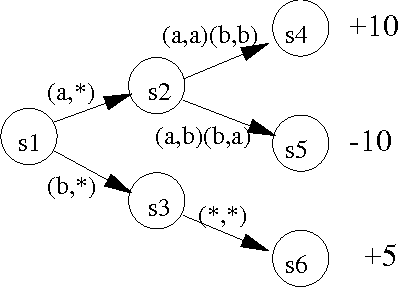
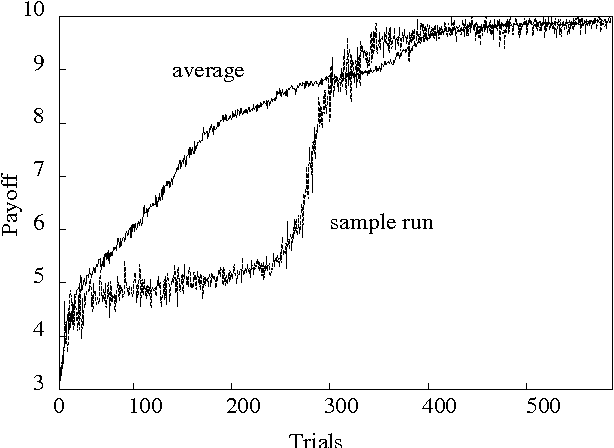
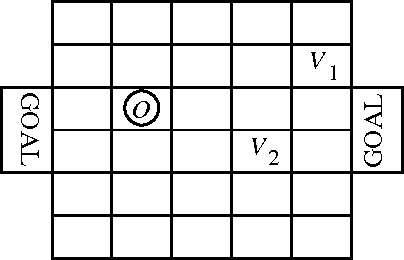
Cooperative games are those in which both agents share the same payoff structure. Value-based reinforcement-learning algorithms, such as variants of Q-learning, have been applied to learning cooperative games, but they only apply when the game state is completely observable to both agents. Policy search methods are a reasonable alternative to value-based methods for partially observable environments. In this paper, we provide a gradient-based distributed policy-search method for cooperative games and compare the notion of local optimum to that of Nash equilibrium. We demonstrate the effectiveness of this method experimentally in a small, partially observable simulated soccer domain.
* Appears in Proceedings of the Sixteenth Conference on Uncertainty in
Artificial Intelligence (UAI2000)
View paper on