 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Finite-State Controllers for Partially Observable Environments
Paper and Code
Jan 23, 2013

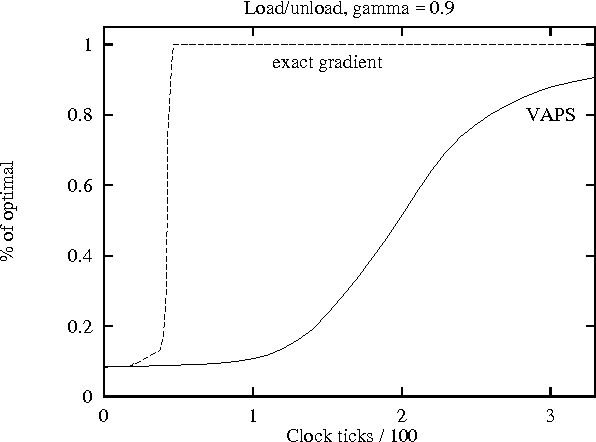
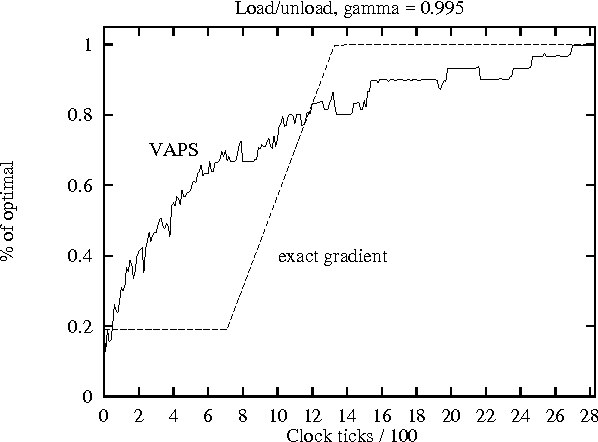
Reactive (memoryless) policies are sufficient in completely observable Markov decision processes (MDPs), but some kind of memory is usually necessary for optimal control of a partially observable MDP. Policies with finite memory can be represented as finite-state automata. In this paper, we extend Baird and Moore's VAPS algorithm to the problem of learning general finite-state automata. Because it performs stochastic gradient descent, this algorithm can be shown to converge to a locally optimal finite-state controller. We provide the details of the algorithm and then consider the question of under what conditions stochastic gradient descent will outperform exact gradient descent. We conclude with empirical results comparing the performance of stochastic and exact gradient descent, and showing the ability of our algorithm to extract the useful information contained in the sequence of past observations to compensate for the lack of observability at each time-step.