 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoTool: Efficient Tool Selection for Large Language Model Agents
Nov 18, 2025Large Language Model (LLM) agents have emerged as powerful tools for automating complex tasks by leveraging the reasoning and decision-making abilities of LLMs. However, a major bottleneck in current agent frameworks lies in the high inference cost of tool selection, especially in approaches like ReAct that repeatedly invoke the LLM to determine which tool to use at each step. In this work, we propose AutoTool, a novel graph-based framework that bypasses repeated LLM inference by exploiting a key empirical observation: tool usage inertia - the tendency of tool invocations to follow predictable sequential patterns. AutoTool constructs a directed graph from historical agent trajectories, where nodes represent tools and edges capture transition probabilities, effectively modeling the inertia in tool selection. It further integrates parameter-level information to refine tool input generation. By traversing this structured representation, AutoTool efficiently selects tools and their parameters with minimal reliance on LLM inference. Extensive experiments across diverse agent tasks demonstrate that AutoTool reduces inference costs by up to 30% while maintaining competitive task completion rates, offering a practical and scalable enhancement for inference-heavy frameworks. Our work highlights the promise of integrating statistical structure into LLM agent design for greater efficiency without sacrificing performance.
VP-Bench: A Comprehensive Benchmark for Visual Prompting in Multimodal Large Language Models
Nov 14, 2025Multimodal large language models (MLLMs) have enabled a wide range of advanced vision-language applications, including fine-grained object recognition and contextual understanding. When querying specific regions or objects in an image, human users naturally use "visual prompts" (VPs), such as bounding boxes, to provide reference. However, no existing benchmark systematically evaluates the ability of MLLMs to interpret such VPs. This gap leaves it unclear whether current MLLMs can effectively recognize VPs, an intuitive prompting method for humans, and use them to solve problems. To address this limitation, we introduce VP-Bench, a benchmark for assessing MLLMs' capability in VP perception and utilization. VP-Bench employs a two-stage evaluation framework: Stage 1 examines models' ability to perceive VPs in natural scenes, using 30k visualized prompts spanning eight shapes and 355 attribute combinations. Stage 2 investigates the impact of VPs on downstream tasks, measuring their effectiveness in real-world problem-solving scenarios. Using VP-Bench, we evaluate 28 MLLMs, including proprietary systems (e.g., GPT-4o) and open-source models (e.g., InternVL3 and Qwen2.5-VL), and provide a comprehensive analysis of factors that affect VP understanding, such as variations in VP attributes, question arrangement, and model scale. VP-Bench establishes a new reference framework for studying how MLLMs comprehend and resolve grounded referring questions.
Vertical Federated Learning in Practice: The Good, the Bad, and the Ugly
Feb 12, 2025Vertical Federated Learning (VFL) is a privacy-preserving collaborative learning paradigm that enables multiple parties with distinct feature sets to jointly train machine learning models without sharing their raw data. Despite its potential to facilitate cross-organizational collaborations, the deployment of VFL systems in real-world applications remains limited. To investigate the gap between existing VFL research and practical deployment, this survey analyzes the real-world data distributions in potential VFL applications and identifies four key findings that highlight this gap. We propose a novel data-oriented taxonomy of VFL algorithms based on real VFL data distributions. Our comprehensive review of existing VFL algorithms reveals that some common practical VFL scenarios have few or no viable solutions. Based on these observations, we outline key research directions aimed at bridging the gap between current VFL research and real-world applications.
ICM-Assistant: Instruction-tuning Multimodal Large Language Models for Rule-based Explainable Image Content Moderation
Dec 24, 2024



Controversial contents largely inundate the Internet, infringing various cultural norms and child protection standards. Traditional Image Content Moderation (ICM) models fall short in producing precise moderation decisions for diverse standards, while recent multimodal large language models (MLLMs), when adopted to general rule-based ICM, often produce classification and explanation results that are inconsistent with human moderators. Aiming at flexible, explainable, and accurate ICM, we design a novel rule-based dataset generation pipeline, decomposing concise human-defined rules and leveraging well-designed multi-stage prompts to enrich short explicit image annotations. Our ICM-Instruct dataset includes detailed moderation explanation and moderation Q-A pairs. Built upon it, we create our ICM-Assistant model in the framework of rule-based ICM, making it readily applicable in real practice. Our ICM-Assistant model demonstrates exceptional performance and flexibility. Specifically, it significantly outperforms existing approaches on various sources, improving both the moderation classification (36.8\% on average) and moderation explanation quality (26.6\% on average) consistently over existing MLLMs. Code/Data is available at https://github.com/zhaoyuzhi/ICM-Assistant.
Boosting Alignment for Post-Unlearning Text-to-Image Generative Models
Dec 09, 2024

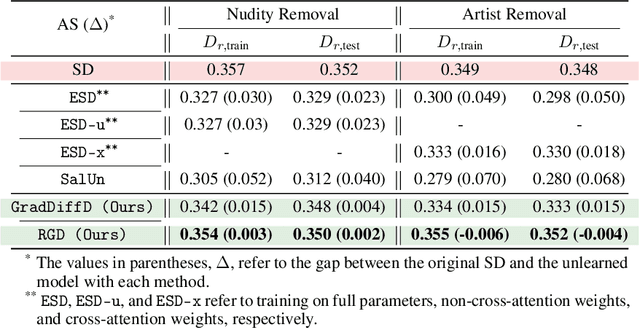

Large-scale generative models have shown impressive image-generation capabilities, propelled by massive data. However, this often inadvertently leads to the generation of harmful or inappropriate content and raises copyright concerns. Driven by these concerns, machine unlearning has become crucial to effectively purge undesirable knowledge from models. While existing literature has studied various unlearning techniques, these often suffer from either poor unlearning quality or degradation in text-image alignment after unlearning, due to the competitive nature of these objectives. To address these challenges, we propose a framework that seeks an optimal model update at each unlearning iteration, ensuring monotonic improvement on both objectives. We further derive the characterization of such an update. In addition, we design procedures to strategically diversify the unlearning and remaining datasets to boost performance improvement. Our evaluation demonstrates that our method effectively removes target classes from recent diffusion-based generative models and concepts from stable diffusion models while maintaining close alignment with the models' original trained states, thus outperforming state-of-the-art baselines. Our code will be made available at \url{https://github.com/reds-lab/Restricted_gradient_diversity_unlearning.git}.
LLM-PBE: Assessing Data Privacy in Large Language Models
Aug 23, 2024



Large Language Models (LLMs) have become integral to numerous domains, significantly advancing applications in data management, mining, and analysis. Their profound capabilities in processing and interpreting complex language data, however, bring to light pressing concerns regarding data privacy, especially the risk of unintentional training data leakage. Despite the critical nature of this issue, there has been no existing literature to offer a comprehensive assessment of data privacy risks in LLMs. Addressing this gap, our paper introduces LLM-PBE, a toolkit crafted specifically for the systematic evaluation of data privacy risks in LLMs. LLM-PBE is designed to analyze privacy across the entire lifecycle of LLMs, incorporating diverse attack and defense strategies, and handling various data types and metrics. Through detailed experimentation with multiple LLMs, LLM-PBE facilitates an in-depth exploration of data privacy concerns, shedding light on influential factors such as model size, data characteristics, and evolving temporal dimensions. This study not only enriches the understanding of privacy issues in LLMs but also serves as a vital resource for future research in the field. Aimed at enhancing the breadth of knowledge in this area, the findings, resources, and our full technical report are made available at https://llm-pbe.github.io/, providing an open platform for academic and practical advancements in LLM privacy assessment.
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
Jun 13, 2024



The rapid advancement of large language models (LLMs) has catalyzed the deployment of LLM-powered agents across numerous applications, raising new concerns regarding their safety and trustworthiness. Existing methods for enhancing the safety of LLMs are not directly transferable to LLM-powered agents due to their diverse objectives and output modalities. In this paper, we propose GuardAgent, the first LLM agent as a guardrail to other LLM agents. Specifically, GuardAgent oversees a target LLM agent by checking whether its inputs/outputs satisfy a set of given guard requests defined by the users. GuardAgent comprises two steps: 1) creating a task plan by analyzing the provided guard requests, and 2) generating guardrail code based on the task plan and executing the code by calling APIs or using external engines. In both steps, an LLM is utilized as the core reasoning component, supplemented by in-context demonstrations retrieved from a memory module. Such knowledge-enabled reasoning allows GuardAgent to understand various textual guard requests and accurately "translate" them into executable code that provides reliable guardrails. Furthermore, GuardAgent is equipped with an extendable toolbox containing functions and APIs and requires no additional LLM training, which underscores its generalization capabilities and low operational overhead. Additionally, we propose two novel benchmarks: an EICU-AC benchmark for assessing privacy-related access control for healthcare agents and a Mind2Web-SC benchmark for safety evaluation for web agents. We show the effectiveness of GuardAgent on these two benchmarks with 98.7% and 90.0% accuracy in moderating invalid inputs and outputs for the two types of agents, respectively. We also show that GuardAgent is able to define novel functions in adaption to emergent LLM agents and guard requests, which underscores its strong generalization capabilities.
Federated Learning with New Knowledge: Fundamentals, Advances, and Futures
Feb 03, 2024Federated Learning (FL) is a privacy-preserving distributed learning approach that is rapidly developing in an era where privacy protection is increasingly valued. It is this rapid development trend, along with the continuous emergence of new demands for FL in the real world, that prompts us to focus on a very important problem: Federated Learning with New Knowledge. The primary challenge here is to effectively incorporate various new knowledge into existing FL systems and evolve these systems to reduce costs, extend their lifespan, and facilitate sustainable development. In this paper, we systematically define the main sources of new knowledge in FL, including new features, tasks, models, and algorithms. For each source, we thoroughly analyze and discuss how to incorporate new knowledge into existing FL systems and examine the impact of the form and timing of new knowledge arrival on the incorporation process. Furthermore, we comprehensively discuss the potential future directions for FL with new knowledge, considering a variety of factors such as scenario setups, efficiency, and security. There is also a continuously updating repository for this topic: https://github.com/conditionWang/FLNK.
Exploiting Label Skews in Federated Learning with Model Concatenation
Dec 16, 2023



Federated Learning (FL) has emerged as a promising solution to perform deep learning on different data owners without exchanging raw data. However, non-IID data has been a key challenge in FL, which could significantly degrade the accuracy of the final model. Among different non-IID types, label skews have been challenging and common in image classification and other tasks. Instead of averaging the local models in most previous studies, we propose FedConcat, a simple and effective approach that concatenates these local models as the base of the global model to effectively aggregate the local knowledge. To reduce the size of the global model, we adopt the clustering technique to group the clients by their label distributions and collaboratively train a model inside each cluster. We theoretically analyze the advantage of concatenation over averaging by analyzing the information bottleneck of deep neural networks. Experimental results demonstrate that FedConcat achieves significantly higher accuracy than previous state-of-the-art FL methods in various heterogeneous label skew distribution settings and meanwhile has lower communication costs. Our code is publicly available at https://github.com/sjtudyq/FedConcat.
Effective and Efficient Federated Tree Learning on Hybrid Data
Oct 18, 2023



Federated learning has emerged as a promising distributed learning paradigm that facilitates collaborative learning among multiple parties without transferring raw data. However, most existing federated learning studies focus on either horizontal or vertical data settings, where the data of different parties are assumed to be from the same feature or sample space. In practice, a common scenario is the hybrid data setting, where data from different parties may differ both in the features and samples. To address this, we propose HybridTree, a novel federated learning approach that enables federated tree learning on hybrid data. We observe the existence of consistent split rules in trees. With the help of these split rules, we theoretically show that the knowledge of parties can be incorporated into the lower layers of a tree. Based on our theoretical analysis, we propose a layer-level solution that does not need frequent communication traffic to train a tree. Our experiments demonstrate that HybridTree can achieve comparable accuracy to the centralized setting with low computational and communication overhead. HybridTree can achieve up to 8 times speedup compared with the other baselines.