 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFontCrafter: High-Fidelity Element-Driven Artistic Font Creation with Visual In-Context Generation
Mar 23, 2026Artistic font generation aims to synthesize stylized glyphs based on a reference style. However, existing approaches suffer from limited style diversity and coarse control. In this work, we explore the potential of element-driven artistic font generation. Elements are the fundamental visual units of a font, serving as reference images for the desired style. Conceptually, we categorize elements into object elements (e.g., flowers or stones) with distinct structures and amorphous elements (e.g., flames or clouds) with unstructured textures. We introduce FontCrafter, an element-driven framework for font creation, and construct a large-scale dataset, ElementFont, which contains diverse element types and high-quality glyph images. However, achieving high-fidelity reconstruction of both texture and structure of reference elements remains challenging. To address this, we propose an in-context generation strategy that treats element images as visual context and uses an inpainting model to transfer element styles into glyph regions at the pixel level. To further control glyph shapes, we design a lightweight Context-aware Mask Adapter (CMA) that injects shape information. Moreover, a training-free attention redirection mechanism enables region-aware style control and suppresses stroke hallucination. In addition, edge repainting is applied to make boundaries more natural. Extensive experiments demonstrate that FontCrafter achieves strong zero-shot generation performance, particularly in preserving structural and textural fidelity, while also supporting flexible controls such as style mixture.
SoK: Privacy-Preserving Data Synthesis
Jul 05, 2023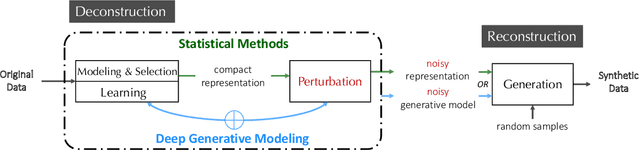
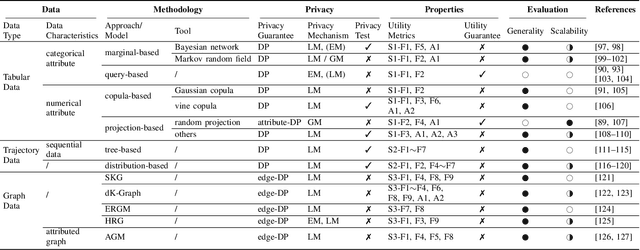
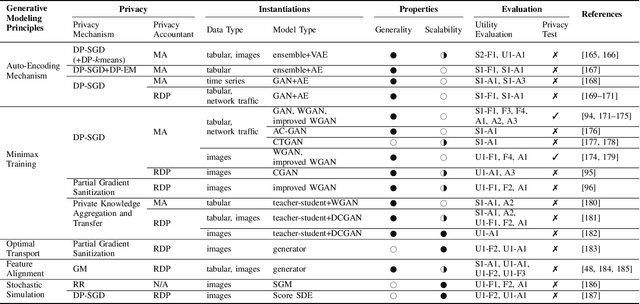
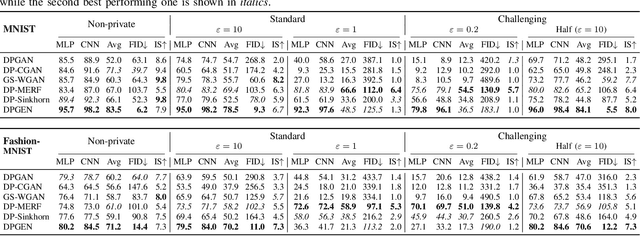
As the prevalence of data analysis grows, safeguarding data privacy has become a paramount concern. Consequently, there has been an upsurge in the development of mechanisms aimed at privacy-preserving data analyses. However, these approaches are task-specific; designing algorithms for new tasks is a cumbersome process. As an alternative, one can create synthetic data that is (ideally) devoid of private information. This paper focuses on privacy-preserving data synthesis (PPDS) by providing a comprehensive overview, analysis, and discussion of the field. Specifically, we put forth a master recipe that unifies two prominent strands of research in PPDS: statistical methods and deep learning (DL)-based methods. Under the master recipe, we further dissect the statistical methods into choices of modeling and representation, and investigate the DL-based methods by different generative modeling principles. To consolidate our findings, we provide comprehensive reference tables, distill key takeaways, and identify open problems in the existing literature. In doing so, we aim to answer the following questions: What are the design principles behind different PPDS methods? How can we categorize these methods, and what are the advantages and disadvantages associated with each category? Can we provide guidelines for method selection in different real-world scenarios? We proceed to benchmark several prominent DL-based methods on the task of private image synthesis and conclude that DP-MERF is an all-purpose approach. Finally, upon systematizing the work over the past decade, we identify future directions and call for actions from researchers.
Data Programming by Demonstration: A Framework for Interactively Learning Labeling Functions
Sep 15, 2020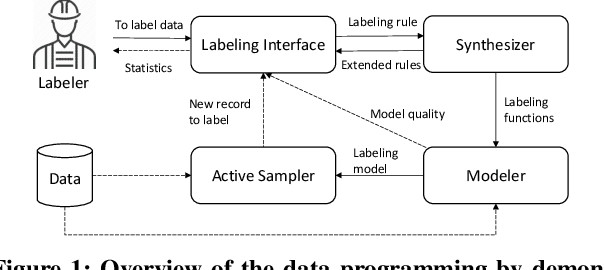
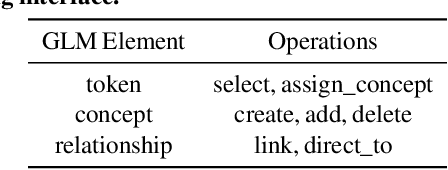
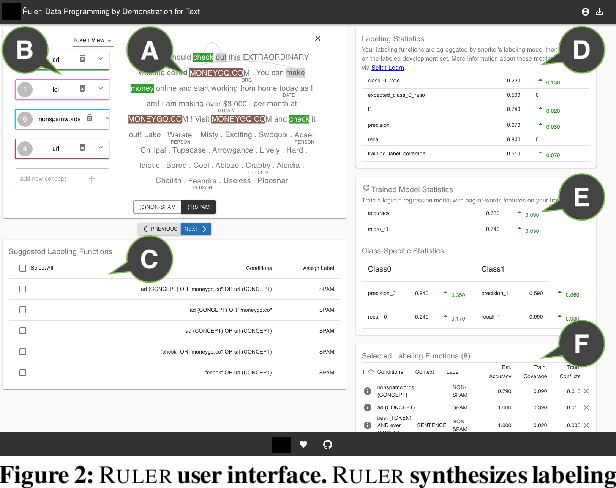

Data programming is a programmatic weak supervision approach to efficiently curate large-scale labeled training data. Writing data programs (labeling functions) requires, however, both programming literacy and domain expertise. Many subject matter experts have neither programming proficiency nor time to effectively write data programs. Furthermore, regardless of one's expertise in coding or machine learning, transferring domain expertise into labeling functions by enumerating rules and thresholds is not only time consuming but also inherently difficult. Here we propose a new framework, data programming by demonstration (DPBD), to generate labeling rules using interactive demonstrations of users. DPBD aims to relieve the burden of writing labeling functions from users, enabling them to focus on higher-level semantics such as identifying relevant signals for labeling tasks. We operationalize our framework with Ruler, an interactive system that synthesizes labeling rules for document classification by using span-level annotations of users on document examples. We compare Ruler with conventional data programming through a user study conducted with 10 data scientists creating labeling functions for sentiment and spam classification tasks. We find that Ruler is easier to use and learn and offers higher overall satisfaction, while providing discriminative model performances comparable to ones achieved by conventional data programming.
Deep Neural Network Hyperparameter Optimization with Orthogonal Array Tuning
Jul 31, 2019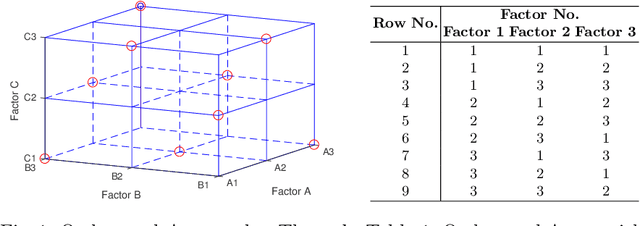
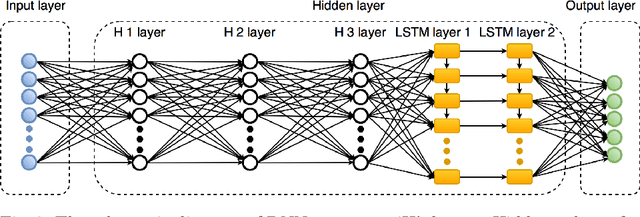

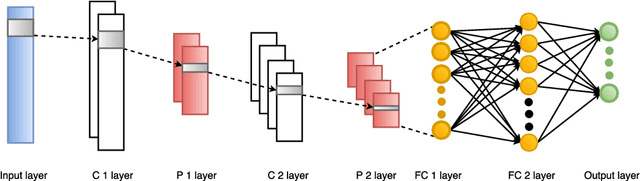
Deep learning algorithms have achieved excellent performance lately in a wide range of fields (e.g., computer version). However, a severe challenge faced by deep learning is the high dependency on hyper-parameters. The algorithm results may fluctuate dramatically under the different configuration of hyper-parameters. Addressing the above issue, this paper presents an efficient Orthogonal Array Tuning Method (OATM) for deep learning hyper-parameter tuning. We describe the OATM approach in five detailed steps and elaborate on it using two widely used deep neural network structures (Recurrent Neural Networks and Convolutional Neural Networks). The proposed method is compared to the state-of-the-art hyper-parameter tuning methods including manually (e.g., grid search and random search) and automatically (e.g., Bayesian Optimization) ones. The experiment results state that OATM can significantly save the tuning time compared to the state-of-the-art methods while preserving the satisfying performance.
Multi-task Generative Adversarial Learning on Geometrical Shape Reconstruction from EEG Brain Signals
Jul 31, 2019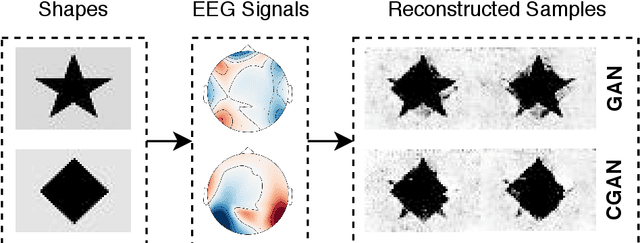

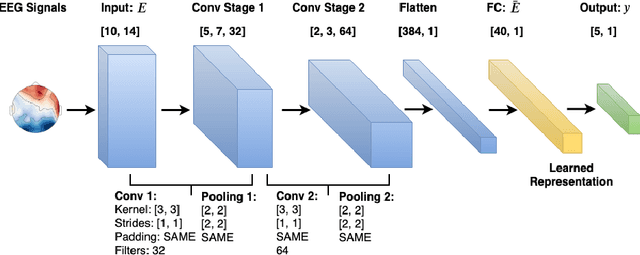
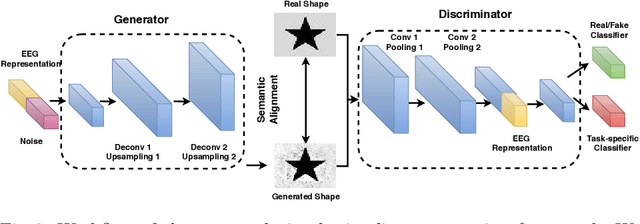
Synthesizing geometrical shapes from human brain activities is an interesting and meaningful but very challenging topic. Recently, the advancements of deep generative models like Generative Adversarial Networks (GANs) have supported the object generation from neurological signals. However, the Electroencephalograph (EEG)-based shape generation still suffer from the low realism problem. In particular, the generated geometrical shapes lack clear edges and fail to contain necessary details. In light of this, we propose a novel multi-task generative adversarial network to convert the individual's EEG signals evoked by geometrical shapes to the original geometry. First, we adopt a Convolutional Neural Network (CNN) to learn highly informative latent representation for the raw EEG signals, which is vital for the subsequent shape reconstruction. Next, we build the discriminator based on multi-task learning to distinguish and classify fake samples simultaneously, where the mutual promotion between different tasks improves the quality of the recovered shapes. Then, we propose a semantic alignment constraint in order to force the synthesized samples to approach the real ones in pixel-level, thus producing more compelling shapes. The proposed approach is evaluated over a local dataset and the results show that our model outperforms the competitive state-of-the-art baselines.