 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagRuler: Interactive Tool for Span-Level Data Programming by Demonstration
Jun 24, 2021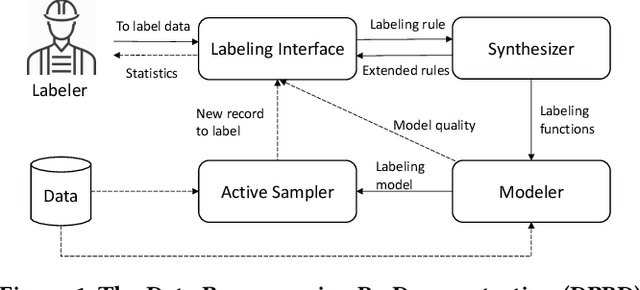
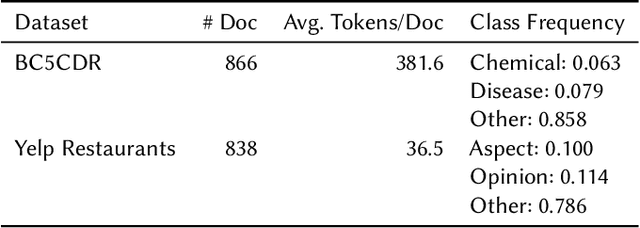
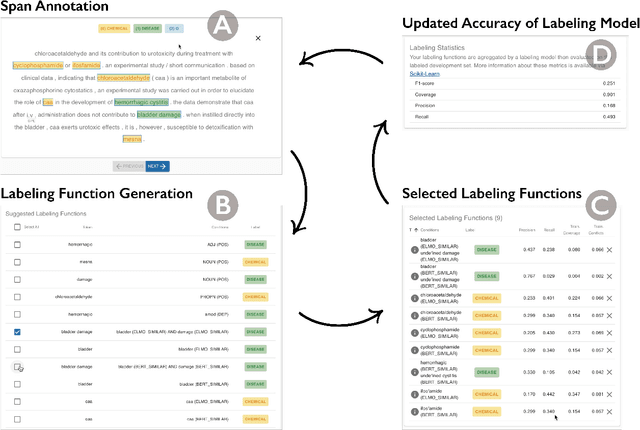
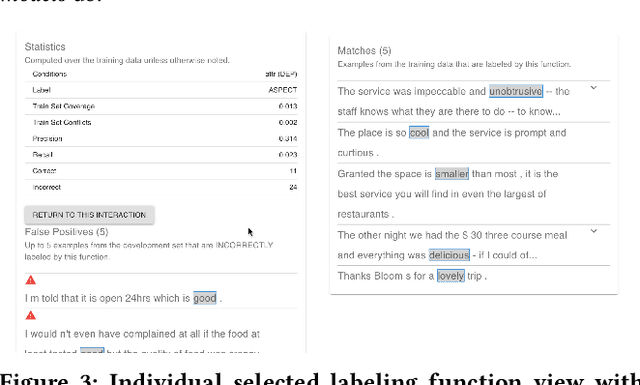
Despite rapid developments in the field of machine learning research, collecting high-quality labels for supervised learning remains a bottleneck for many applications. This difficulty is exacerbated by the fact that state-of-the-art models for NLP tasks are becoming deeper and more complex, often increasing the amount of training data required even for fine-tuning. Weak supervision methods, including data programming, address this problem and reduce the cost of label collection by using noisy label sources for supervision. However, until recently, data programming was only accessible to users who knew how to program. To bridge this gap, the Data Programming by Demonstration framework was proposed to facilitate the automatic creation of labeling functions based on a few examples labeled by a domain expert. This framework has proven successful for generating high-accuracy labeling models for document classification. In this work, we extend the DPBD framework to span-level annotation tasks, arguably one of the most time-consuming NLP labeling tasks. We built a novel tool, TagRuler, that makes it easy for annotators to build span-level labeling functions without programming and encourages them to explore trade-offs between different labeling models and active learning strategies. We empirically demonstrated that an annotator could achieve a higher F1 score using the proposed tool compared to manual labeling for different span-level annotation tasks.
Data Programming by Demonstration: A Framework for Interactively Learning Labeling Functions
Sep 15, 2020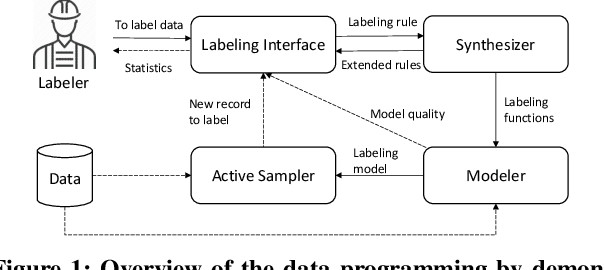
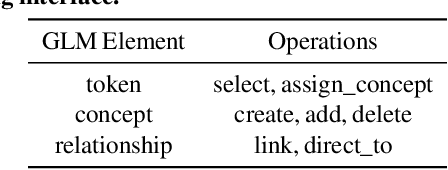
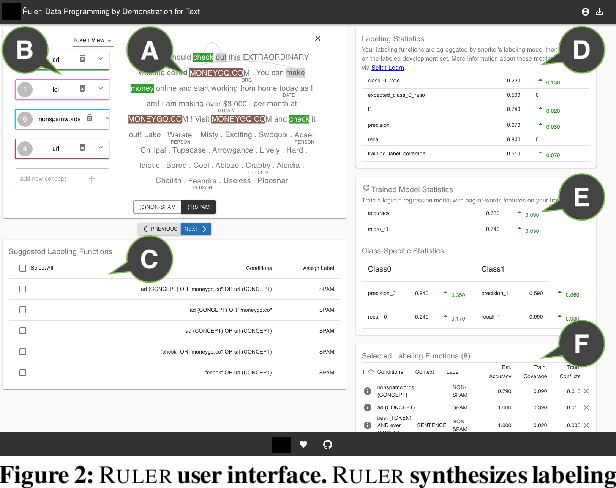

Data programming is a programmatic weak supervision approach to efficiently curate large-scale labeled training data. Writing data programs (labeling functions) requires, however, both programming literacy and domain expertise. Many subject matter experts have neither programming proficiency nor time to effectively write data programs. Furthermore, regardless of one's expertise in coding or machine learning, transferring domain expertise into labeling functions by enumerating rules and thresholds is not only time consuming but also inherently difficult. Here we propose a new framework, data programming by demonstration (DPBD), to generate labeling rules using interactive demonstrations of users. DPBD aims to relieve the burden of writing labeling functions from users, enabling them to focus on higher-level semantics such as identifying relevant signals for labeling tasks. We operationalize our framework with Ruler, an interactive system that synthesizes labeling rules for document classification by using span-level annotations of users on document examples. We compare Ruler with conventional data programming through a user study conducted with 10 data scientists creating labeling functions for sentiment and spam classification tasks. We find that Ruler is easier to use and learn and offers higher overall satisfaction, while providing discriminative model performances comparable to ones achieved by conventional data programming.
Teddy: A System for Interactive Review Analysis
Jan 15, 2020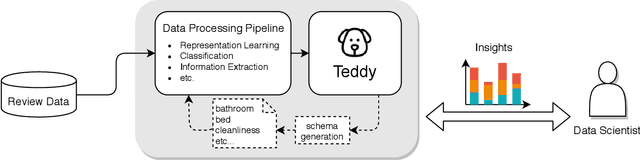

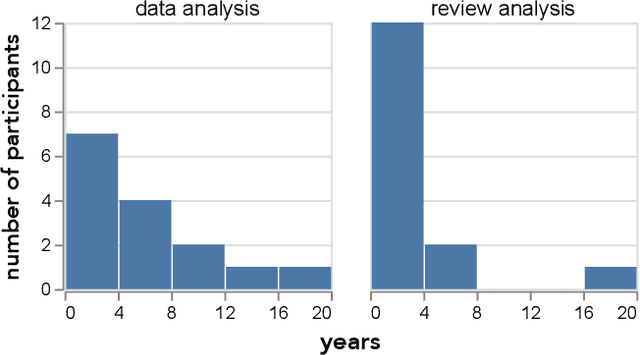
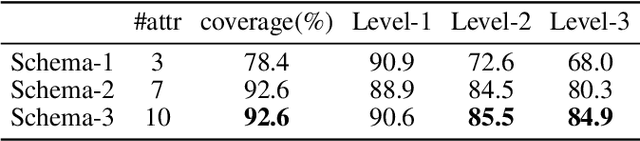
Reviews are integral to e-commerce services and products. They contain a wealth of information about the opinions and experiences of users, which can help better understand consumer decisions and improve user experience with products and services. Today, data scientists analyze reviews by developing rules and models to extract, aggregate, and understand information embedded in the review text. However, working with thousands of reviews, which are typically noisy incomplete text, can be daunting without proper tools. Here we first contribute results from an interview study that we conducted with fifteen data scientists who work with review text, providing insights into their practices and challenges. Results suggest data scientists need interactive systems for many review analysis tasks. In response we introduce Teddy, an interactive system that enables data scientists to quickly obtain insights from reviews and improve their extraction and modeling pipelines.
Happiness Entailment: Automating Suggestions for Well-Being
Jul 23, 2019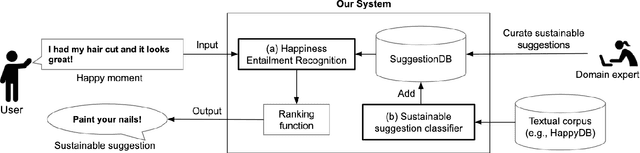

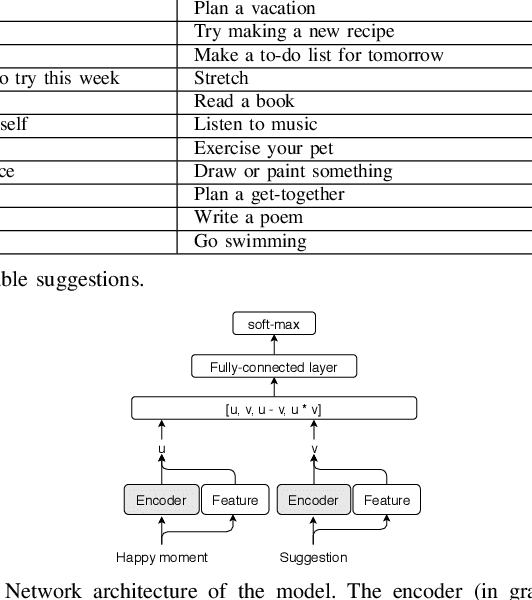
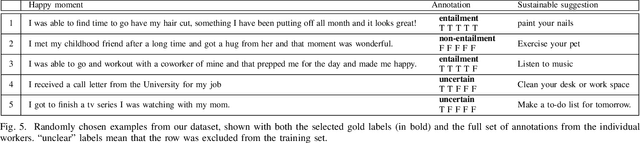
Understanding what makes people happy is a central topic in psychology. Prior work has mostly focused on developing self-reporting assessment tools for individuals and relies on experts to analyze the periodic reported assessments. One of the goals of the analysis is to understand what actions are necessary to encourage modifications in the behaviors of the individuals to improve their overall well-being. In this paper, we outline a complementary approach; on the assumption that the user journals her happy moments as short texts, a system can analyze these texts and propose sustainable suggestions for the user that may lead to an overall improvement in her well-being. We prototype one necessary component of such a system, the Happiness Entailment Recognition (HER) module, which takes as input a short text describing an event, a candidate suggestion, and outputs a determination about whether the suggestion is more likely to be good for this user based on the event described. This component is implemented as a neural network model with two encoders, one for the user input and one for the candidate actionable suggestion, with additional layers to capture psychologically significant features in the happy moment and suggestion.
Voyageur: An Experiential Travel Search Engine
Mar 04, 2019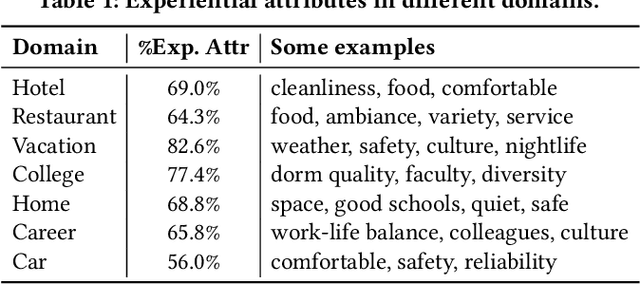
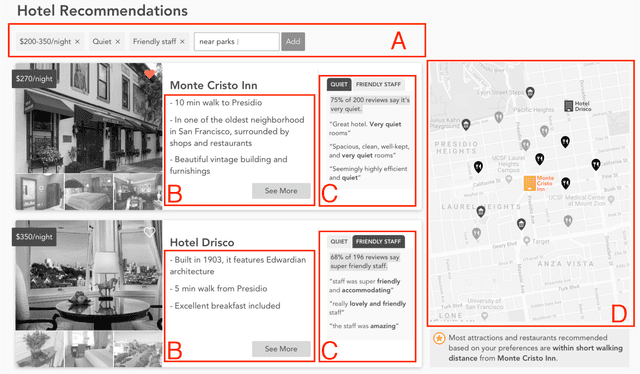
We describe Voyageur, which is an application of experiential search to the domain of travel. Unlike traditional search engines for online services, experiential search focuses on the experiential aspects of the service under consideration. In particular, Voyageur needs to handle queries for subjective aspects of the service (e.g., quiet hotel, friendly staff) and combine these with objective attributes, such as price and location. Voyageur also highlights interesting facts and tips about the services the user is considering to provide them with further insights into their choices.
HappyDB: A Corpus of 100,000 Crowdsourced Happy Moments
Jan 25, 2018
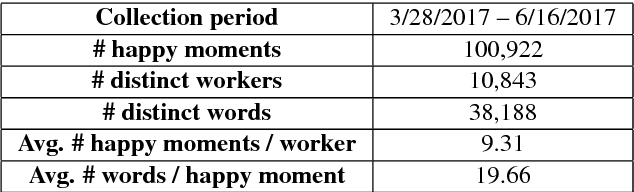
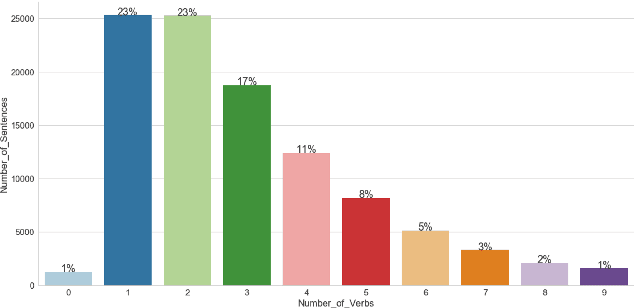
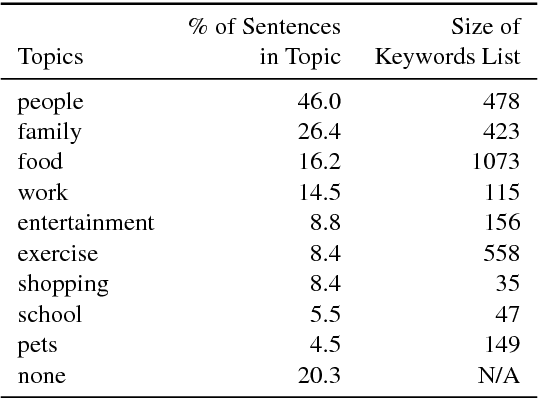
The science of happiness is an area of positive psychology concerned with understanding what behaviors make people happy in a sustainable fashion. Recently, there has been interest in developing technologies that help incorporate the findings of the science of happiness into users' daily lives by steering them towards behaviors that increase happiness. With the goal of building technology that can understand how people express their happy moments in text, we crowd-sourced HappyDB, a corpus of 100,000 happy moments that we make publicly available. This paper describes HappyDB and its properties, and outlines several important NLP problems that can be studied with the help of the corpus. We also apply several state-of-the-art analysis techniques to analyze HappyDB. Our results demonstrate the need for deeper NLP techniques to be developed which makes HappyDB an exciting resource for follow-on research.