 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMDBench: A Benchmark for Coarse-to-fine Multimodal Data Discovery in Compound AI Systems
Jun 02, 2024Compound AI systems (CASs) that employ LLMs as agents to accomplish knowledge-intensive tasks via interactions with tools and data retrievers have garnered significant interest within database and AI communities. While these systems have the potential to supplement typical analysis workflows of data analysts in enterprise data platforms, unfortunately, CASs are subject to the same data discovery challenges that analysts have encountered over the years -- silos of multimodal data sources, created across teams and departments within an organization, make it difficult to identify appropriate data sources for accomplishing the task at hand. Existing data discovery benchmarks do not model such multimodality and multiplicity of data sources. Moreover, benchmarks of CASs prioritize only evaluating end-to-end task performance. To catalyze research on evaluating the data discovery performance of multimodal data retrievers in CASs within a real-world setting, we propose CMDBench, a benchmark modeling the complexity of enterprise data platforms. We adapt existing datasets and benchmarks in open-domain -- from question answering and complex reasoning tasks to natural language querying over structured data -- to evaluate coarse- and fine-grained data discovery and task execution performance. Our experiments reveal the impact of data retriever design on downstream task performance -- a 46% drop in task accuracy on average -- across various modalities, data sources, and task difficulty. The results indicate the need to develop optimization strategies to identify appropriate LLM agents and retrievers for efficient execution of CASs over enterprise data.
Voyageur: An Experiential Travel Search Engine
Mar 04, 2019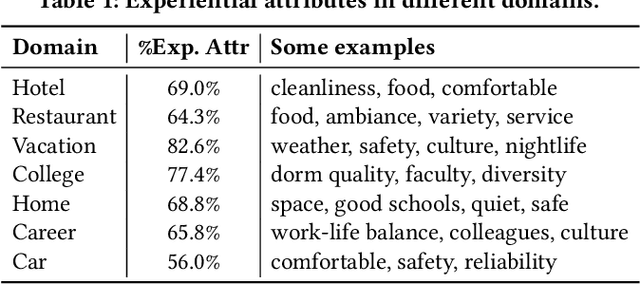
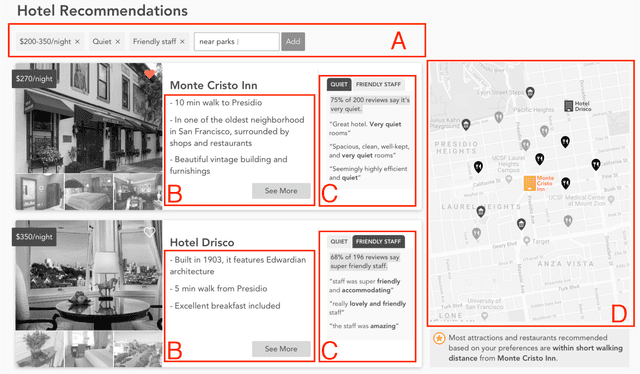
We describe Voyageur, which is an application of experiential search to the domain of travel. Unlike traditional search engines for online services, experiential search focuses on the experiential aspects of the service under consideration. In particular, Voyageur needs to handle queries for subjective aspects of the service (e.g., quiet hotel, friendly staff) and combine these with objective attributes, such as price and location. Voyageur also highlights interesting facts and tips about the services the user is considering to provide them with further insights into their choices.
Scalable Semantic Querying of Text
May 03, 2018
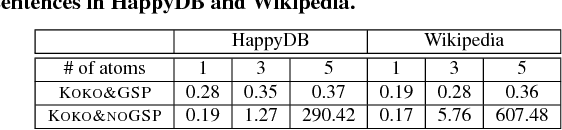
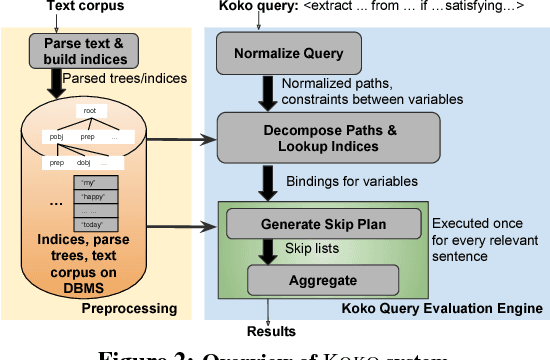
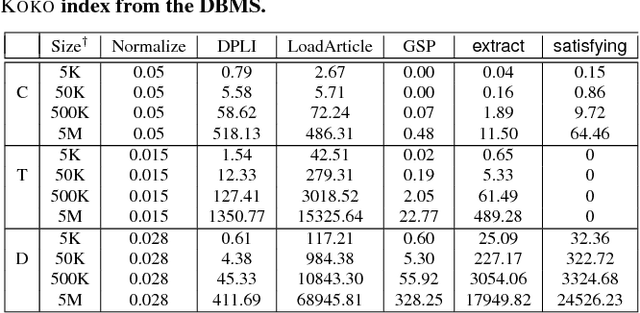
We present the KOKO system that takes declarative information extraction to a new level by incorporating advances in natural language processing techniques in its extraction language. KOKO is novel in that its extraction language simultaneously supports conditions on the surface of the text and on the structure of the dependency parse tree of sentences, thereby allowing for more refined extractions. KOKO also supports conditions that are forgiving to linguistic variation of expressing concepts and allows to aggregate evidence from the entire document in order to filter extractions. To scale up, KOKO exploits a multi-indexing scheme and heuristics for efficient extractions. We extensively evaluate KOKO over publicly available text corpora. We show that KOKO indices take up the smallest amount of space, are notably faster and more effective than a number of prior indexing schemes. Finally, we demonstrate KOKO's scale up on a corpus of 5 million Wikipedia articles.