 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectiveness of Prompt Optimization in NL2SQL Systems
May 26, 2025NL2SQL approaches have greatly benefited from the impressive capabilities of large language models (LLMs). In particular, bootstrapping an NL2SQL system for a specific domain can be as simple as instructing an LLM with sufficient contextual information, such as schema details and translation demonstrations. However, building an accurate system still requires the rigorous task of selecting the right context for each query-including identifying relevant schema elements, cell values, and suitable exemplars that help the LLM understand domain-specific nuances. Retrieval-based methods have become the go-to approach for identifying such context. While effective, these methods introduce additional inference-time costs due to the retrieval process. In this paper, we argue that production scenarios demand high-precision, high-performance NL2SQL systems, rather than simply high-quality SQL generation, which is the focus of most current NL2SQL approaches. In such scenarios, the careful selection of a static set of exemplars-capturing the intricacies of the query log, target database, SQL constructs, and execution latencies-plays a more crucial role than exemplar selection based solely on similarity. The key challenge, however, lies in identifying a representative set of exemplars for a given production setting. To this end, we propose a prompt optimization framework that not only addresses the high-precision requirement but also optimizes the performance of the generated SQL through multi-objective optimization. Preliminary empirical analysis demonstrates the effectiveness of the proposed framework.
Orchestrating Agents and Data for Enterprise: A Blueprint Architecture for Compound AI
Apr 10, 2025Large language models (LLMs) have gained significant interest in industry due to their impressive capabilities across a wide range of tasks. However, the widespread adoption of LLMs presents several challenges, such as integration into existing applications and infrastructure, utilization of company proprietary data, models, and APIs, and meeting cost, quality, responsiveness, and other requirements. To address these challenges, there is a notable shift from monolithic models to compound AI systems, with the premise of more powerful, versatile, and reliable applications. However, progress thus far has been piecemeal, with proposals for agentic workflows, programming models, and extended LLM capabilities, without a clear vision of an overall architecture. In this paper, we propose a 'blueprint architecture' for compound AI systems for orchestrating agents and data for enterprise applications. In our proposed architecture the key orchestration concept is 'streams' to coordinate the flow of data and instructions among agents. Existing proprietary models and APIs in the enterprise are mapped to 'agents', defined in an 'agent registry' that serves agent metadata and learned representations for search and planning. Agents can utilize proprietary data through a 'data registry' that similarly registers enterprise data of various modalities. Tying it all together, data and task 'planners' break down, map, and optimize tasks and queries for given quality of service (QoS) requirements such as cost, accuracy, and latency. We illustrate an implementation of the architecture for a use-case in the HR domain and discuss opportunities and challenges for 'agentic AI' in the enterprise.
CMDBench: A Benchmark for Coarse-to-fine Multimodal Data Discovery in Compound AI Systems
Jun 02, 2024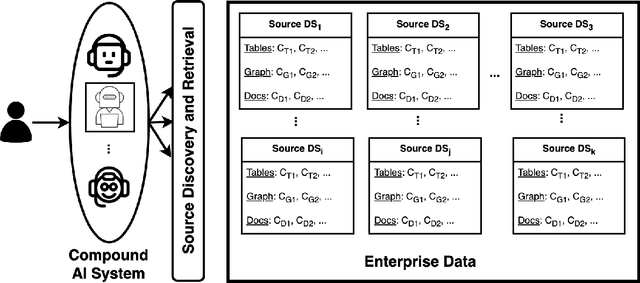

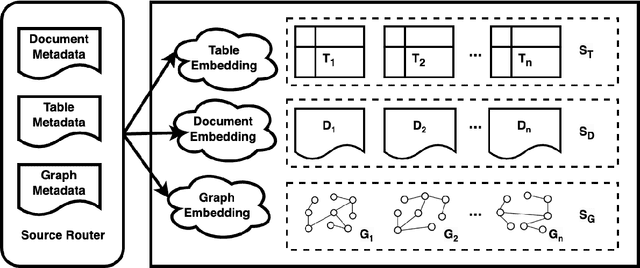
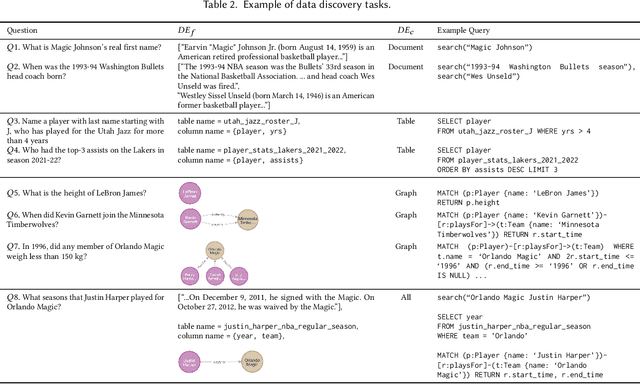
Compound AI systems (CASs) that employ LLMs as agents to accomplish knowledge-intensive tasks via interactions with tools and data retrievers have garnered significant interest within database and AI communities. While these systems have the potential to supplement typical analysis workflows of data analysts in enterprise data platforms, unfortunately, CASs are subject to the same data discovery challenges that analysts have encountered over the years -- silos of multimodal data sources, created across teams and departments within an organization, make it difficult to identify appropriate data sources for accomplishing the task at hand. Existing data discovery benchmarks do not model such multimodality and multiplicity of data sources. Moreover, benchmarks of CASs prioritize only evaluating end-to-end task performance. To catalyze research on evaluating the data discovery performance of multimodal data retrievers in CASs within a real-world setting, we propose CMDBench, a benchmark modeling the complexity of enterprise data platforms. We adapt existing datasets and benchmarks in open-domain -- from question answering and complex reasoning tasks to natural language querying over structured data -- to evaluate coarse- and fine-grained data discovery and task execution performance. Our experiments reveal the impact of data retriever design on downstream task performance -- a 46% drop in task accuracy on average -- across various modalities, data sources, and task difficulty. The results indicate the need to develop optimization strategies to identify appropriate LLM agents and retrievers for efficient execution of CASs over enterprise data.
A Blueprint Architecture of Compound AI Systems for Enterprise
Jun 02, 2024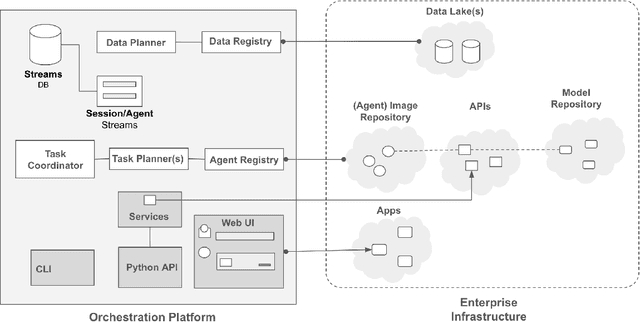
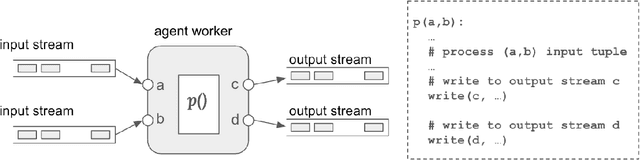
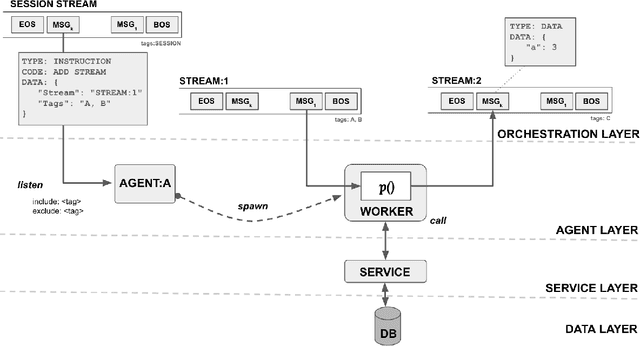
Large Language Models (LLMs) have showcased remarkable capabilities surpassing conventional NLP challenges, creating opportunities for use in production use cases. Towards this goal, there is a notable shift to building compound AI systems, wherein LLMs are integrated into an expansive software infrastructure with many components like models, retrievers, databases and tools. In this paper, we introduce a blueprint architecture for compound AI systems to operate in enterprise settings cost-effectively and feasibly. Our proposed architecture aims for seamless integration with existing compute and data infrastructure, with ``stream'' serving as the key orchestration concept to coordinate data and instructions among agents and other components. Task and data planners, respectively, break down, map, and optimize tasks and data to available agents and data sources defined in respective registries, given production constraints such as accuracy and latency.
Reasoning Capacity in Multi-Agent Systems: Limitations, Challenges and Human-Centered Solutions
Feb 02, 2024Remarkable performance of large language models (LLMs) in a variety of tasks brings forth many opportunities as well as challenges of utilizing them in production settings. Towards practical adoption of LLMs, multi-agent systems hold great promise to augment, integrate, and orchestrate LLMs in the larger context of enterprise platforms that use existing proprietary data and models to tackle complex real-world tasks. Despite the tremendous success of these systems, current approaches rely on narrow, single-focus objectives for optimization and evaluation, often overlooking potential constraints in real-world scenarios, including restricted budgets, resources and time. Furthermore, interpreting, analyzing, and debugging these systems requires different components to be evaluated in relation to one another. This demand is currently not feasible with existing methodologies. In this postion paper, we introduce the concept of reasoning capacity as a unifying criterion to enable integration of constraints during optimization and establish connections among different components within the system, which also enable a more holistic and comprehensive approach to evaluation. We present a formal definition of reasoning capacity and illustrate its utility in identifying limitations within each component of the system. We then argue how these limitations can be addressed with a self-reflective process wherein human-feedback is used to alleviate shortcomings in reasoning and enhance overall consistency of the system.
Towards Multifaceted Human-Centered AI
Jan 09, 2023
Human-centered AI workflows involve stakeholders with multiple roles interacting with each other and automated agents to accomplish diverse tasks. In this paper, we call for a holistic view when designing support mechanisms, such as interaction paradigms, interfaces, and systems, for these multifaceted workflows.
MEGAnno: Exploratory Labeling for NLP in Computational Notebooks
Jan 08, 2023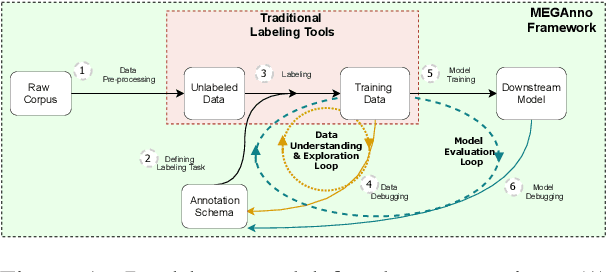
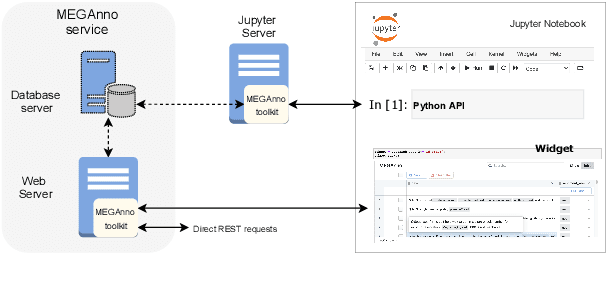
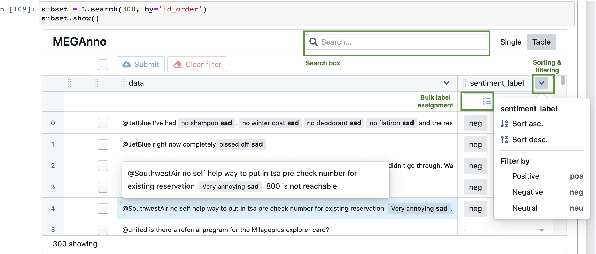
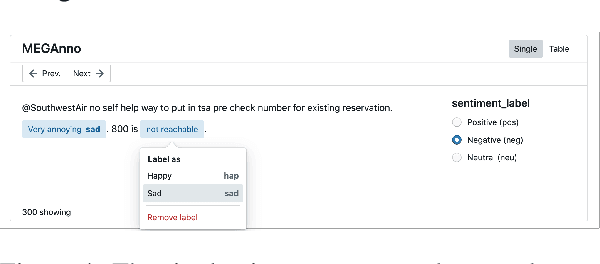
We present MEGAnno, a novel exploratory annotation framework designed for NLP researchers and practitioners. Unlike existing labeling tools that focus on data labeling only, our framework aims to support a broader, iterative ML workflow including data exploration and model development. With MEGAnno's API, users can programmatically explore the data through sophisticated search and automated suggestion functions and incrementally update task schema as their project evolve. Combined with our widget, the users can interactively sort, filter, and assign labels to multiple items simultaneously in the same notebook where the rest of the NLP project resides. We demonstrate MEGAnno's flexible, exploratory, efficient, and seamless labeling experience through a sentiment analysis use case.
HEIDL: Learning Linguistic Expressions with Deep Learning and Human-in-the-Loop
Jul 25, 2019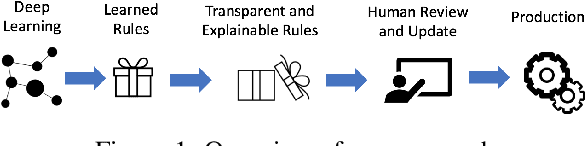
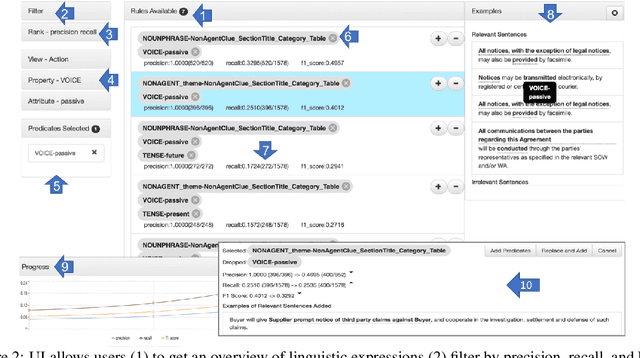
While the role of humans is increasingly recognized in machine learning community, representation of and interaction with models in current human-in-the-loop machine learning (HITL-ML) approaches are too low-level and far-removed from human's conceptual models. We demonstrate HEIDL, a prototype HITL-ML system that exposes the machine-learned model through high-level, explainable linguistic expressions formed of predicates representing semantic structure of text. In HEIDL, human's role is elevated from simply evaluating model predictions to interpreting and even updating the model logic directly by enabling interaction with rule predicates themselves. Raising the currency of interaction to such semantic levels calls for new interaction paradigms between humans and machines that result in improved productivity for text analytics model development process. Moreover, by involving humans in the process, the human-machine co-created models generalize better to unseen data as domain experts are able to instill their expertise by extrapolating from what has been learned by automated algorithms from few labelled data.