 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectiveness of Prompt Optimization in NL2SQL Systems
May 26, 2025NL2SQL approaches have greatly benefited from the impressive capabilities of large language models (LLMs). In particular, bootstrapping an NL2SQL system for a specific domain can be as simple as instructing an LLM with sufficient contextual information, such as schema details and translation demonstrations. However, building an accurate system still requires the rigorous task of selecting the right context for each query-including identifying relevant schema elements, cell values, and suitable exemplars that help the LLM understand domain-specific nuances. Retrieval-based methods have become the go-to approach for identifying such context. While effective, these methods introduce additional inference-time costs due to the retrieval process. In this paper, we argue that production scenarios demand high-precision, high-performance NL2SQL systems, rather than simply high-quality SQL generation, which is the focus of most current NL2SQL approaches. In such scenarios, the careful selection of a static set of exemplars-capturing the intricacies of the query log, target database, SQL constructs, and execution latencies-plays a more crucial role than exemplar selection based solely on similarity. The key challenge, however, lies in identifying a representative set of exemplars for a given production setting. To this end, we propose a prompt optimization framework that not only addresses the high-precision requirement but also optimizes the performance of the generated SQL through multi-objective optimization. Preliminary empirical analysis demonstrates the effectiveness of the proposed framework.
Orchestrating Agents and Data for Enterprise: A Blueprint Architecture for Compound AI
Apr 10, 2025Large language models (LLMs) have gained significant interest in industry due to their impressive capabilities across a wide range of tasks. However, the widespread adoption of LLMs presents several challenges, such as integration into existing applications and infrastructure, utilization of company proprietary data, models, and APIs, and meeting cost, quality, responsiveness, and other requirements. To address these challenges, there is a notable shift from monolithic models to compound AI systems, with the premise of more powerful, versatile, and reliable applications. However, progress thus far has been piecemeal, with proposals for agentic workflows, programming models, and extended LLM capabilities, without a clear vision of an overall architecture. In this paper, we propose a 'blueprint architecture' for compound AI systems for orchestrating agents and data for enterprise applications. In our proposed architecture the key orchestration concept is 'streams' to coordinate the flow of data and instructions among agents. Existing proprietary models and APIs in the enterprise are mapped to 'agents', defined in an 'agent registry' that serves agent metadata and learned representations for search and planning. Agents can utilize proprietary data through a 'data registry' that similarly registers enterprise data of various modalities. Tying it all together, data and task 'planners' break down, map, and optimize tasks and queries for given quality of service (QoS) requirements such as cost, accuracy, and latency. We illustrate an implementation of the architecture for a use-case in the HR domain and discuss opportunities and challenges for 'agentic AI' in the enterprise.
A Blueprint Architecture of Compound AI Systems for Enterprise
Jun 02, 2024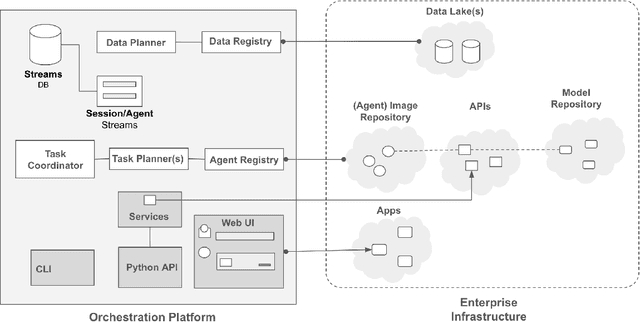
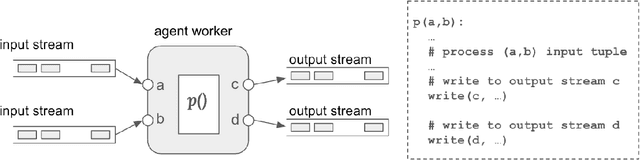
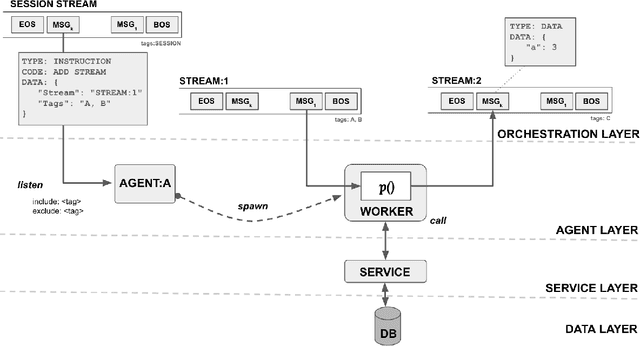
Large Language Models (LLMs) have showcased remarkable capabilities surpassing conventional NLP challenges, creating opportunities for use in production use cases. Towards this goal, there is a notable shift to building compound AI systems, wherein LLMs are integrated into an expansive software infrastructure with many components like models, retrievers, databases and tools. In this paper, we introduce a blueprint architecture for compound AI systems to operate in enterprise settings cost-effectively and feasibly. Our proposed architecture aims for seamless integration with existing compute and data infrastructure, with ``stream'' serving as the key orchestration concept to coordinate data and instructions among agents and other components. Task and data planners, respectively, break down, map, and optimize tasks and data to available agents and data sources defined in respective registries, given production constraints such as accuracy and latency.
Retrieval Helps or Hurts? A Deeper Dive into the Efficacy of Retrieval Augmentation to Language Models
Feb 21, 2024While large language models (LMs) demonstrate remarkable performance, they encounter challenges in providing accurate responses when queried for information beyond their pre-trained memorization. Although augmenting them with relevant external information can mitigate these issues, failure to consider the necessity of retrieval may adversely affect overall performance. Previous research has primarily focused on examining how entities influence retrieval models and knowledge recall in LMs, leaving other aspects relatively unexplored. In this work, our goal is to offer a more detailed, fact-centric analysis by exploring the effects of combinations of entities and relations. To facilitate this, we construct a new question answering (QA) dataset called WiTQA (Wikipedia Triple Question Answers). This dataset includes questions about entities and relations of various popularity levels, each accompanied by a supporting passage. Our extensive experiments with diverse LMs and retrievers reveal when retrieval does not consistently enhance LMs from the viewpoints of fact-centric popularity.Confirming earlier findings, we observe that larger LMs excel in recalling popular facts. However, they notably encounter difficulty with infrequent entity-relation pairs compared to retrievers. Interestingly, they can effectively retain popular relations of less common entities. We demonstrate the efficacy of our finer-grained metric and insights through an adaptive retrieval system that selectively employs retrieval and recall based on the frequencies of entities and relations in the question.
XATU: A Fine-grained Instruction-based Benchmark for Explainable Text Updates
Sep 20, 2023



Text editing is a crucial task that involves modifying text to better align with user intents. However, existing text editing benchmark datasets have limitations in providing only coarse-grained instructions. Consequently, although the edited output may seem reasonable, it often deviates from the intended changes outlined in the gold reference, resulting in low evaluation scores. To comprehensively investigate the text editing capabilities of large language models, this paper introduces XATU, the first benchmark specifically designed for fine-grained instruction-based explainable text editing. XATU covers a wide range of topics and text types, incorporating lexical, syntactic, semantic, and knowledge-intensive edits. To enhance interpretability, we leverage high-quality data sources and human annotation, resulting in a benchmark that includes fine-grained instructions and gold-standard edit explanations. By evaluating existing open and closed large language models against our benchmark, we demonstrate the effectiveness of instruction tuning and the impact of underlying architecture across various editing tasks. Furthermore, extensive experimentation reveals the significant role of explanations in fine-tuning language models for text editing tasks. The benchmark will be open-sourced to support reproduction and facilitate future research.
Why are NLP Models Fumbling at Elementary Math? A Survey of Deep Learning based Word Problem Solvers
May 31, 2022
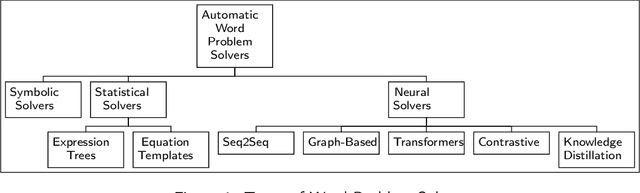

From the latter half of the last decade, there has been a growing interest in developing algorithms for automatically solving mathematical word problems (MWP). It is a challenging and unique task that demands blending surface level text pattern recognition with mathematical reasoning. In spite of extensive research, we are still miles away from building robust representations of elementary math word problems and effective solutions for the general task. In this paper, we critically examine the various models that have been developed for solving word problems, their pros and cons and the challenges ahead. In the last two years, a lot of deep learning models have recorded competing results on benchmark datasets, making a critical and conceptual analysis of literature highly useful at this juncture. We take a step back and analyse why, in spite of this abundance in scholarly interest, the predominantly used experiment and dataset designs continue to be a stumbling block. From the vantage point of having analyzed the literature closely, we also endeavour to provide a road-map for future math word problem research.
A Benchmark for Generalizable and Interpretable Temporal Question Answering over Knowledge Bases
Jan 15, 2022
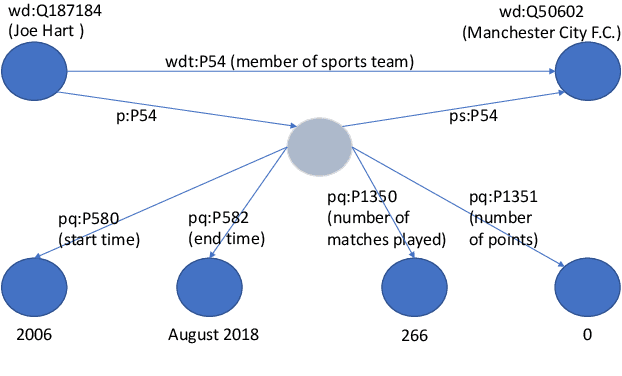


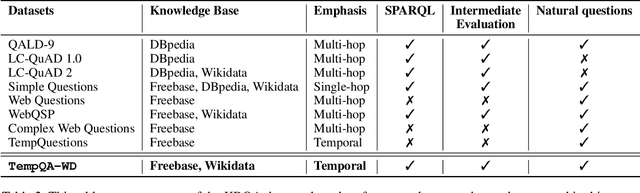
Knowledge Base Question Answering (KBQA) tasks that involve complex reasoning are emerging as an important research direction. However, most existing KBQA datasets focus primarily on generic multi-hop reasoning over explicit facts, largely ignoring other reasoning types such as temporal, spatial, and taxonomic reasoning. In this paper, we present a benchmark dataset for temporal reasoning, TempQA-WD, to encourage research in extending the present approaches to target a more challenging set of complex reasoning tasks. Specifically, our benchmark is a temporal question answering dataset with the following advantages: (a) it is based on Wikidata, which is the most frequently curated, openly available knowledge base, (b) it includes intermediate sparql queries to facilitate the evaluation of semantic parsing based approaches for KBQA, and (c) it generalizes to multiple knowledge bases: Freebase and Wikidata. The TempQA-WD dataset is available at https://github.com/IBM/tempqa-wd.
SYGMA: System for Generalizable Modular Question Answering OverKnowledge Bases
Sep 28, 2021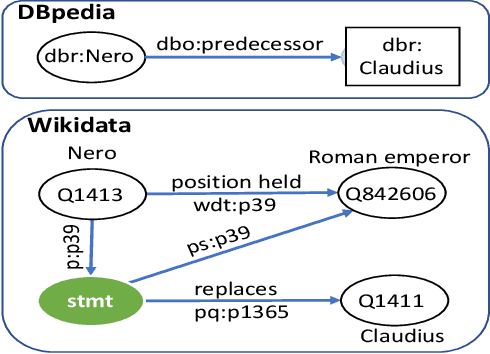


Knowledge Base Question Answering (KBQA) tasks that in-volve complex reasoning are emerging as an important re-search direction. However, most KBQA systems struggle withgeneralizability, particularly on two dimensions: (a) acrossmultiple reasoning types where both datasets and systems haveprimarily focused on multi-hop reasoning, and (b) across mul-tiple knowledge bases, where KBQA approaches are specif-ically tuned to a single knowledge base. In this paper, wepresent SYGMA, a modular approach facilitating general-izability across multiple knowledge bases and multiple rea-soning types. Specifically, SYGMA contains three high levelmodules: 1) KB-agnostic question understanding module thatis common across KBs 2) Rules to support additional reason-ing types and 3) KB-specific question mapping and answeringmodule to address the KB-specific aspects of the answer ex-traction. We demonstrate effectiveness of our system by evalu-ating on datasets belonging to two distinct knowledge bases,DBpedia and Wikidata. In addition, to demonstrate extensi-bility to additional reasoning types we evaluate on multi-hopreasoning datasets and a new Temporal KBQA benchmarkdataset on Wikidata, namedTempQA-WD1, introduced in thispaper. We show that our generalizable approach has bettercompetetive performance on multiple datasets on DBpediaand Wikidata that requires both multi-hop and temporal rea-soning
LNN-EL: A Neuro-Symbolic Approach to Short-text Entity Linking
Jun 17, 2021
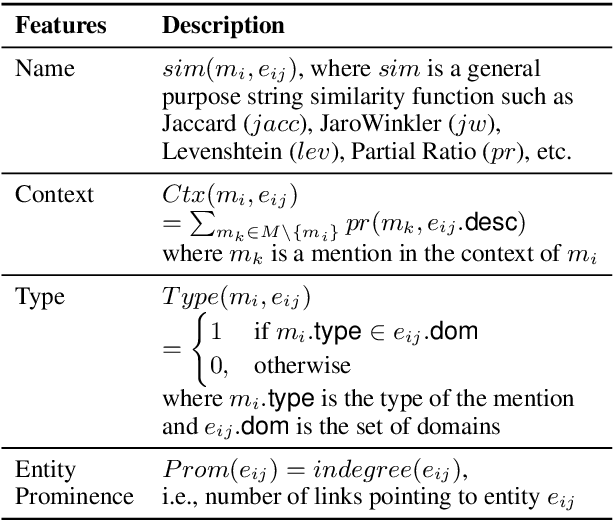
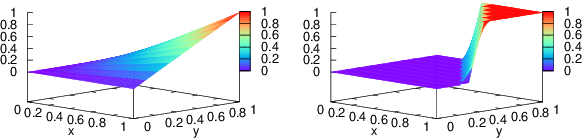
Entity linking (EL), the task of disambiguating mentions in text by linking them to entities in a knowledge graph, is crucial for text understanding, question answering or conversational systems. Entity linking on short text (e.g., single sentence or question) poses particular challenges due to limited context. While prior approaches use either heuristics or black-box neural methods, here we propose LNN-EL, a neuro-symbolic approach that combines the advantages of using interpretable rules based on first-order logic with the performance of neural learning. Even though constrained to using rules, LNN-EL performs competitively against SotA black-box neural approaches, with the added benefits of extensibility and transferability. In particular, we show that we can easily blend existing rule templates given by a human expert, with multiple types of features (priors, BERT encodings, box embeddings, etc), and even scores resulting from previous EL methods, thus improving on such methods. For instance, on the LC-QuAD-1.0 dataset, we show more than $4$\% increase in F1 score over previous SotA. Finally, we show that the inductive bias offered by using logic results in learned rules that transfer well across datasets, even without fine tuning, while maintaining high accuracy.
Question Answering over Knowledge Bases by Leveraging Semantic Parsing and Neuro-Symbolic Reasoning
Dec 03, 2020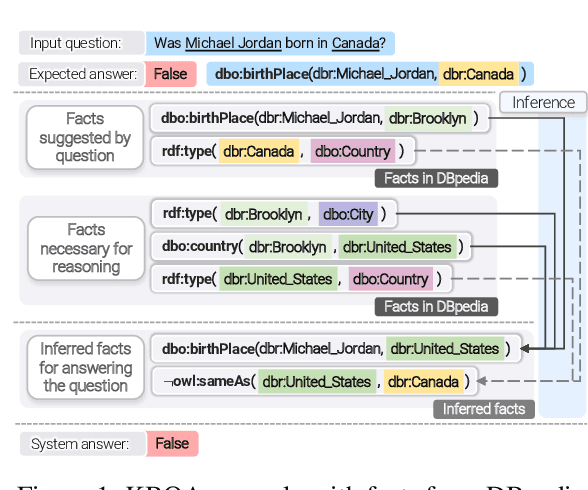
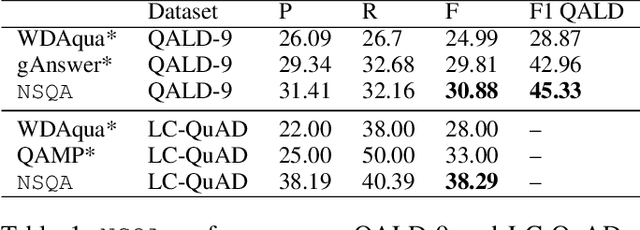
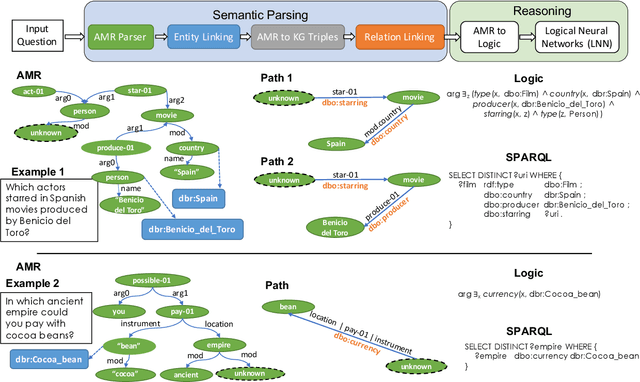

Knowledge base question answering (KBQA) is an important task in Natural Language Processing. Existing approaches face significant challenges including complex question understanding, necessity for reasoning, and lack of large training datasets. In this work, we propose a semantic parsing and reasoning-based Neuro-Symbolic Question Answering(NSQA) system, that leverages (1) Abstract Meaning Representation (AMR) parses for task-independent question under-standing; (2) a novel path-based approach to transform AMR parses into candidate logical queries that are aligned to the KB; (3) a neuro-symbolic reasoner called Logical Neural Net-work (LNN) that executes logical queries and reasons over KB facts to provide an answer; (4) system of systems approach,which integrates multiple, reusable modules that are trained specifically for their individual tasks (e.g. semantic parsing,entity linking, and relationship linking) and do not require end-to-end training data. NSQA achieves state-of-the-art performance on QALD-9 and LC-QuAD 1.0. NSQA's novelty lies in its modular neuro-symbolic architecture and its task-general approach to interpreting natural language questions.