 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNews about Global North considered Truthful! The Geo-political Veracity Gradient in Global South News
Feb 07, 2025

While there has been much research into developing AI techniques for fake news detection aided by various benchmark datasets, it has often been pointed out that fake news in different geo-political regions traces different contours. In this work we uncover, through analytical arguments and empirical evidence, the existence of an important characteristic in news originating from the Global South viz., the geo-political veracity gradient. In particular, we show that Global South news about topics from Global North -- such as news from an Indian news agency on US elections -- tend to be less likely to be fake. Observing through the prism of the political economy of fake news creation, we posit that this pattern could be due to the relative lack of monetarily aligned incentives in producing fake news about a different region than the regional remit of the audience. We provide empirical evidence for this from benchmark datasets. We also empirically analyze the consequences of this effect in applying AI-based fake news detection models for fake news AI trained on one region within another regional context. We locate our work within emerging critical scholarship on geo-political biases within AI in general, particularly with AI usage in fake news identification; we hope our insight into the geo-political veracity gradient could help steer fake news AI scholarship towards positively impacting Global South societies.
AI Safety: Necessary, but insufficient and possibly problematic
Mar 26, 2024This article critically examines the recent hype around AI safety. We first start with noting the nature of the AI safety hype as being dominated by governments and corporations, and contrast it with other avenues within AI research on advancing social good. We consider what 'AI safety' actually means, and outline the dominant concepts that the digital footprint of AI safety aligns with. We posit that AI safety has a nuanced and uneasy relationship with transparency and other allied notions associated with societal good, indicating that it is an insufficient notion if the goal is that of societal good in a broad sense. We note that the AI safety debate has already influenced some regulatory efforts in AI, perhaps in not so desirable directions. We also share our concerns on how AI safety may normalize AI that advances structural harm through providing exploitative and harmful AI with a veneer of safety.
AI and Core Electoral Processes: Mapping the Horizons
Feb 07, 2023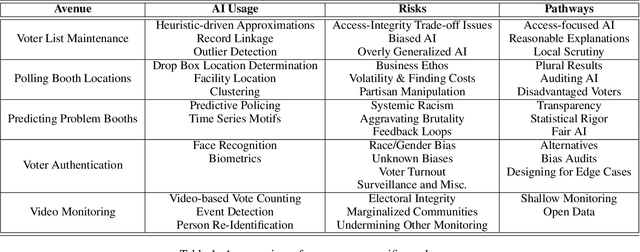



Significant enthusiasm around AI uptake has been witnessed across societies globally. The electoral process -- the time, place and manner of elections within democratic nations -- has been among those very rare sectors in which AI has not penetrated much. Electoral management bodies in many countries have recently started exploring and deliberating over the use of AI in the electoral process. In this paper, we consider five representative avenues within the core electoral process which have potential for AI usage, and map the challenges involved in using AI within them. These five avenues are: voter list maintenance, determining polling booth locations, polling booth protection processes, voter authentication and video monitoring of elections. Within each of these avenues, we lay down the context, illustrate current or potential usage of AI, and discuss extant or potential ramifications of AI usage, and potential directions for mitigating risks while considering AI usage. We believe that the scant current usage of AI within electoral processes provides a very rare opportunity, that of being able to deliberate on the risks and mitigation possibilities, prior to real and widespread AI deployment. This paper is an attempt to map the horizons of risks and opportunities in using AI within the electoral processes and to help shape the debate around the topic.
Cluster-level Group Representativity Fairness in $k$-means Clustering
Dec 29, 2022There has been much interest recently in developing fair clustering algorithms that seek to do justice to the representation of groups defined along sensitive attributes such as race and gender. We observe that clustering algorithms could generate clusters such that different groups are disadvantaged within different clusters. We develop a clustering algorithm, building upon the centroid clustering paradigm pioneered by classical algorithms such as $k$-means, where we focus on mitigating the unfairness experienced by the most-disadvantaged group within each cluster. Our method uses an iterative optimisation paradigm whereby an initial cluster assignment is modified by reassigning objects to clusters such that the worst-off sensitive group within each cluster is benefitted. We demonstrate the effectiveness of our method through extensive empirical evaluations over a novel evaluation metric on real-world datasets. Specifically, we show that our method is effective in enhancing cluster-level group representativity fairness significantly at low impact on cluster coherence.
On Gender Bias in Fake News
Sep 27, 2022
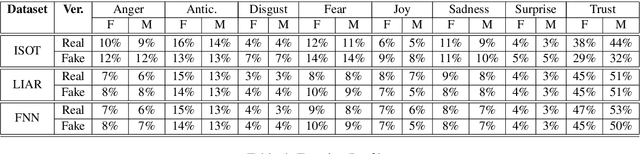
Data science research into fake news has gathered much momentum in recent years, arguably facilitated by the emergence of large public benchmark datasets. While it has been well-established within media studies that gender bias is an issue that pervades news media, there has been very little exploration into the relationship between gender bias and fake news. In this work, we provide the first empirical analysis of gender bias vis-a-vis fake news, leveraging simple and transparent lexicon-based methods over public benchmark datasets. Our analysis establishes the increased prevalance of gender bias in fake news across three facets viz., abundance, affect and proximal words. The insights from our analysis provide a strong argument that gender bias needs to be an important consideration in research into fake news.
Why are NLP Models Fumbling at Elementary Math? A Survey of Deep Learning based Word Problem Solvers
May 31, 2022
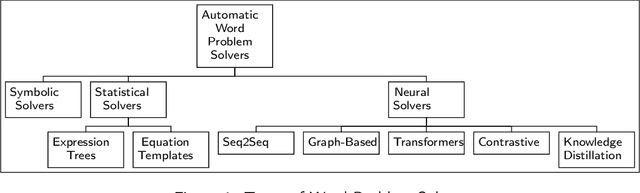

From the latter half of the last decade, there has been a growing interest in developing algorithms for automatically solving mathematical word problems (MWP). It is a challenging and unique task that demands blending surface level text pattern recognition with mathematical reasoning. In spite of extensive research, we are still miles away from building robust representations of elementary math word problems and effective solutions for the general task. In this paper, we critically examine the various models that have been developed for solving word problems, their pros and cons and the challenges ahead. In the last two years, a lot of deep learning models have recorded competing results on benchmark datasets, making a critical and conceptual analysis of literature highly useful at this juncture. We take a step back and analyse why, in spite of this abundance in scholarly interest, the predominantly used experiment and dataset designs continue to be a stumbling block. From the vantage point of having analyzed the literature closely, we also endeavour to provide a road-map for future math word problem research.
Exploring Rawlsian Fairness for K-Means Clustering
May 04, 2022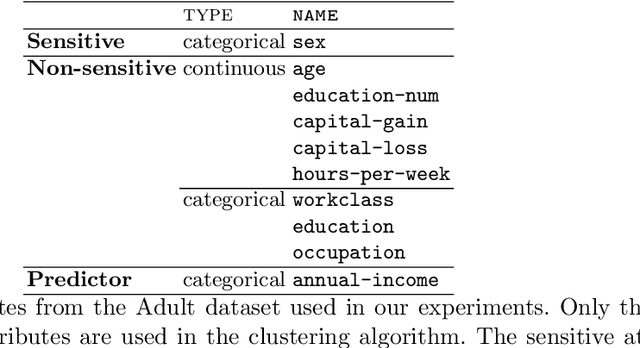
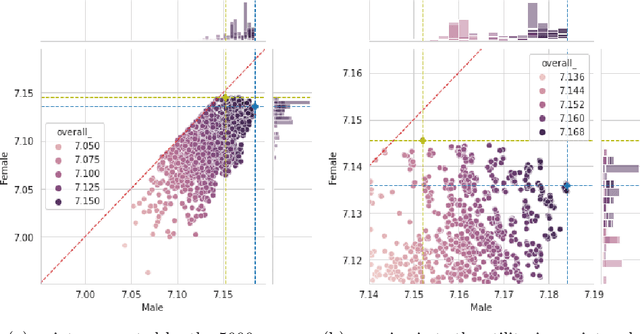
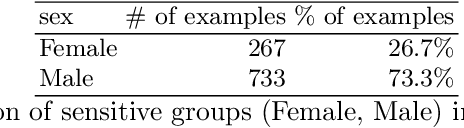
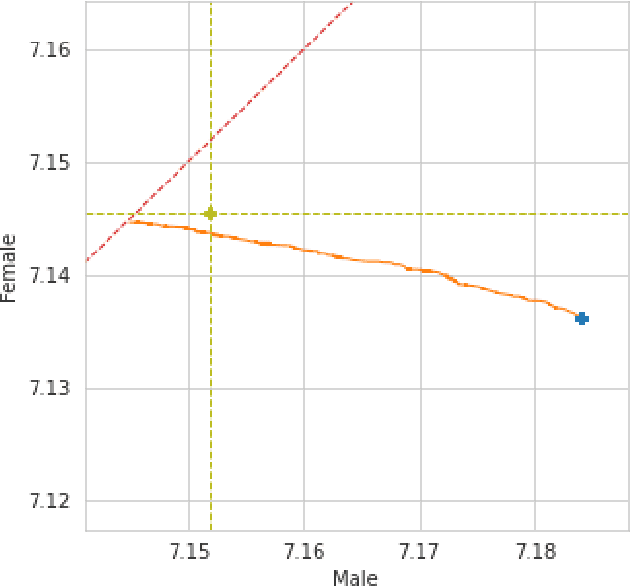
We conduct an exploratory study that looks at incorporating John Rawls' ideas on fairness into existing unsupervised machine learning algorithms. Our focus is on the task of clustering, specifically the k-means clustering algorithm. To the best of our knowledge, this is the first work that uses Rawlsian ideas in clustering. Towards this, we attempt to develop a postprocessing technique i.e., one that operates on the cluster assignment generated by the standard k-means clustering algorithm. Our technique perturbs this assignment over a number of iterations to make it fairer according to Rawls' difference principle while minimally affecting the overall utility. As the first step, we consider two simple perturbation operators -- $\mathbf{R_1}$ and $\mathbf{R_2}$ -- that reassign examples in a given cluster assignment to new clusters; $\mathbf{R_1}$ assigning a single example to a new cluster, and $\mathbf{R_2}$ a pair of examples to new clusters. Our experiments on a sample of the Adult dataset demonstrate that both operators make meaningful perturbations in the cluster assignment towards incorporating Rawls' difference principle, with $\mathbf{R_2}$ being more efficient than $\mathbf{R_1}$ in terms of the number of iterations. However, we observe that there is still a need to design operators that make significantly better perturbations. Nevertheless, both operators provide good baselines for designing and comparing any future operator, and we hope our findings would aid future work in this direction.
FiSH: Fair Spatial Hotspots
Jun 01, 2021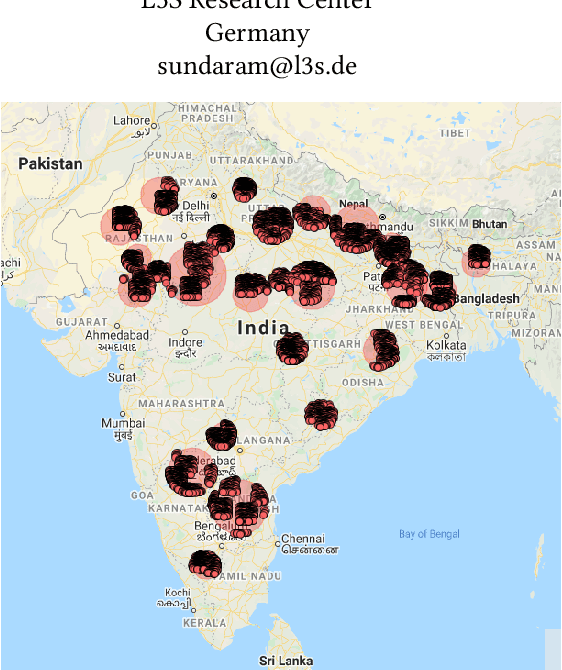

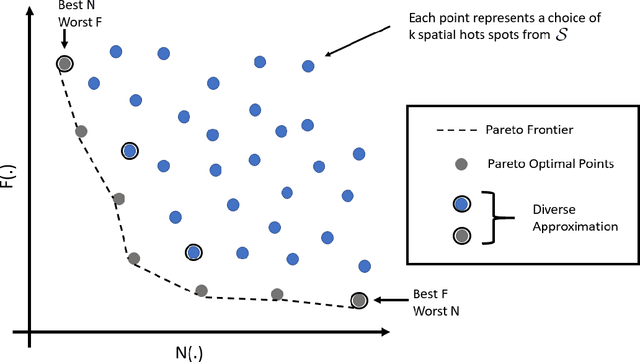
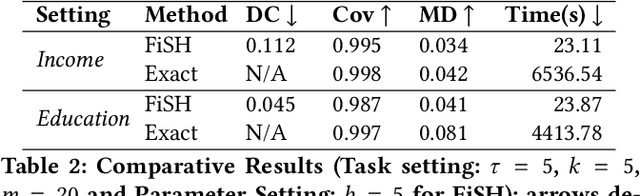
Pervasiveness of tracking devices and enhanced availability of spatially located data has deepened interest in using them for various policy interventions, through computational data analysis tasks such as spatial hot spot detection. In this paper, we consider, for the first time to our best knowledge, fairness in detecting spatial hot spots. We motivate the need for ensuring fairness through statistical parity over the collective population covered across chosen hot spots. We then characterize the task of identifying a diverse set of solutions in the noteworthiness-fairness trade-off spectrum, to empower the user to choose a trade-off justified by the policy domain. Being a novel task formulation, we also develop a suite of evaluation metrics for fair hot spots, motivated by the need to evaluate pertinent aspects of the task. We illustrate the computational infeasibility of identifying fair hot spots using naive and/or direct approaches and devise a method, codenamed {\it FiSH}, for efficiently identifying high-quality, fair and diverse sets of spatial hot spots. FiSH traverses the tree-structured search space using heuristics that guide it towards identifying effective and fair sets of spatial hot spots. Through an extensive empirical analysis over a real-world dataset from the domain of human development, we illustrate that FiSH generates high-quality solutions at fast response times.
Exploring Thematic Coherence in Fake News
Dec 17, 2020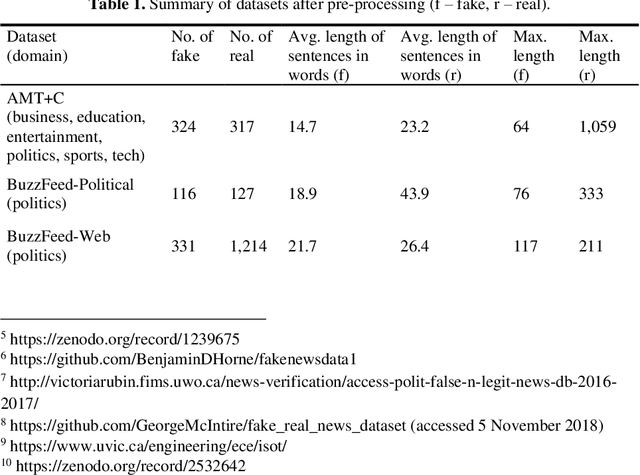
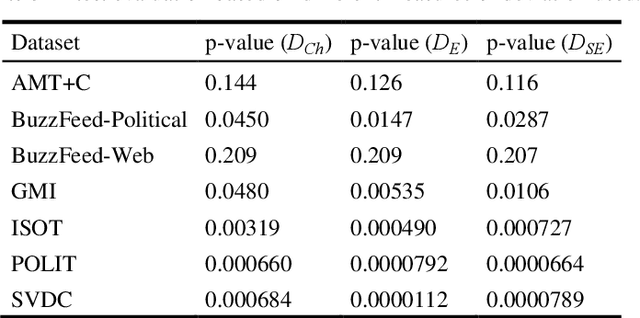
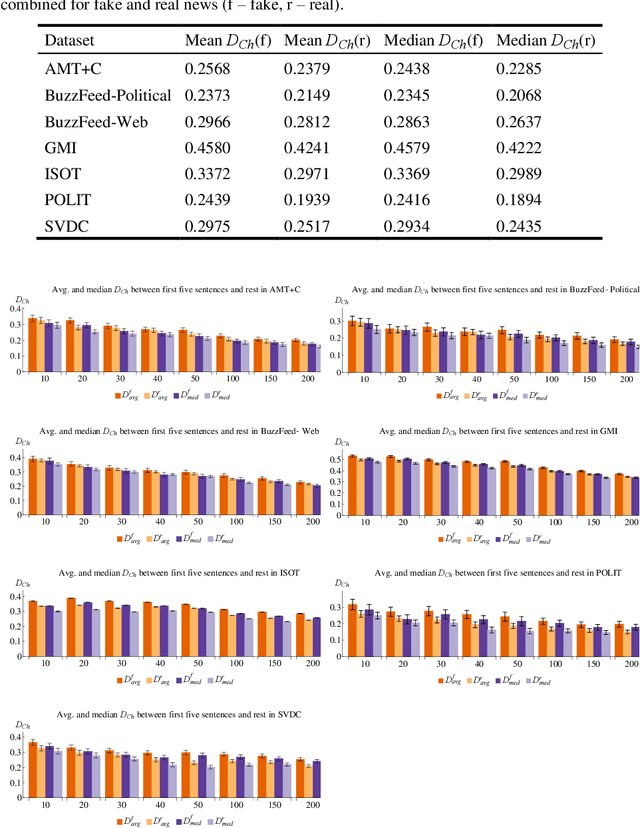
The spread of fake news remains a serious global issue; understanding and curtailing it is paramount. One way of differentiating between deceptive and truthful stories is by analyzing their coherence. This study explores the use of topic models to analyze the coherence of cross-domain news shared online. Experimental results on seven cross-domain datasets demonstrate that fake news shows a greater thematic deviation between its opening sentences and its remainder.
ReSCo-CC: Unsupervised Identification of Key Disinformation Sentences
Oct 21, 2020
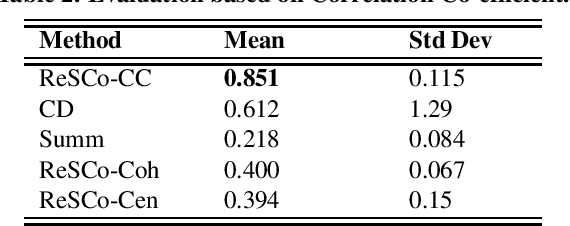
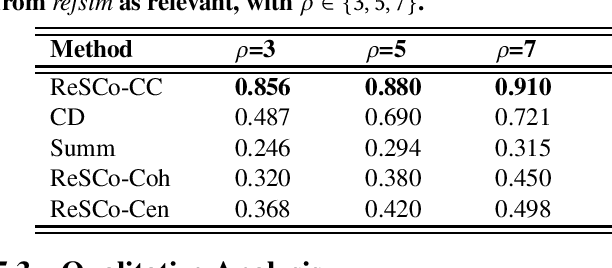

Disinformation is often presented in long textual articles, especially when it relates to domains such as health, often seen in relation to COVID-19. These articles are typically observed to have a number of trustworthy sentences among which core disinformation sentences are scattered. In this paper, we propose a novel unsupervised task of identifying sentences containing key disinformation within a document that is known to be untrustworthy. We design a three-phase statistical NLP solution for the task which starts with embedding sentences within a bespoke feature space designed for the task. Sentences represented using those features are then clustered, following which the key sentences are identified through proximity scoring. We also curate a new dataset with sentence level disinformation scorings to aid evaluation for this task; the dataset is being made publicly available to facilitate further research. Based on a comprehensive empirical evaluation against techniques from related tasks such as claim detection and summarization, as well as against simplified variants of our proposed approach, we illustrate that our method is able to identify core disinformation effectively.