 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Transparent Stance Detection: A Zero-Shot Approach Using Implicit and Explicit Interpretability
Nov 05, 2025Zero-Shot Stance Detection (ZSSD) identifies the attitude of the post toward unseen targets. Existing research using contrastive, meta-learning, or data augmentation suffers from generalizability issues or lack of coherence between text and target. Recent works leveraging large language models (LLMs) for ZSSD focus either on improving unseen target-specific knowledge or generating explanations for stance analysis. However, most of these works are limited by their over-reliance on explicit reasoning, provide coarse explanations that lack nuance, and do not explicitly model the reasoning process, making it difficult to interpret the model's predictions. To address these issues, in our study, we develop a novel interpretable ZSSD framework, IRIS. We provide an interpretable understanding of the attitude of the input towards the target implicitly based on sequences within the text (implicit rationales) and explicitly based on linguistic measures (explicit rationales). IRIS considers stance detection as an information retrieval ranking task, understanding the relevance of implicit rationales for different stances to guide the model towards correct predictions without requiring the ground-truth of rationales, thus providing inherent interpretability. In addition, explicit rationales based on communicative features help decode the emotional and cognitive dimensions of stance, offering an interpretable understanding of the author's attitude towards the given target. Extensive experiments on the benchmark datasets of VAST, EZ-STANCE, P-Stance, and RFD using 50%, 30%, and even 10% training data prove the generalizability of our model, benefiting from the proposed architecture and interpretable design.
A Review of the Role of Causality in Developing Trustworthy AI Systems
Feb 14, 2023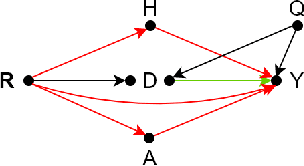
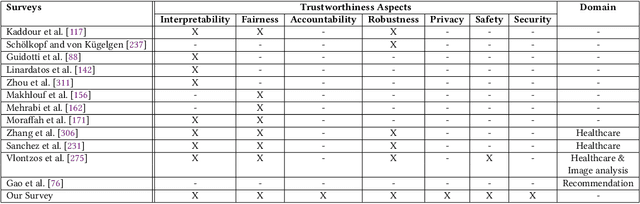
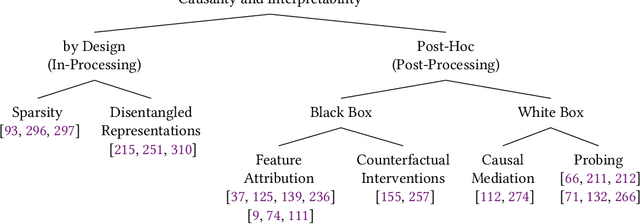
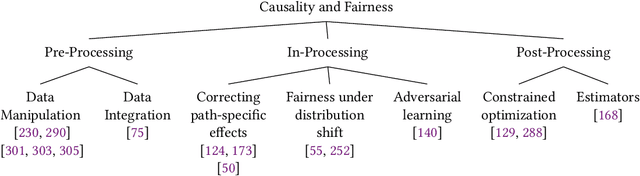
State-of-the-art AI models largely lack an understanding of the cause-effect relationship that governs human understanding of the real world. Consequently, these models do not generalize to unseen data, often produce unfair results, and are difficult to interpret. This has led to efforts to improve the trustworthiness aspects of AI models. Recently, causal modeling and inference methods have emerged as powerful tools. This review aims to provide the reader with an overview of causal methods that have been developed to improve the trustworthiness of AI models. We hope that our contribution will motivate future research on causality-based solutions for trustworthy AI.
Discrimination and Class Imbalance Aware Online Naive Bayes
Nov 09, 2022



Fairness-aware mining of massive data streams is a growing and challenging concern in the contemporary domain of machine learning. Many stream learning algorithms are used to replace humans at critical decision-making points e.g., hiring staff, assessing credit risk, etc. This calls for handling massive incoming information with minimum response delay while ensuring fair and high quality decisions. Recent discrimination-aware learning methods are optimized based on overall accuracy. However, the overall accuracy is biased in favor of the majority class; therefore, state-of-the-art methods mainly diminish discrimination by partially or completely ignoring the minority class. In this context, we propose a novel adaptation of Na\"ive Bayes to mitigate discrimination embedded in the streams while maintaining high predictive performance for both the majority and minority classes. Our proposed algorithm is simple, fast, and attains multi-objective optimization goals. To handle class imbalance and concept drifts, a dynamic instance weighting module is proposed, which gives more importance to recent instances and less importance to obsolete instances based on their membership in minority or majority class. We conducted experiments on a range of streaming and static datasets and deduced that our proposed methodology outperforms existing state-of-the-art fairness-aware methods in terms of both discrimination score and balanced accuracy.
A Multi-task Model for Sentiment Aided Stance Detection of Climate Change Tweets
Nov 07, 2022Climate change has become one of the biggest challenges of our time. Social media platforms such as Twitter play an important role in raising public awareness and spreading knowledge about the dangers of the current climate crisis. With the increasing number of campaigns and communication about climate change through social media, the information could create more awareness and reach the general public and policy makers. However, these Twitter communications lead to polarization of beliefs, opinion-dominated ideologies, and often a split into two communities of climate change deniers and believers. In this paper, we propose a framework that helps identify denier statements on Twitter and thus classifies the stance of the tweet into one of the two attitudes towards climate change (denier/believer). The sentimental aspects of Twitter data on climate change are deeply rooted in general public attitudes toward climate change. Therefore, our work focuses on learning two closely related tasks: Stance Detection and Sentiment Analysis of climate change tweets. We propose a multi-task framework that performs stance detection (primary task) and sentiment analysis (auxiliary task) simultaneously. The proposed model incorporates the feature-specific and shared-specific attention frameworks to fuse multiple features and learn the generalized features for both tasks. The experimental results show that the proposed framework increases the performance of the primary task, i.e., stance detection by benefiting from the auxiliary task, i.e., sentiment analysis compared to its uni-modal and single-task variants.
Why are NLP Models Fumbling at Elementary Math? A Survey of Deep Learning based Word Problem Solvers
May 31, 2022
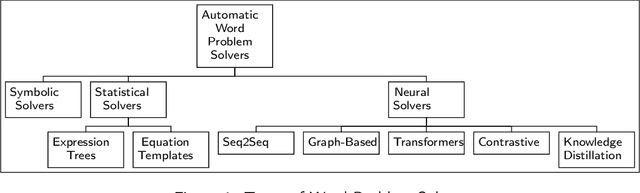

From the latter half of the last decade, there has been a growing interest in developing algorithms for automatically solving mathematical word problems (MWP). It is a challenging and unique task that demands blending surface level text pattern recognition with mathematical reasoning. In spite of extensive research, we are still miles away from building robust representations of elementary math word problems and effective solutions for the general task. In this paper, we critically examine the various models that have been developed for solving word problems, their pros and cons and the challenges ahead. In the last two years, a lot of deep learning models have recorded competing results on benchmark datasets, making a critical and conceptual analysis of literature highly useful at this juncture. We take a step back and analyse why, in spite of this abundance in scholarly interest, the predominantly used experiment and dataset designs continue to be a stumbling block. From the vantage point of having analyzed the literature closely, we also endeavour to provide a road-map for future math word problem research.
Robust Federated Learning Against Adversarial Attacks for Speech Emotion Recognition
Mar 09, 2022
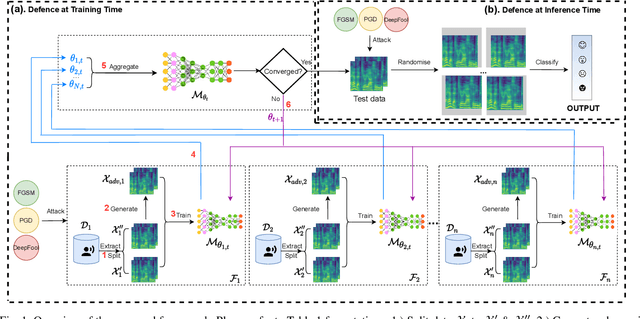

Due to the development of machine learning and speech processing, speech emotion recognition has been a popular research topic in recent years. However, the speech data cannot be protected when it is uploaded and processed on servers in the internet-of-things applications of speech emotion recognition. Furthermore, deep neural networks have proven to be vulnerable to human-indistinguishable adversarial perturbations. The adversarial attacks generated from the perturbations may result in deep neural networks wrongly predicting the emotional states. We propose a novel federated adversarial learning framework for protecting both data and deep neural networks. The proposed framework consists of i) federated learning for data privacy, and ii) adversarial training at the training stage and randomisation at the testing stage for model robustness. The experiments show that our proposed framework can effectively protect the speech data locally and improve the model robustness against a series of adversarial attacks.